Amazon Bedrock의 멀티모달 모델로 비디오 인사이트 구현하기
현대 사회에서는 보안 감시, 미디어 제작, 소셜 플랫폼, 기업 통신에 이르기까지 비디오 콘텐츠가 폭넓게 사용되고 있습니다. 그러나 방대한 양의 비디오에서 의미 있는 인사이트를 추출하는 것은 큰 도전 과제입니다. 이러한 문제를 해결하기 위해 Amazon Bedrock의 멀티모달 모델이 어떻게 활용되고 있는지 살펴보겠습니다.
멀티모달 모델 기반 비디오 분석의 진화
전통적인 비디오 분석은 수작업 검토나 기본적인 컴퓨터 비전 기법에 의존했습니다. 그러나 이는 규모의 제약, 융통성의 제한, 복잡한 통합 등 여러 한계를 가지고 있습니다. Amazon Bedrock의 멀티모달 모델은 이러한 패러다임을 전환시키고, 시각 및 텍스트 정보를 함께 처리하여 비디오의 장면을 이해하고, 자연어 설명을 생성하며, 복잡한 이벤트를 감지할 수 있는 도약을 제공합니다.
세 가지 비디오 이해 접근 방식
비디오 이해는 시각적, 청각적, 시간적 정보를 결합하여 분석해야 하는 복잡한 작업입니다. 각기 다른 사용 사례와 비용-성능 균형을 고려한 세 가지 워크플로우를 제공하며, 각각은 고유의 비디오 추출 방법을 사용하여 특정 시나리오에 최적화되어 있습니다.
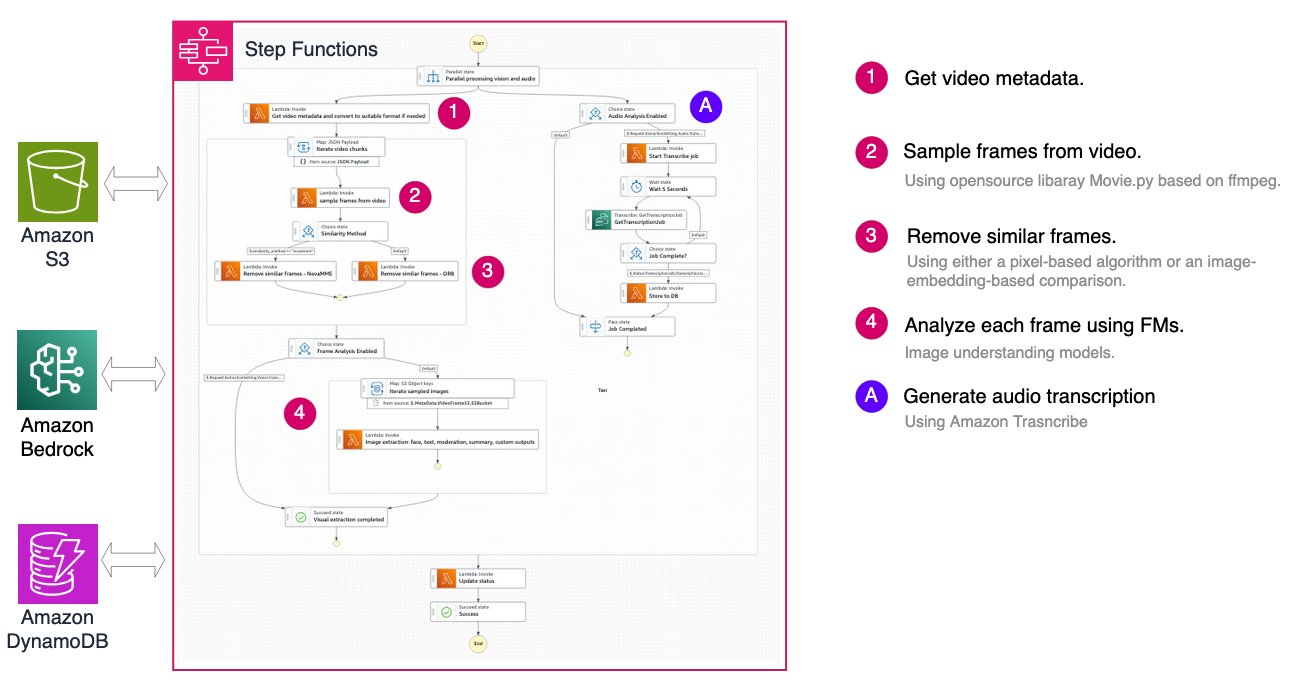
프레임 기반 워크플로우: 대규모에서의 정밀도
프레임 기반 접근 방식은 일정 간격으로 이미지 프레임을 선택하고 중복 프레임을 제거한 후 이미지 이해 모델을 사용하여 비주얼 정보를 추출합니다. 이 워크플로우는 보안 감시 및 제조 공정 모니터링 등 일정한 조건에서 큰 도움을 줍니다.
