AWS Lambda의 서버리스 아키텍처는 아마존 노바 모델 맞춤화에 있어 효과적인 보상 함수를 구축하는 방법을 제시합니다. 서버 운영의 부담을 덜어주며, 효과적인 보상 함수를 통해 모델의 성능을 극대화할 수 있습니다.
AWS Lambda 기반 보상 함수는 특히 강화 학습을 통한 모델 맞춤화에서 두드러집니다. 일반적인 지도 학습이 많은 양의 라벨링된 데이터를 요구하는 반면, 강화 학습은 최종 출력에 대한 평가 신호를 통해 학습합니다. 보상 함수는 이 과정에서 모델이 보다 나은 반응을 학습하도록 유도하는 중요한 요소입니다.
또한, AWS Lambda를 활용하면 강화 학습을 통한 보상 함수의 확장성과 비용 효율성을 높일 수 있습니다. 고객 서비스와 같은 다양한 품질 요소를 동시에 충족해야 하는 경우, 강화 기반 접근법이 매우 유용합니다.
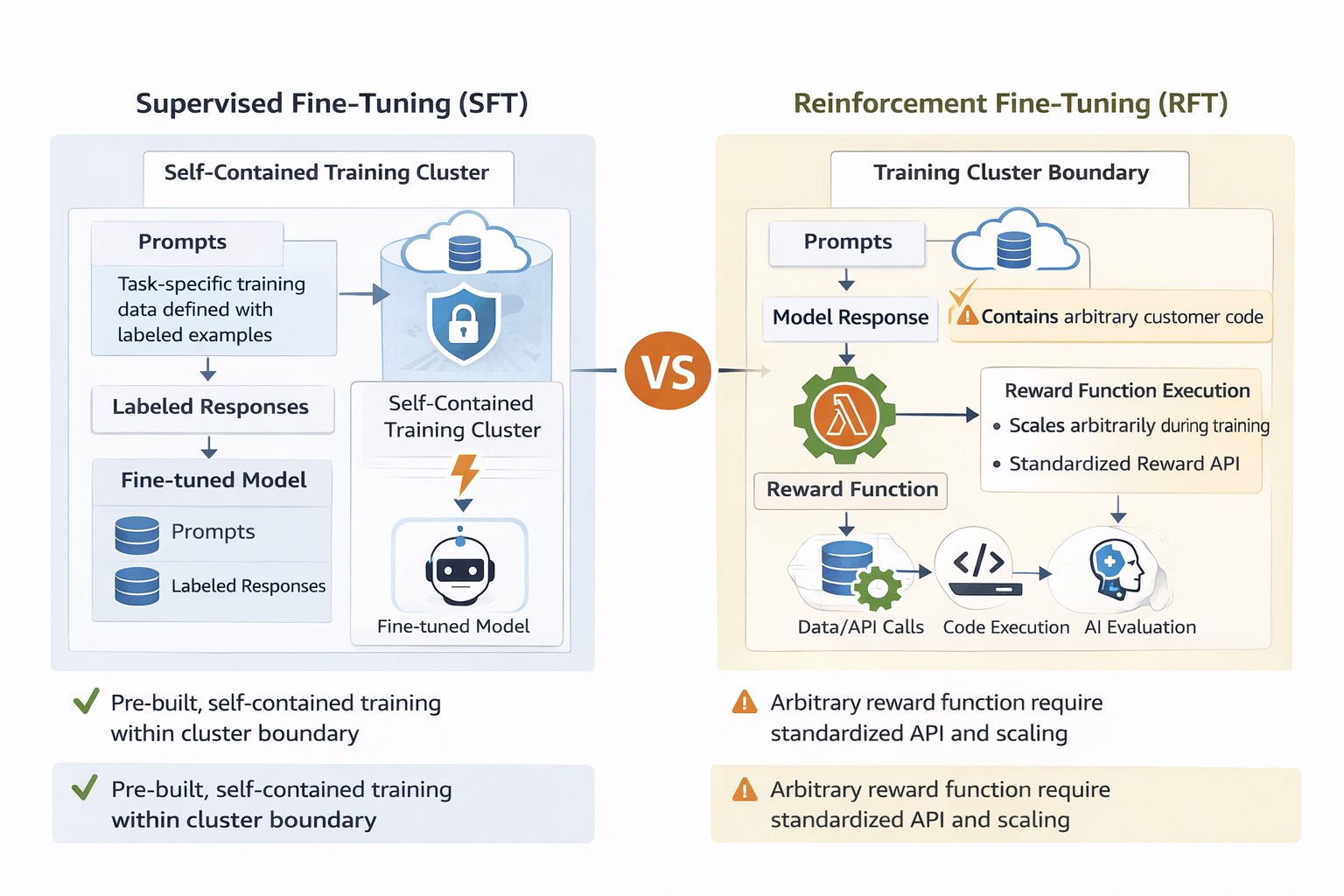
다양한 AWS 서비스와 통합된 아키텍처를 통해 손쉽게 모델을 커스터마이즈할 수 있습니다. 라벨이 없는 데이터에 대한 RLVR과 RLAIF 기술을 사용하여 정확한 평가를 수행할 수 있습니다. Lambda는 보상 평가 논리를 자동으로 확장하여 관리가 필요 없는 서버리스 환경을 제공합니다.
Lambda 기반의 보상 함수는 서버리스의 특성을 활용하여 확장성과 비용 효율성을 높이며, 조직이 쉽게 모델 맞춤화에 접근할 수 있도록 지원합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
