아제르바이잔 언어 모델을 위한 아마존 세이지메이커 AI 활용 가이드
서론
오늘날 인공지능(AI)은 다양한 산업에서 활발히 활용되고 있습니다. 특히 언어 모델은 고객 서비스, 커뮤니케이션 도구 등에서 많은 주목을 받고 있습니다. 그러나 자원이 제한된 언어에서는 효율적인 모델을 훈련하는 것이 도전 과제입니다. 아제르바이잔의 선도적인 통신 공급자인 Azercell Telecom이 아마존 세이지메이커 AI를 사용하여 아제르바이잔 언어 모델(LLM)을 개발한 과정을 살펴보겠습니다. 이 포스트에서는 개발 방법론과 케이스를 소개하며, 이러한 기술들을 평가할 수 있는 기회를 제공합니다.
본문
아제르바이잔 토크나이저 개발
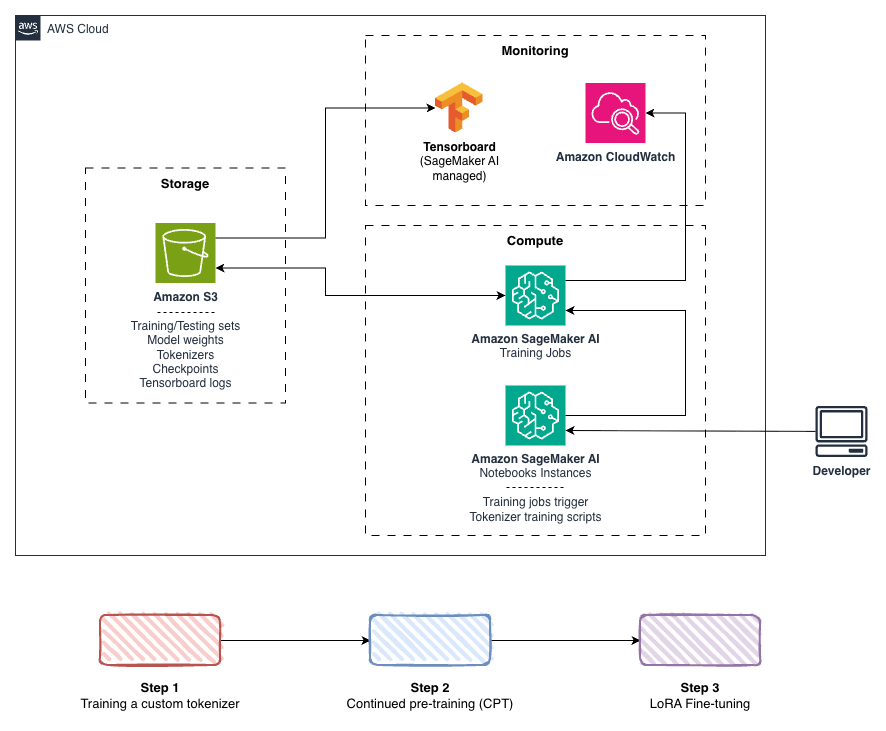
아제르바이잔어와 같은 문법적 복합 언어는 여러 개의 의미를 한 단어에 포함시켜 표현합니다. 기존의 영어 최적화 토크나이저는 이러한 구조를 효과적으로 처리하지 못합니다. 이를 개선하기 위해 아제르바이잔어에 맞춘 전문 토크나이저를 개발했으며, Byte-Level Byte-Pair Encoding(BBPE) 알고리즘을 활용하여 아제르바이잔어의 독특한 문자들을 완벽히 반영할 수 있었습니다. 다양한 어휘 크기를 실험한 결과 100k 토큰의 어휘가 가장 효과적임을 확인했습니다.
지속적 사전 학습과 Liger 커널 통합
아제르바이잔어 모델을 효과적으로 학습시키기 위해 Fully Sharded Data Parallel(FSDP) 및 Liger 커널 최적화를 통해 GPU 메모리 사용을 최적화했습니다. 이를 통해 동일한 하드웨어에서 대규모 배치 크기를 처리할 수 있으며, 훈련 처리량을 최대 23% 증가시켰습니다.
LoRA를 통한 지도 학습 미세 조정
사전 훈련된 모델을 대화형 보조로 변환하기 위해 Low-Rank Adaptation(LoRA) 방식을 사용했습니다. 이는 모델 파라미터 수를 크게 줄여 효율적으로 미세 조정을 가능하게 하며 모델의 대화 능력을 강화했습니다.
결론
Azercell과 AWS는 아마존 세이지메이커 AI 플랫폼을 통해 효과적인 아제르바이잔어 대화형 보조 시스템을 구축했습니다. 이 프로젝트는 모델의 토큰화에서부터, 지속적 사전 학습 및 미세 조정까지 체계적인 접근 방식을 따르며, GPU 활용을 극대화하는 기회를 제공했습니다. 이 가이드는 제한 자원 언어 또는 GPU 최적화를 추진하는 데 유용한 참조가 될 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
