Amazon SageMaker AI에서 NVIDIA Blackwell을 활용한 모델 교육 최적화
최근 대형 AI 모델의 교육은 주로 GPU 메모리에 의해 제한되는 경우가 많습니다. 하지만 NVIDIA Blackwell GPU 아키텍처를 활용하면 이러한 제약을 극복할 수 있는데요, Amazon SageMaker AI에서 Blackwell GPU의 새롭고 확장된 메모리 및 정밀도 포맷을 어떻게 활용하여 훈련 작업을 최적화할 수 있는지 알아보겠습니다.
Blackwell 아키텍처 이해하기
Blackwell의 주요 특징은 이중 칩 구조와 향상된 텐서 코어입니다. 이 기술들은 GPU 간 통신 대역폭과 메모리 압력을 낮춤으로써 멀티 GPU 교육에서 이점을 제공합니다. 예를 들어, NVLink 5는 최대 1.8 TB/s의 대역폭을 제공하며, 확장된 HBM 용량은 대규모 배치 및 긴 시퀀스 길이를 지원합니다.
메모리 관리
Blackwell의 확장된 메모리는 더 큰 배치 크기와 간소화된 모델 샤딩을 가능하게 하며, 긴 시퀀스 길이를 수용할 수 있게 도와줍니다. 이러한 기능을 활용하면 GPU 간의 동기화 단계를 줄이고 전반적인 처리 속도를 높일 수 있습니다. 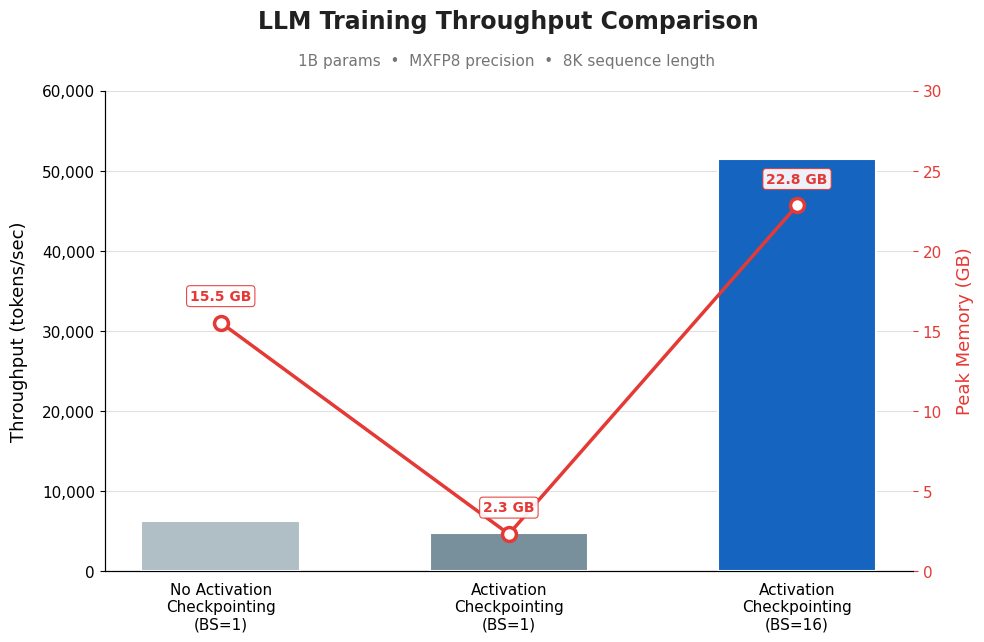
정밀도 포맷 선택
Blackwell은 FP8, MXFP8, NVFP4와 같은 저정밀도 포맷을 지원하여 처리량을 최적화합니다. 이러한 포맷은 메모리 대역폭 요구를 줄이고 GPU의 작업 속도를 향상시키지만, 모든 상황에서 메모리 절약에는 기여하지 않습니다. 모델 크기 및 워크로드에 따라 적절한 정밀도 포맷을 선택하는 것이 중요합니다.
Amazon SageMaker AI에서의 배포 가이드
Amazon SageMaker AI는 Blackwell 인스턴스를 활용하여 분산 교육 환경을 제공합니다. 자세한 설정 및 시작 방법은 SageMaker 문서에서 확인할 수 있습니다. ML 모델을 대규모로 교육하여 인프라보다는 데이터와 알고리즘에 집중할 수 있는 환경을 제공합니다.
결론
이번 포스트에서는 NVIDIA Blackwell GPU를 활용하여 Amazon SageMaker AI에서 AI 모델 교육을 최적화하는 방법을 살펴보았습니다. 각 워크로드의 특성에 맞춰 메모리 관리, 정밀도 포맷 선택, 활성화 체크포인팅 등을 통해 최적의 결과를 얻을 수 있습니다. 이제 준비가 되셨다면, SageMaker AI 문서를 탐색하여 Blackwell 활용에 대해 더 알아보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
