지능형 문서 처리 파이프라인 설계: Amazon Bedrock의 On-Demand 및 배치 추론
서론
현대의 기업들은 종이나 전자 문서에 숨겨진 비즈니스 인텔리전스를 활용할 수 있는 기술적 가능성을 갖췄으나 실제로 이를 효과적으로 이용하는 데에는 다양한 어려움이 있습니다. 특히 대량의 문서에서 유효한 데이터를 추출하는 과정은 까다롭습니다. 본 블로그에서는 Amazon Bedrock을 활용하여 온디맨드(inference) 추론과 배치(batch) 추론을 적용한 지능형 문서 처리 파이프라인 설계에 대해 알아봅니다. 이 솔루션은 문서 처리 시간과 비용에 유연성을 부여하여 기업의 비즈니스 운영을 효율화할 수 있는 길을 제시합니다.
본문
Amazon Bedrock의 On-Demand 및 배치 추론 활용
문서의 빠른 처리가 필요한 경우, Amazon Bedrock의 온디맨드 추론을 활용함으로써 신속하게 결과를 도출할 수 있습니다. 반면, 비용 최적화가 필요한 경우에는 배치 추론을 선택하여 많은 문서를 한 번에 처리할 수 있습니다. 이 과정은 Lambda함수와 SQS 메시지 큐, 그리고 Amazon DynamoDB 등 다양한 AWS 서비스를 활용하여 자동화된 문서 처리 시스템을 구축합니다.
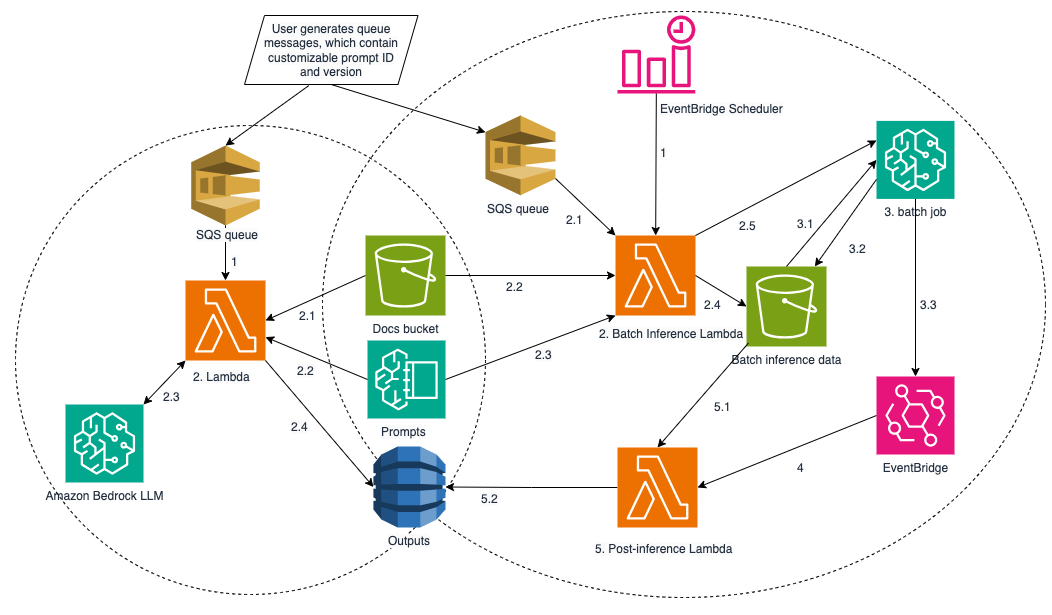
케이스 스터디: 계약 문서 처리 시스템
예를 들어, 수백만 건의 스캔된 PDF 형식의 토지 임대 계약 문서를 보유한 기업의 경우, 온디맨드 및 배치 추론을 통한 데이터 추출은 필수적입니다. Amazon Bedrock Prompt Management를 통해 각 문서의 형식에 맞는 프롬프트를 지정하여 데이터를 정밀하게 추출할 수 있습니다. 이러한 접근법은 문서의 타입에 따라 다양한 대화형 요청을 최적화하여 데이터의 일관성을 보장합니다.
자동화 프로세스의 구현
온디맨드 파이프라인에서는 SQS FIFO 큐가 사용되며, 메시지가 큐에 도착하면 Lambda 함수가 실행되어 데이터 추출을 진행합니다. 이 과정에서 문서는 이미지로 변환되고, 로직 기반의 Amazon Bedrock Prompt Management를 통해 해당 문서에 적합한 프롬프트가 호출됩니다. 결과는 DynamoDB에 저장되어 향후 비즈니스 분석에 활용됩니다.
배치 파이프라인에서는 EventBridge와 표준 SQS 큐를 사용하여 대량의 문서를 동시 처리합니다. 이때 일정 이벤트가 트리거되어 Lambda 함수가 큐의 메시지를 처리하고, 결과는 동일하게 DynamoDB에 저장됩니다.
결론
이와 같은 파이프라인은 대량의 문서에서 정보 추출을 효율화하며, 기업의 다양한 문서 처리 요구사항을 자동화합니다. 온디맨드 및 배치 처리의 효율적인 활용은 특히 시간 민감형 데이터와 대량의 데이터를 분리하여 관리할 수 있도록 도와줍니다. 이는 궁극적으로 데이터를 기반으로 한 더 나은 비즈니스 결정을 내리는 데 기여할 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
