Reinforcement Fine-Tuning과 LLM-as-a-Judge의 활용
인공지능 기술이 발전하면서, 대형 언어 모델(LLM)은 대화형 에이전트, 창작 도구, 및 의사결정 지원 시스템의 핵심이 되고 있습니다. 하지만 이러한 모델의 경우 종종 부정확한 정보, 정책 불일치 또는 비효율적인 표현을 포함하는 경우가 있으며, 이는 신뢰성을 저하시킬 수 있습니다. 이러한 문제를 해결하기 위해, 강화된 미세조정(RFT)은 효율적으로 준거 모델을 조율하기 위한 자동화된 보상 신호를 사용하며 주목받고 있습니다. 특히 Amazon Nova 모델을 활용한 RL with LLM-as-a-Judge(RLAIF)는 모델의 조율을 위한 강력한 방법입니다.
RFT와 LLM-as-a-Judge 비교
기존의 RFT 방식들은 간단한 수작업 규칙이나 숫자 매칭을 통한 보상을 사용하는 경향이 있습니다. 그러나 RLAIF는 모델 출력의 여러 차원을 고려하여 보다 유연하고 강력한 보상 시스템을 제공합니다. 이러한 방식은 특정 작업에 맞춤형 교육 없이도 맥락에 맞는 피드백을 제공하며, 비정형적인 상황에서도 탁월한 분석을 제공합니다.
LLM-as-a-Judge 구현 방법
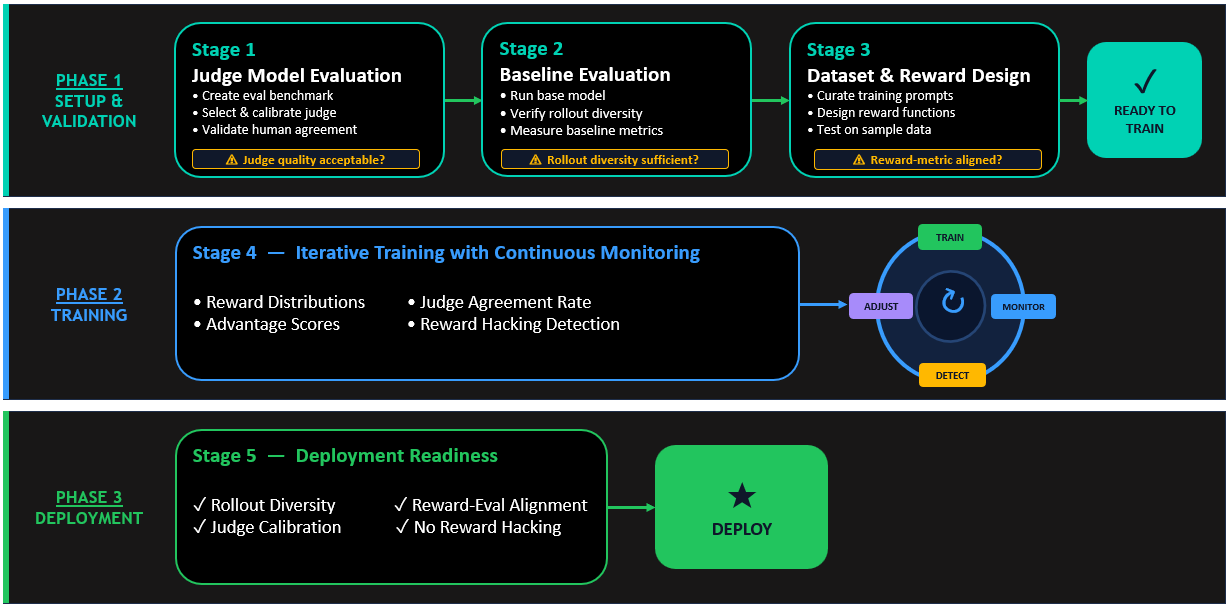
RLAIF 구현에는 다음의 여섯 가지 주요 단계가 포함됩니다:
- 심사 아키텍처 선택
- 평가 기준 설정
- 심사 모델 선택 및 구성
- 모델 프롬프트 정제
- 운영 평가 메트릭과의 정렬
- 안정적인 보상 Lambda 함수 구축
각 단계를 통해, LLM-as-a-Judge는 보다 정교한 심사 모델을 구축하고 이를 실제 운영과 조율하여 활용할 수 있습니다. 이러한 시스템은 Amazon Nova 모델과의 연결을 통해 실시간으로 피드백을 처리하며, 학습의 일관성을 보장합니다.
실제 사례: 법률 계약 검토의 자동화
법률 업계 파트너와의 협업을 통해, 법률 문서의 리스크 및 행동 권고 사항을 자동으로 생성하고 평가하는 작업을 진행했습니다. LLM-as-a-Judge를 사용하여, 원시 법률 문서 및 기준 문서를 기반으로 다중 주석을 생성하고 이를 평가하였습니다. 이 사례는 RFT 방법론을 사용해 목표하는 정확도를 달성한 예로, 실제 운영에서도 사용 가능성을 입증했습니다.
결론
Reinforcement Fine-Tuning과 LLM-as-a-Judge를 활용한 AI 모델 조율은 도메인 특화 애플리케이션에서 큰 잠재력을 가지고 있습니다. 이는 특히 법률, 금융, 의료 등 민감한 분야에서 중요한 의미를 가지며, 모델의 전반적인 성능과 신뢰성을 크게 향상시킬 수 있습니다.
[1] https://aws.amazon.com/blogs/machine-learning/reinforcement-fine-tuning-with-llm-as-a-judge/
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
