소개
Amazon SageMaker AI는 복잡한 멀티턴 강화 학습(멀티턴 RL)을 제공하여 지능적인 에이전트가 연속적인 작업을 수행할 수 있게 합니다. 이 글에서는 SageMaker AI를 활용한 멀티턴 RL의 모범 사례와 구현 방법을 중심으로 살펴보겠습니다.
본문
멀티턴 RL에서는 단일 응답이 아니라 연속적인 종속 단계의 처리가 필요합니다. 에이전트는 도구를 호출하고, 결과를 읽고, 다음 행동을 결정하며 실수를 복구하는 등의 유연성을 제공합니다. 하지만 이러한 다양성은 강화 학습을 어렵게 만들기도 합니다.
푸시 버튼 자동화와 비교해 멀티턴 RL의 주요 이점은 복잡한 비즈니스 절차를 효과적으로 해결할 수 있다는 점입니다. SOP-Bench 데이터셋을 사용하여 복잡한 절차를 수행하는 에이전트를 훈련하고 평가하는 방법을 살펴보겠습니다.
멀티턴 RL 훈련을 이루기 위한 핵심 요소는 훈련 환경 구축, 외부 평가 설정, 보상 설계 등입니다. 각 요소가 어떻게 상호작용하며, 무엇을 주의해야 하는지에 대해서는 다음과 같이 요약할 수 있습니다:
- 훈련 환경 구축: 훈련 환경은 실제 운영 환경을 닮아야 합니다. 가상화된 환경에서의 안정적인 평가가 필요합니다.
- 외부 평가 설정: 보상 신호와 별도로 평가를 수행하여 훈련의 실제 성공 여부를 측정해야 합니다.
- 좋은 보상 설계: 보상은 구체적이며 실제 결과에 기반하여 설계되어야 합니다.
- 에이전트 관리: 다회차 시나리오에서 에이전트가 변화하는 모습과 각 회차의 측정을 관리해야 합니다.
아래는 SageMaker AI 멀티턴 RL의 아키텍처 개요입니다.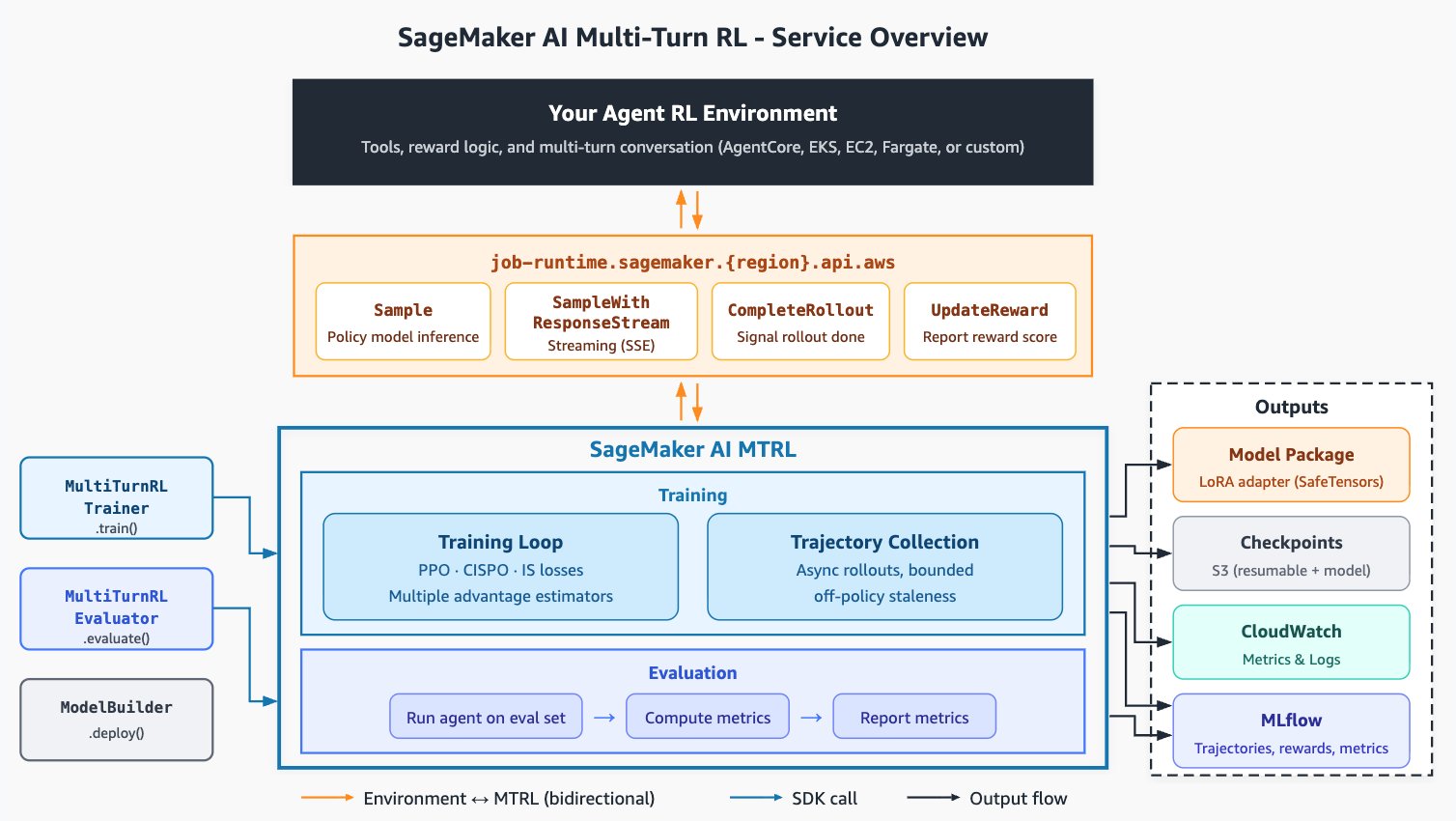
결론
SageMaker AI는 멀티턴 강화 학습을 효율적으로 수행할 수 있는 환경을 제공하며, 올바른 설계와 평가를 통해 훈련된 에이전트가 실제 작업에서도 높은 성과를 보일 수 있게 합니다. 올바른 보상 설계와 환경 구축은 성공적인 훈련의 핵심입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
