도입
인공지능(AI) 기반 작업의 효율성을 높이기 위해 AWS에서는 다양한 기술들을 선보이고 있습니다. 그 중 하나가 ‘추측 디코딩(speculative decoding)’으로, AWS Trainium과 vLLM을 활용하여 해석이 무겁게 연속되는 작업을 가속화하는 기술입니다. 이번 블로그에서는 이 추측 디코딩의 원리와 활용 방법, 그리고 성능을 개선할 수 있는 가이드라인에 대해 알아보겠습니다.
본론
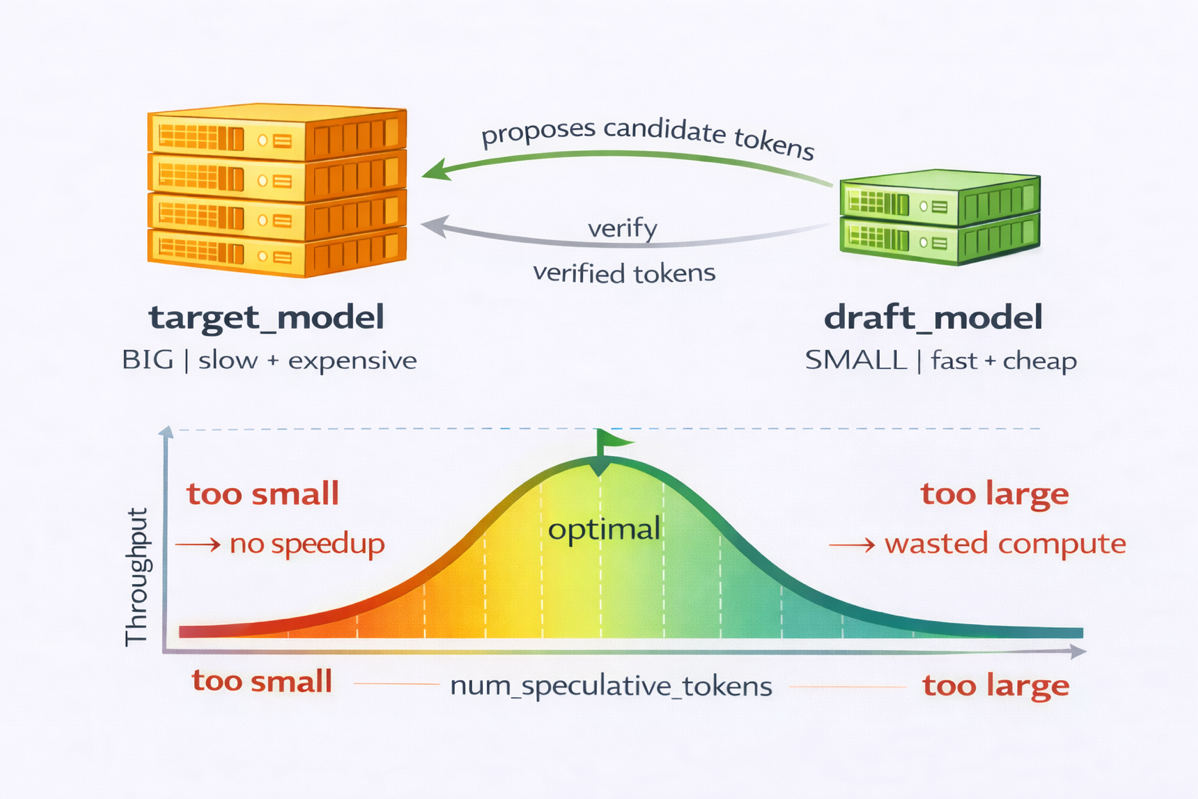
줄여서 ‘추측 디코딩’이라 불리는 이 기술은 오토레그레스 디코딩(autoregressive decoding)을 가속화하여 모델이 생성하는 토큰의 비용을 줄이고 처리량을 높이는 데 초점을 맞추고 있습니다. 이 기술은 두 가지 모델을 사용하여 이루어집니다. 먼저, 작은 초안 모델이 여러 개의 토큰 후보를 빠르게 제안하고, 이후 목표 모델이 이를 단 하나의 포워드 패스로 검증합니다. 이러한 방식을 통해 순차적인 디코딩 단계의 수를 줄여 레이턴시(latency)를 개선하며, 하드웨어 활용도를 높입니다.
추측 디코딩 활성화 방법:
- 먼저, AWS Trainium에서 spec_decode 명령어를 사용하여 vLLM과 결합합니다.
- 성능을 평가하기 위해 벤치마크 방법론을 활용하여 여러 가지 설정을 비교합니다.
- 모델 선택 및 추측 토큰 윈도우 크기를 조정하여 성능을 최적화할 수 있습니다.
추측 디코딩의 활용 사례:
- 코딩 에이전트, 구성 파일 및 템플릿 보고서 생성 등의 예측 가능한 결과를 만들어내는 작업
- 추측 디코딩을 통해 들로 인한 비용을 줄이고 처리량을 높이며, 결과물의 품질은 유지할 수 있습니다.
성능 비교
벤치마크 테스트 결과에 따르면, Qwen3 모델을 활용해 추측 디코딩을 적용했을 때 토큰 간 지연 시간이 크게 줄어들었습니다. 특히 구조가 잘 정의된 프롬프트에 대해 속도는 더욱 빠르게 구현됐으며, 이는 하드웨어 활용도를 최대화할 수 있었기 때문입니다. 그러나, 개방형 프롬프트에서는 추측 디코딩의 이점이 덜 두드러지며, 목표 모델과 초안 모델 간의 일치율이 낮아질 가능성이 있습니다.
결론
AWS Trainium을 통한 추측 디코딩은 디코딩 단계의 수를 줄여 출력 토큰당 비용을 줄이고 처리량을 높이는 데 효과적입니다. 특히 코드 생성이나 데이터 추출과 같이 예측 가능한 결과물을 생성하는 작업에서는 탁월한 성능을 보입니다. 그러나, 항상 효과적인 것은 아니며, 프롬프트 구조와 모델 품질에 따라 성능 차이를 보일 수 있습니다. 따라서, 여러분의 워크로드에 맞는 최적의 설정을 찾는 것이 중요합니다.
[1] 추가 정보
AI, Cloud 관련한 문의는 아래 연락처로 연락 주세요!
(주)에이클라우드
이메일: acloud@a-cloud.co.kr
회사 번호: 02-538-3988
회사 홈페이지: https://www.a-cloud.co.kr/
문의하기
