인공지능 워크플로우의 컨텍스트 강화 방법과 활용 사례
최근 인공지능 기술의 발전으로, AI 기반 연구 워크플로우에서의 과제는 컨텍스트와 깊이의 균형을 맞추는 일입니다. 연구 에이전트가 여러 웹 페이지를 읽을 때, 대형 언어 모델(LLM)이 동시에 처리할 수 있는 텍스트의 양이 제한되기 때문에 한계에 부딪히게 됩니다. 일반적으로 이러한 문제를 해결하기 위해 수동적인 프롬프트 체이닝이나 순차적 처리가 이용됩니다.
이에 대한 해결책으로, 종합적인 결과만 반환하는 독립적인 서브 에이전트에게 깊이 있는 작업을 위임하는 방법이 있습니다. 이러한 오케스트레이션을 담당하는 LangChain Deep Agents는 각 서브 에이전트를 스폰하고 그들의 생애 주기를 관리합니다. Amazon Bedrock AgentCore는 각 서브 에이전트가 필요한 인프라를 제공합니다. 여기에는 MicroVM(가벼운 단일 목적의 가상 머신) 내의 실제 브라우저와 데이터 분석을 위한 전체 Python 환경이 포함됩니다.
이 블로그에서는 이러한 패턴을 사용하여 종합적이고 경쟁력 있는 연구 에이전트를 구축하는 방법을 소개합니다. 이 과정은 여러 단계의 AI 워크플로우를 구축하고자 하는 개발자를 대상으로 하며, 에이전트에게 격리된 실행 환경이 필요할 때 유용합니다.
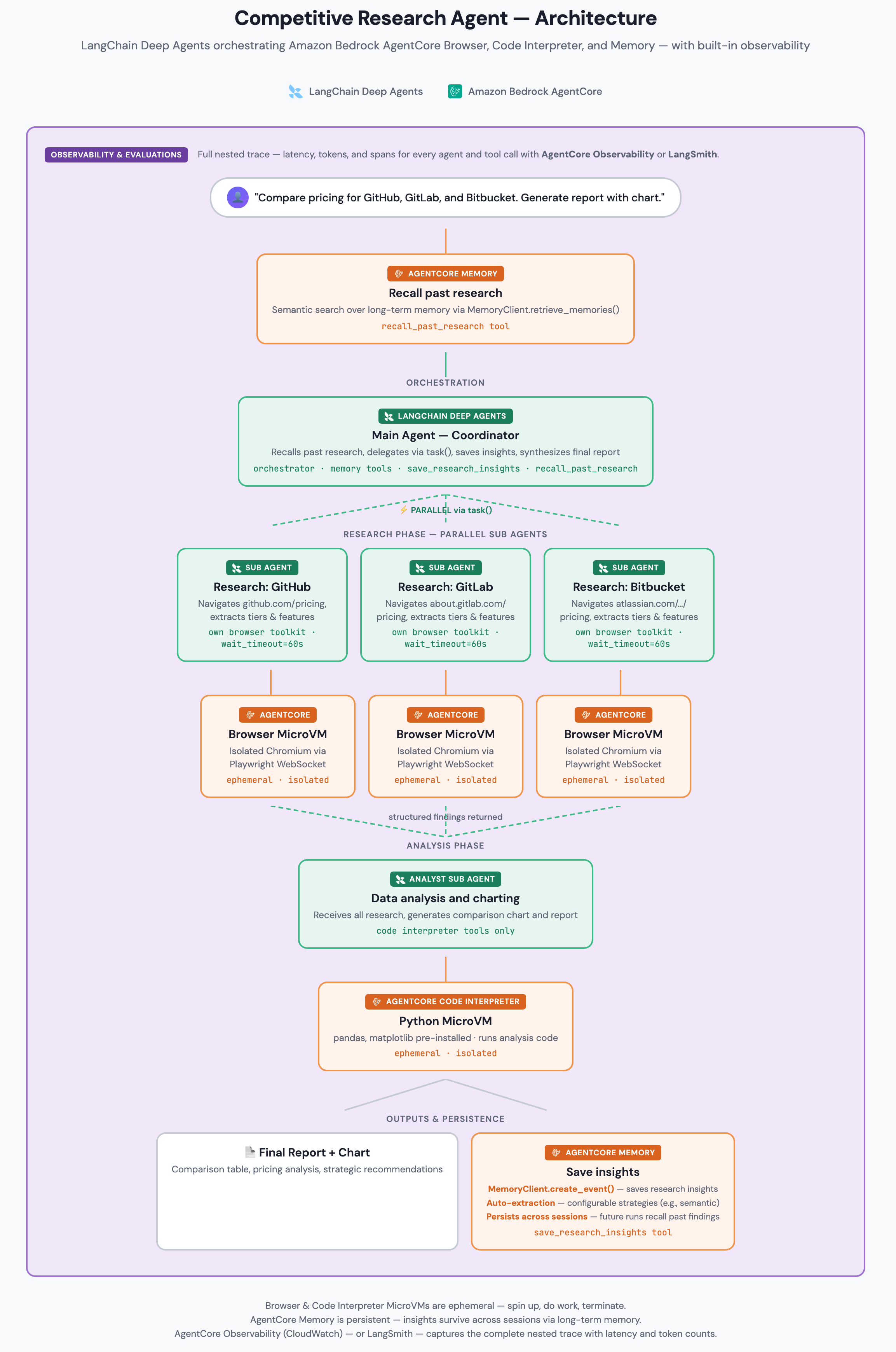
에이전트 구축 및 적용
에이전트를 구축하려면 우선 모델을 구성하고, 각 서브 에이전트 유형에 대한 툴킷을 생성하며, 이를 LangChain Deep Agents와 연결합니다. 먼저, AWS 계정에서 Amazon Bedrock AgentCore 액세스를 활성화하고, 필요한 IAM 권한을 설정해야 합니다. 또한 Python 3.11 이상을 설치하고 패키지 설치를 위해 pip 또는 uv를 사용해야 합니다.
세션 간 메모리를 활용하면 에이전트의 오랜 기간에 걸친 전문성을 구축할 수 있으며, Amazon Bedrock AgentCore의 관찰 가능성을 통해 CloudWatch를 사용하여 전체 워크플로우를 추적할 수 있습니다.
결론
이번 블로그 포스트에서는 LangChain Deep Agents와 Amazon Bedrock AgentCore를 활용해 컨텍스트가 풍부한 연구 에이전트를 구축하는 방법을 살펴보았습니다. 이러한 패턴은 경쟁 연구뿐만 아니라 다양한 워크플로우에도 적용할 수 있는 매우 유용한 접근 방식입니다. 더 많은 정보나 질문이 있다면 언제든지 댓글로 남겨주세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
