대규모 언어 모델(LLM) 최적화의 새로운 접근
최근 AWS에서 대규모 언어 모델(LLM)의 로드를 가속화하고 컨텍스트 창을 확장하는 방법이 새롭게 주목받고 있습니다. 특히 Amazon FSx for Lustre와 NVIDIA의 GPUDirect Storage를 활용한 방법이 주목을 받고 있습니다. 이 블로그에서는 이러한 기술을 활용해 모델 로드 시간을 효과적으로 단축하고, 인퍼런스 성능을 극대화하는 방법을 소개하고자 합니다.
Amazon FSx for Lustre와 GPUDirect Storage의 활용
Amazon FSx for Lustre는 대용량 병렬 파일 시스템으로, GPUDirect Storage와 결합하여 CPU 메모리의 병목 현상을 제거하면서 GPU로 직접 데이터를 전송할 수 있습니다. 이로 인해, 복잡한 모델 로딩 과정을 거치더라도 몇 분이 아닌 몇 초 만에 로드가 가능해집니다. 예를 들어, Llama 3.1 405B 모델을 기준으로 볼 때, 약 20분의 로드 시간이 GPUDirect Storage를 통해 6초로 단축될 수 있습니다.
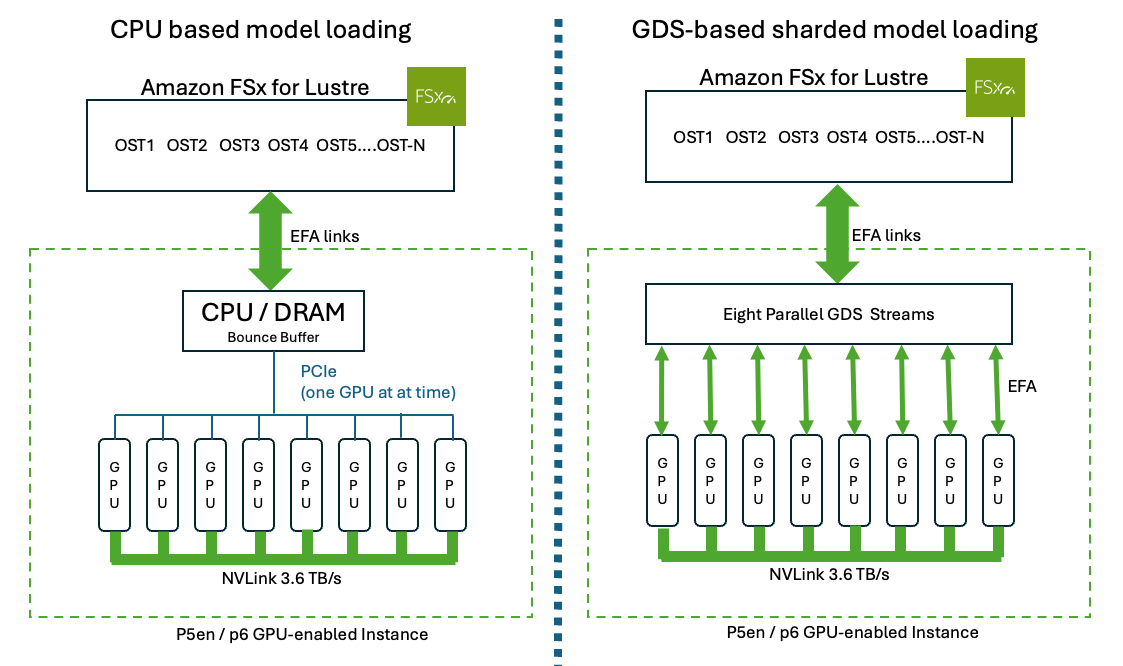
GPU로 직접 데이터 전송: GPUDirect Storage는 데이터가 CPU 메모리를 거치지 않고 직접 GPU로 전송되는 경로를 제공합니다. 이를 통해, CPU에서 생산되는 부하가 줄어들고, 전송 속도가 획기적으로 증가합니다.
대규모 데이터 처리의 병렬성 극대화: 모델의 파라미터가 수천억 개에 달하는 경우, 이런 병렬 데이터 전송 방식을 통해 시간과 비용 효율을 크게 높일 수 있습니다.
TurboQuant의 혁신적 컨텍스트 확장
모델 로딩의 최적화뿐만 아니라, KV 캐시 메모리를 혁신적으로 줄여주는 TurboQuant 기술도 주목받고 있습니다. 이 기술은 GPU 메모리 사용량을 줄이면서도 컨텍스트 창을 최대 5배까지 늘려줍니다. 이는 대규모 모델을 더욱 효과적으로 운영할 수 있는 길을 제공합니다.
결론
Amazon FSx for Lustre와 NVIDIA GPUDirect Storage의 결합은 대규모 언어 모델의 효율적인 운영에 필수적인 기술로 자리매김하고 있습니다. 이 기술들을 통해 모델 로드 시간을 혁신적으로 단축하고, 인퍼런스의 효율성을 높일 수 있습니다. 초대형 데이터 처리의 새로운 패러다임을 맞은 지금, 이러한 솔루션들은 필수적인 도구가 될 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
