PDF 문서의 실시간 텍스트 추출 방법: AWS S3 및 MCP 서버 활용
소개
현대의 다양한 업무에서 PDF 문서는 중요한 정보 전달 수단이지만, 특정 내용을 즉시 확인해야 하는 경우가 종종 발생합니다. 이번 글에서는 AWS S3에 저장된 PDF 문서의 텍스트를 실시간으로 추출할 수 있는 서버를 구축하는 방법을 소개합니다. 이 과정에서는 MCP 서버를 활용하여 문서를 프로그래머틱하게 처리하는 방법을 알아보고, 이 접근법과 Amazon Textract와의 비교를 통해 어떤 도구가 특정 작업에 적합한지 판단하는 데 도움을 드리고자 합니다.
본문
PDF 텍스트 추출 솔루션은 AWS S3에 저장된 문서에 대한 즉시 접근을 가능하게 합니다. 특히, 변호사, 컴플라이언스 담당자, 재무 분석가 등 다양한 분야에서 문서 검색을 자동화하여 시간을 절약할 수 있습니다. MCP(server-client-protocol) 기반의 서버를 설정하여 실시간으로 PDF 텍스트를 추출하고, 이 과정에서 간단한 문서 쿼리를 수행할 수 있습니다.
Amazon S3를 활용한 PDF 텍스트 추출 워크플로우 아키텍처 다이어그램
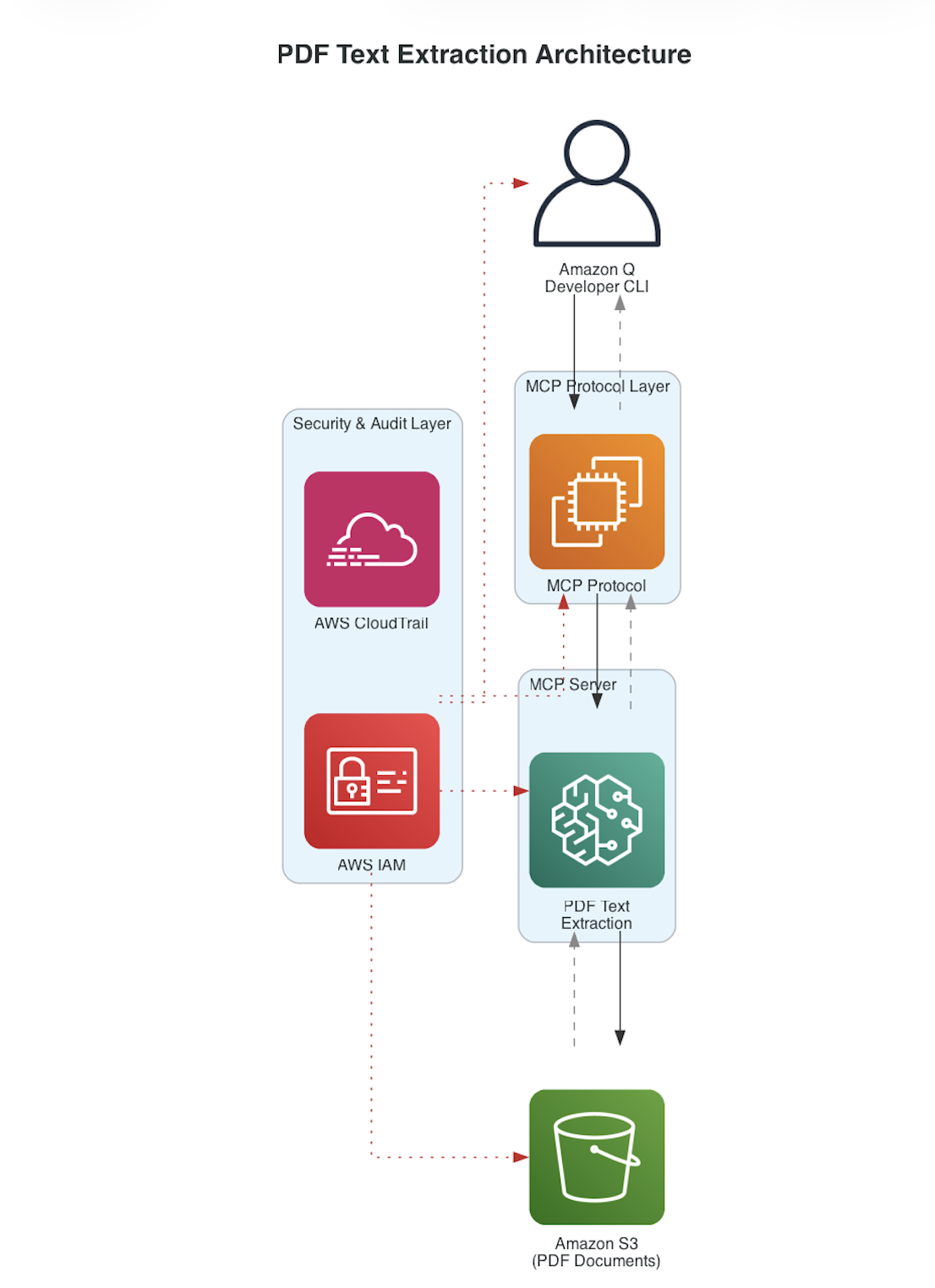
활용 사례
- 법률 서비스: 중견 법률 회사가 계약서 검토 과정에서 이 솔루션을 사용하여 고객과의 통화 중 실시간으로 조항을 검색하는 데 소요되는 시간을 크게 절감했습니다.
- 재무 컴플라이언스: 지역 은행의 감사 담당자들이 규제 문서를 실시간으로 확인할 수 있어 감사 과정의 효율성이 획기적으로 향상되었습니다.
- 기업 전략 회의: 기업의 고위 경영진들이 전략 회의 중에 분기 보고서에서 실시간 데이터를 즉시 확인할 수 있어, 논의를 즉시 데이터 기반으로 진행할 수 있습니다.
결론
MCP 기반의 PDF 텍스트 추출 서버는 직관적이고 인터랙티브한 도구로서, Amazon Textract와 상호보완적으로 사용할 수 있습니다. 주로 텍스트 기반 PDF를 실시간으로 읽어야 하는 경우에 적합하며, OCR이나 복잡한 문서 처리 기능이 필요할 때에는 Amazon Textract를 활용하는 것이 이상적입니다. 다음 단계로 MCP 서버 설치 가이드를 따라 실험 환경에서 테스트해 보신 후, Amazon Textract의 고급 기능도 적극 탐색해 보시기 바랍니다.
[1] https://aws.amazon.com/blogs/machine-learning/build-interactive-pdf-text-extraction-from-amazon-s3/
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