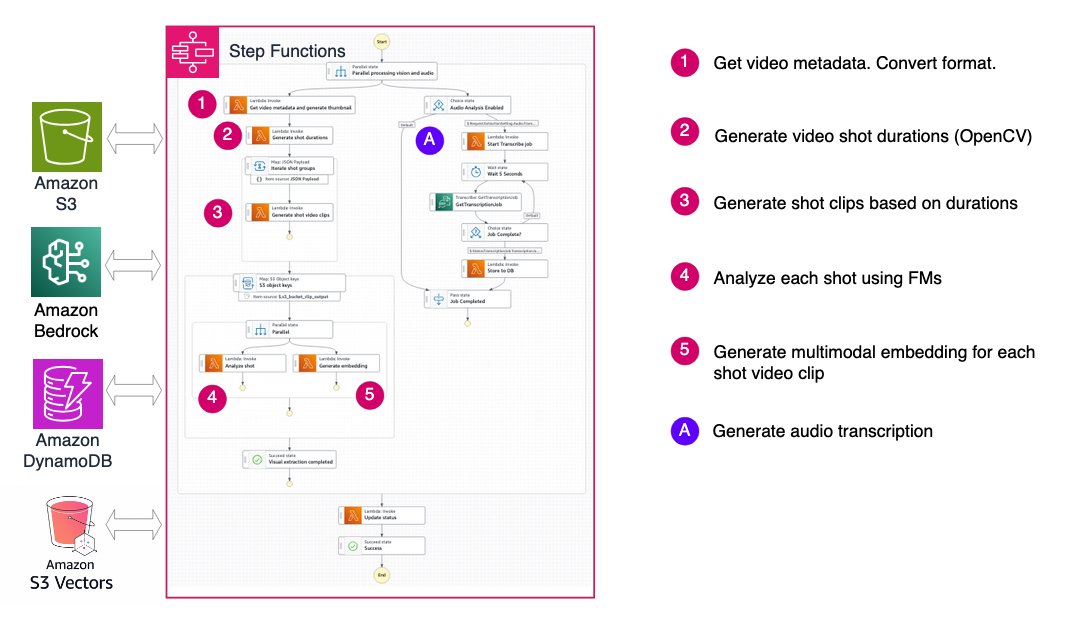
샷 기반 워크플로우: 이야기 흐름 이해
비디오를 샷이나 고정된 시간 단위로 분할하여 각 섹션에 대한 이해 모델을 적용함으로써 내러티브 흐름을 포착할 수 있습니다. 이는 미디어 제작에서 챕터 마커 분석, 콘텐츠 카탈로그화 등에 유용합니다.
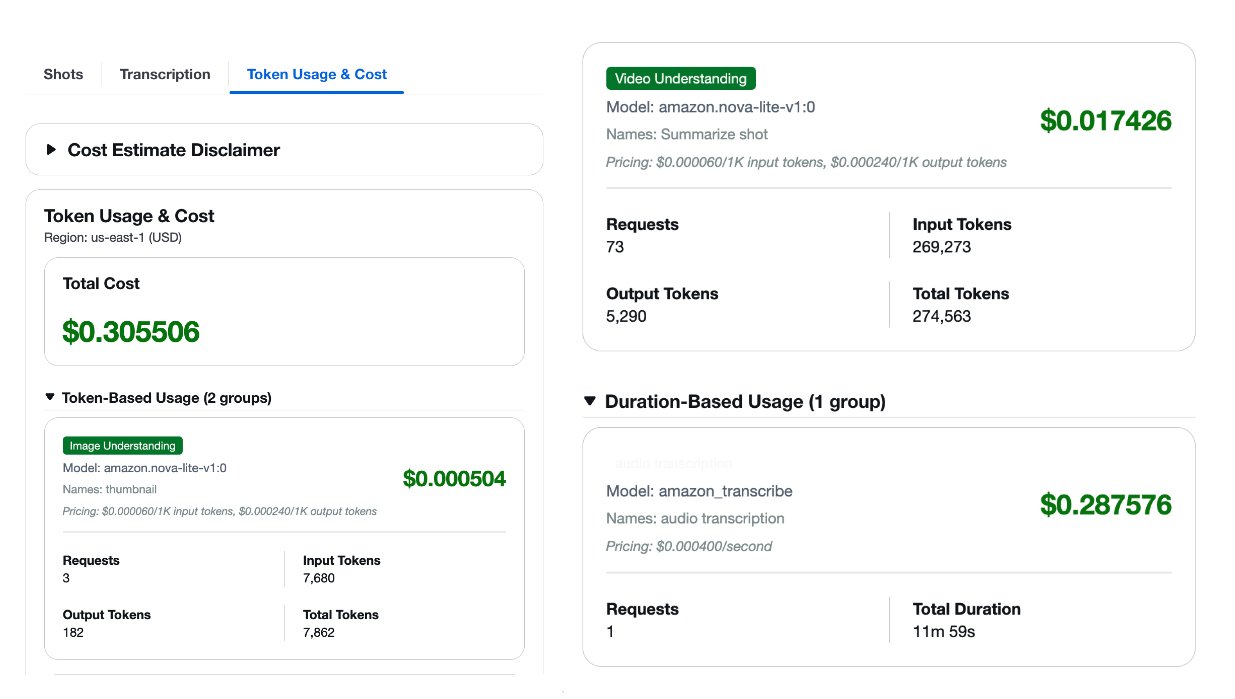
비용 및 성능 절충 관리
비디오 분석 솔루션에서는 비용과 품질을 동시에 관리하는 것이 중요합니다. Amazon Bedrock의 멀티모달 모델은 비용 예측 기능을 통해 모델 선택 및 워크플로우 구성에 있어 정보에 기반한 결정을 내릴 수 있도록 돕습니다.
결론
Amazon Bedrock의 멀티모달 모델과 AWS의 서버리스 서비스는 비디오 분석을 보다 안정적이고 비용 효율적으로 만듭니다. 보안 모니터링, 미디어 제작 도구, 콘텐츠 조정 플랫폼을 구축하는 데 있어 이 솔루션의 아키텍처 접근 방식을 활용할 수 있습니다. 각기 다른 요구 사항에 맞는 접근 방식을 선택하여 여러분의 사용 사례에 가장 적합한 해법을 찾아 인사이트를 빠르게 도출해 보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
