도입부
기반 모델을 생성하는 AI 추론을 배포하고 확장하는 것은 많은 조직에 도전 과제가 됩니다. 복잡한 인프라 설정, 예측 불가능한 트래픽 패턴으로 인한 자원 과다 할당 또는 성능 병목 현상, 그리고 GPU 자원 관리의 운영적 부담은 AI 프로젝트가 대규모로 지속 가능성을 잃게 만들 수 있습니다. 이에 대한 해결책으로 Amazon SageMaker HyperPod가 있습니다. 이 글에서는 SageMaker HyperPod를 활용하여 이러한 문제를 어떻게 해결할 수 있는지, 인프라 자동화, 비용 최적화, 성능 개선을 통해 전체 소유 비용을 최대 40%까지 줄일 수 있는 방법을 설명합니다.
본문
Amazon SageMaker HyperPod는 추론 워크로드를 다루기 위한 포괄적인 플랫폼을 제공합니다. HyperPod의 역동적인 확장 능력, 간소화된 배포 과정, 지능적인 자원 관리 기능을 통해 AI 배포 과정을 효율적으로 관리할 수 있습니다.
-
클러스터 생성 및 배포 가이드
- 클러스터 생성: Amazon EKS 오케스트레이션을 통해 SageMaker HyperPod 클러스터를 생성할 수 있습니다. 사용자는 간단한 설치 옵션 또는 사용자 정의 옵션을 선택하여 특정 요구 사항에 맞게 설정을 조정할 수 있습니다.
- 배포 옵션: HyperPod는 Kubernetes의 유연성과 AWS 관리 서비스의 생산 신뢰도를 결합한 포괄적인 추론 플랫폼을 제공합니다.
-
자동 확장 및 성능 최적화
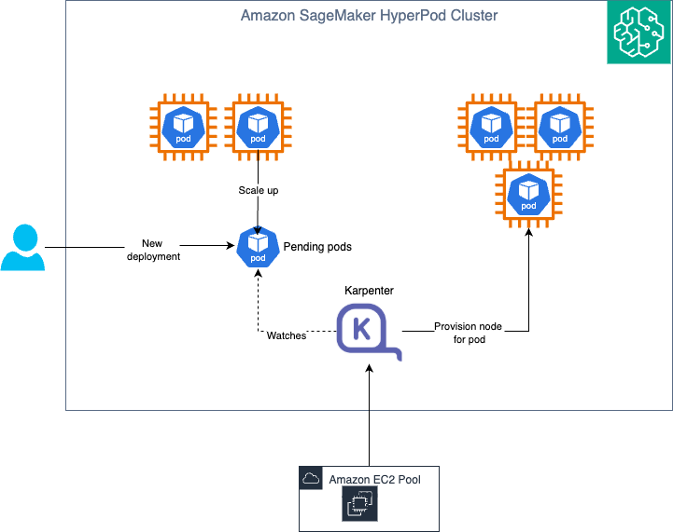
- 자동 확장: KEDA와 Karpenter를 결합하여 Pod 및 노드 수준에서 비용 효율적인 인프라 확장을 실현합니다. 이러한 이중 계층 구조로 인해 실시간 수요에 따라 인프라가 유연하게 확장됩니다.
-
효율성 및 비용 절감
- KV 캐싱 및 지능형 라우팅: 대형 언어 모델의 추론 성능을 최적화하기 위한 다중 계층 KV 캐싱 및 지능형 라우팅 기능을 제공합니다.
결론
Amazon SageMaker HyperPod는 기반 모델을 생성하는 AI 추론 워크로드를 처리하기 위한 강력하며 효율적인 인프라를 제공합니다. JumpStart, S3, FSx for Lustre 통합을 통한 원클릭 배포, 관리형 Karpenter 자동 확장, 동적 확장을 위한 통합 인프라를 사용하여 AI 배포를 가속화할 수 있습니다. 최적화를 통해 지연 시간 감소, 처리량 향상 및 비용 절감을 달성할 수 있으며, 이는 대규모 AI 환경에서 책임감 있고 효율적인 확장을 가능하게 합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
