서론
대형 언어 모델(LLM)은 정보 처리와 생성 방식을 혁신적으로 변화시켰지만, 여전히 여러 출처의 지식을 효과적으로 통합하는 데 어려움을 겪고 있습니다. 기존의 정보 검색 증강 생성(RAG) 방법은 도움을 주지만, 여러 문서의 정보를 연결해야 하는 다중 논리 추론 과제에서 종종 한계를 드러냅니다. 이러한 제한 사항을 해결하기 위해, 인간 두뇌의 해마 기억 시스템에 영감을 받은 히포RAG(HippoRAG)라는 새로운 RAG 프레임워크를 탐구하게 되었습니다.
본문
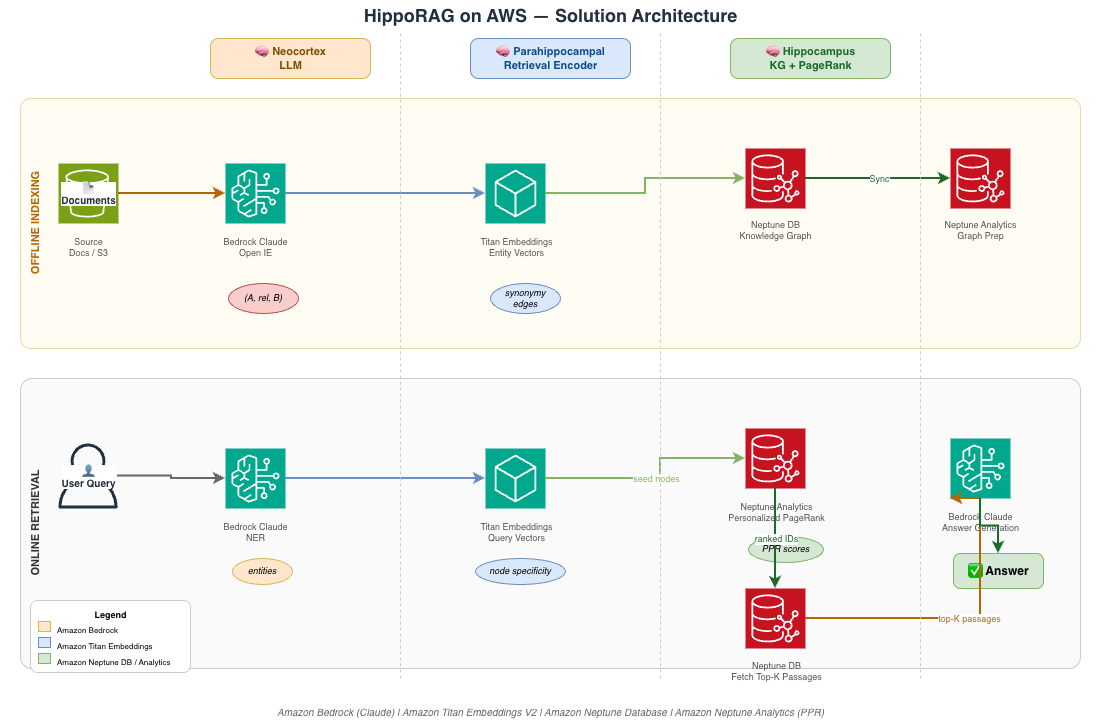
히포RAG는 AWS 스택을 활용하여 구현됩니다. 우리는 Amazon Bedrock을 LLM 기능에 활용하고, Amazon Neptune을 그래프 데이터베이스 기능에, 그리고 Personalized PageRank를 포함한 고급 그래프 알고리즘에는 Amazon Neptune Analytics를 사용합니다. 또한, Amazon Titan Embeddings을 텍스트의 벡터 표현에 활용하여 HippoRAG를 AWS 인프라 내에서 엔터프라이즈 규모 응용 프로그램에 배치할 수 있는 방법을 보여줍니다.
이러한 방식으로 실현된 HippoRAG는 여러 문서들을 단 번에 통합하고, 더 나아가 개인화된 PageRank 알고리즘을 활용한 그래프 탐색 및 연관 순위를 가능하게 합니다. 이것이 표준 RAG 접근법은 단일 문서를 독립적으로 처리하는 데 그치지만, HippoRAG는 효율적인 다중 논리 추론을 가능하게 합니다.
결론
이 블로그 포스트에서 다룬 HippoRAG는 다중 문서 기반 질문에 대한 효과적인 대안 솔루션을 제시합니다. Amazon Bedrock, Amazon Neptune, Amazon Neptune Analytics 및 Amazon Titan Embeddings와의 통합을 통해 강력하고 지능적인 솔루션을 구현할 수 있었으며, 이는 복잡한 다중 논리 추론 과제를 다루는 데 탁월합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
