도입부
Amazon SageMaker AI의 최신 기술 진보로, 개발자와 기업은 새로운 컨테이너 캐싱 기능을 활용하여 모델 스케일링 속도를 두 배로 개선할 수 있게 되었습니다. 이번 기사에서는 컨테이너 캐싱이 어떻게 인스턴스를 새로 시작할 때 이미지 다운로드 병목현상을 해결하고, 성능 개선을 이루는지에 대해 알아보겠습니다.
본문
Amazon SageMaker AI는 인공지능 모델 스케일링에서 발생하는 지연 요소들을 줄이기 위해 다방면으로 최적화를 진행해 왔습니다. 그 중 가장 주목할 만한 것은 인스턴스 스토어 기반의 캐싱과 컨테이너 이미지 캐싱인데, 이들 기능은 기존 인스턴스를 재사용해 스케일링 지연 시간을 단축합니다. 이제는 새로운 인스턴스를 시작할 때에도 이러한 속도 개선 효과를 볼 수 있습니다.
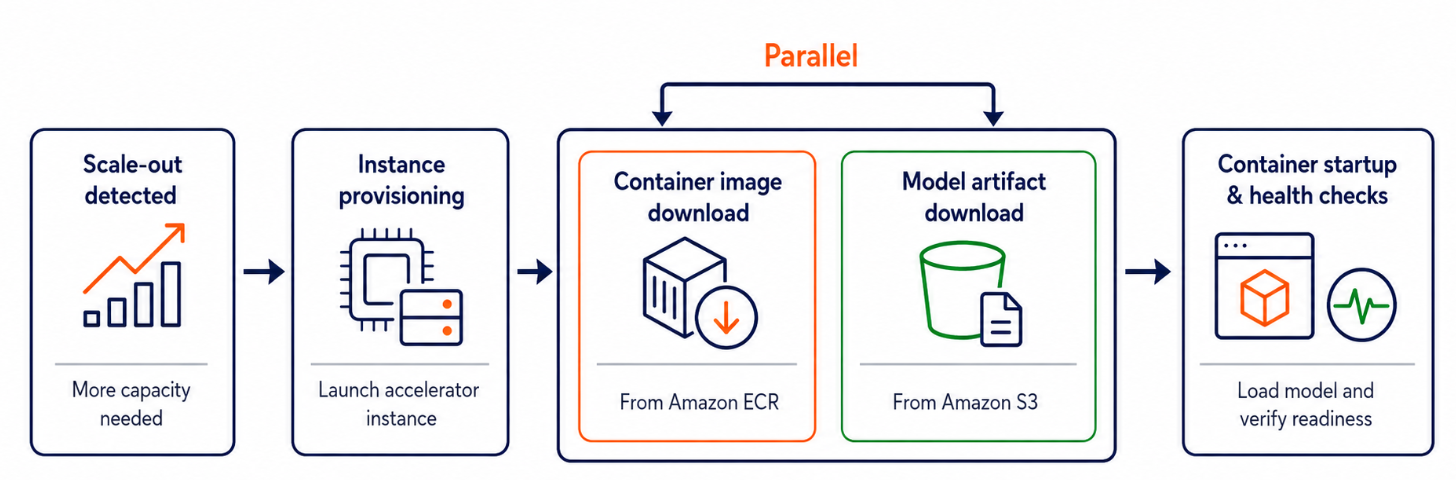
컨테이너 캐싱은 인퍼런스 컴포넌트에도 적용되어 스케일링 시 병목 현상을 없앱니다. 특히, 고성능 인스턴스에서 인공지능 모델을 다수 배포할 경우, 캐싱으로 인해 컨테이너 이미지 다운로드 시간을 크게 줄일 수 있습니다. 이러한 최적화로 인해 고객들은 컨테이너 이미지 다운로드 시 평균 51%의 시간 단축을 경험할 수 있습니다.
결론
컨테이너 캐싱은 Amazon SageMaker AI의 스케일링 효율성을 새로운 수준으로 끌어올렸습니다.이는 특히 급격한 트래픽 증가에도 낮은 대기 시간과 높은 가용성을 유지해야 하는 인공지능 어플리케이션에 있어 중요합니다. 현재 SageMaker AI의 지원을 받는 모든 리전에 이 기능이 구현되어 있으며, 간단한 설정으로 자동 활성화가 가능합니다.
참고 문서와 링크
Amazon SageMaker AI에 관한 더 많은 정보와 컨테이너 캐싱에 대한 자세한 설명은 다음 링크에서 확인하실 수 있습니다. Amazon SageMaker AI 컨테이너 캐싱 소개
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
