소개
오늘날 강화 학습(기계 학습의 한 부분)은 향상된 모델 훈련 기법으로 주목받고 있습니다. 이 글에서는 특히 Amazon SageMaker에서 제공하는 Group Relative Policy Optimization(GRPO) 기법과 Verifiable Rewards를 사용하는 강화 학습 기법을 소개합니다. 이 기법을 통해 어떻게 학습 성능을 최적화하고 자동화할 수 있는지 알아보겠습니다.
본문
전통적인 강화 학습은 보상 신호의 신뢰성 문제로 인해 여러 가지 도전에 직면합니다. 보상 신호의 질은 모델의 학습 및 의사결정에 직접적인 영향을 줍니다. RLVR(Verifiable Reinforcement Learning)을 통해 이런 문제를 해결할 수 있으며, 특히 산출물을 객관적으로 검증할 수 있는 수학적 추론, 코드 생성 등에서 큰 효과를 볼 수 있습니다.
RLVR의 핵심 요점:
- 강화 학습의 핵심 개념: 모델이 상호작용을 통해 학습하며, 명확히 정의된 보상 신호에 따라 모델의 반응을 반복적으로 개선합니다.
- GRPO 알고리즘: AI 모델의 학습을 데이터 그룹 간의 성과 비교를 통해 개선시키며, 모델의 성능을 각 그룹의 기준에 맞게 최적화합니다.
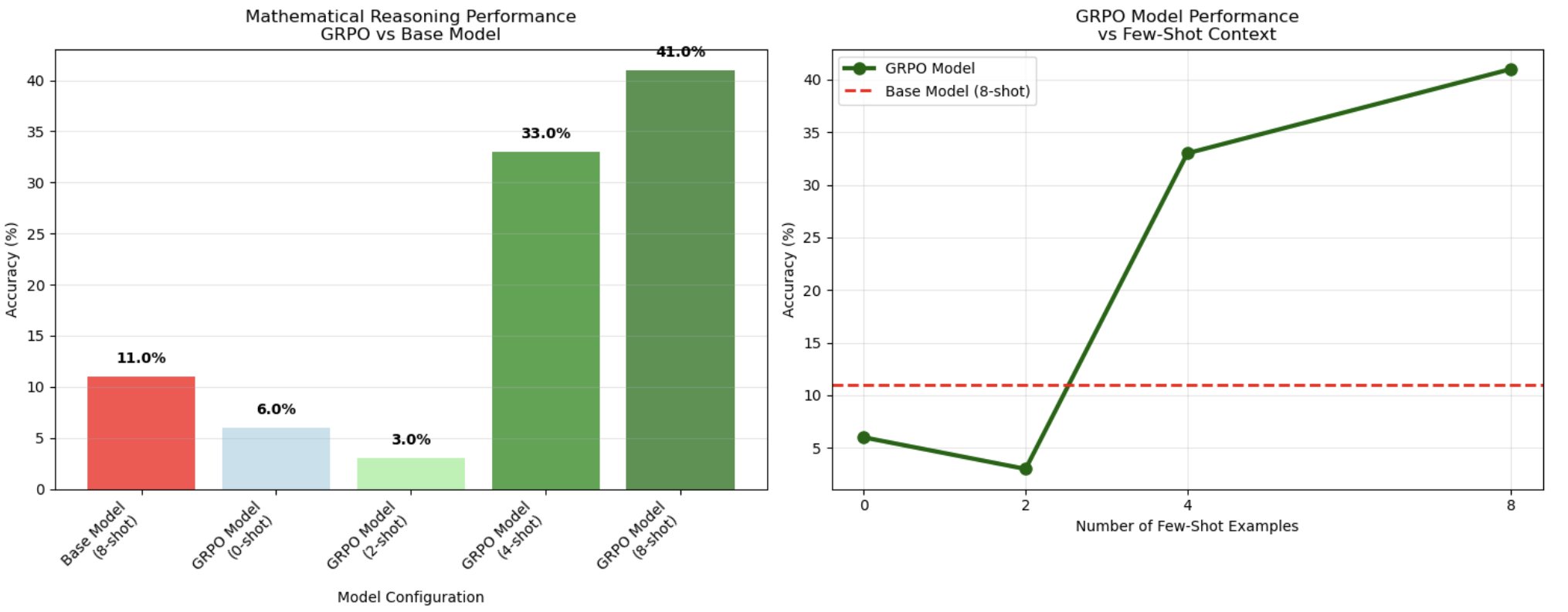
- 예시 및 결과: GSM8K 데이터셋을 활용하여 수학 문제 해결 정확도를 높이고, 모델을 실습을 통해 시험하며, 0-8 샷(0-8shot)의 다양한 접근법을 실험하여 유의미한 결과를 도출합니다.
결론
GRPO와 RLVR을 결합하여 Amazon SageMaker에서 초대량 데이터를 보다 효율적으로 처리하고, 마침내 시행착오적 접근이 아닌 검증 가능한 방법으로 강화 학습을 도입할 수 있게 합니다. 특히 수학적 추론, 코드 생성 등 다양한 분야에서의 확장이 가능하여, 폭넓게 활용할 수 있습니다.
[1] 원본 URL: AWS 블로그 원문
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
