강화 학습 세부 조정에 대한 기술적 안내: Amazon Bedrock와 OpenAI 호환 API
서론
Amazon Bedrock에서 제공하는 강화 학습 세부 조정(Reinforcement Fine-Tuning, RFT)은 대규모 언어 모델(LLM)의 맞춤화를 혁신적으로 변화시키고 있습니다. 이 기술은 전통적인 지도학습 대신 피드백을 통한 학습을 선도하여, 모델이 다양한 상황에서 스스로 개선할 수 있도록 합니다. 본 글에서는 Amazon Bedrock과 OpenAI 호환 API를 사용한 RFT의 전체 워크플로우를 살펴봅니다.
본문
강화 학습 세부 조정(RFT)이란?
RFT는 대규모 모델이 정적 데이터가 아닌 피드백 루프를 통하여 학습하는 방식입니다. 이는 모델이 여러 가능한 응답에 대한 피드백을 받아 각각의 응답이 얼마나 잘 성과를 달성했는지 기준으로 학습하게 합니다. 이러한 접근은, 대규모 데이터를 사전에 준비하거나 라벨링할 필요 없이, 모델이 실시간으로 새로운 시나리오에 적응할 수 있도록 합니다.
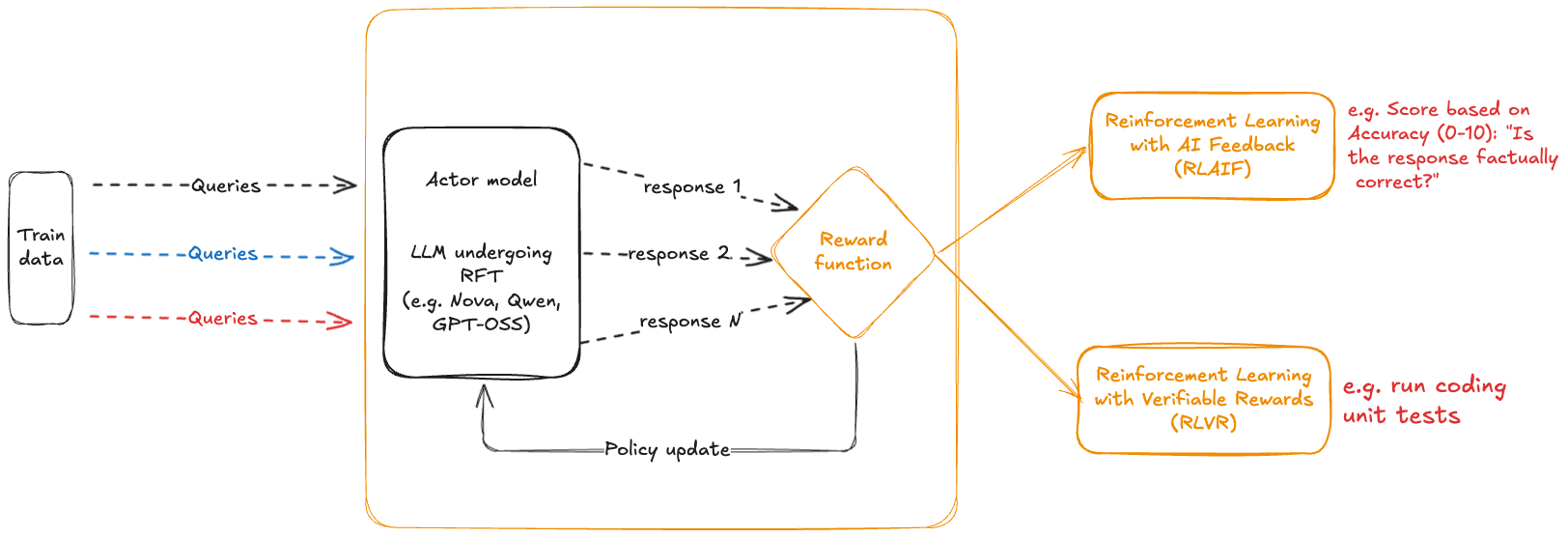
RFT의 핵심: 피드백을 통한 학습
강화 학습의 핵심은 에이전트가(여기서는 LLM) 피드백을 통해 더 나은 결정을 내릴 수 있도록 하는 것입니다. 예를 들어 체스 플레이어가 가능한 모든 수를 보여주는 대신 피드백을 제공하여 성공적인 위치로 이끄는 수를 알려주는 것과 같습니다. 이러한 과정을 통해 모델은 높은 성과를 내는 전략을 우선적으로 배울 수 있습니다.
Amazon Bedrock에서의 RFT 적용 사례
Amazon Bedrock의 RFT는 기업 수준의 실용성을 염두에 두고 설계되었습니다. 모든 RFT 파이프라인은 자동으로 실행되며, 사용자는 필요한 개발 환경에서 간단히 업로드한 후에, AWS Lambda를 통한 보상 함수 배포, fine-tuning 작업 생성 등을 수행합니다.
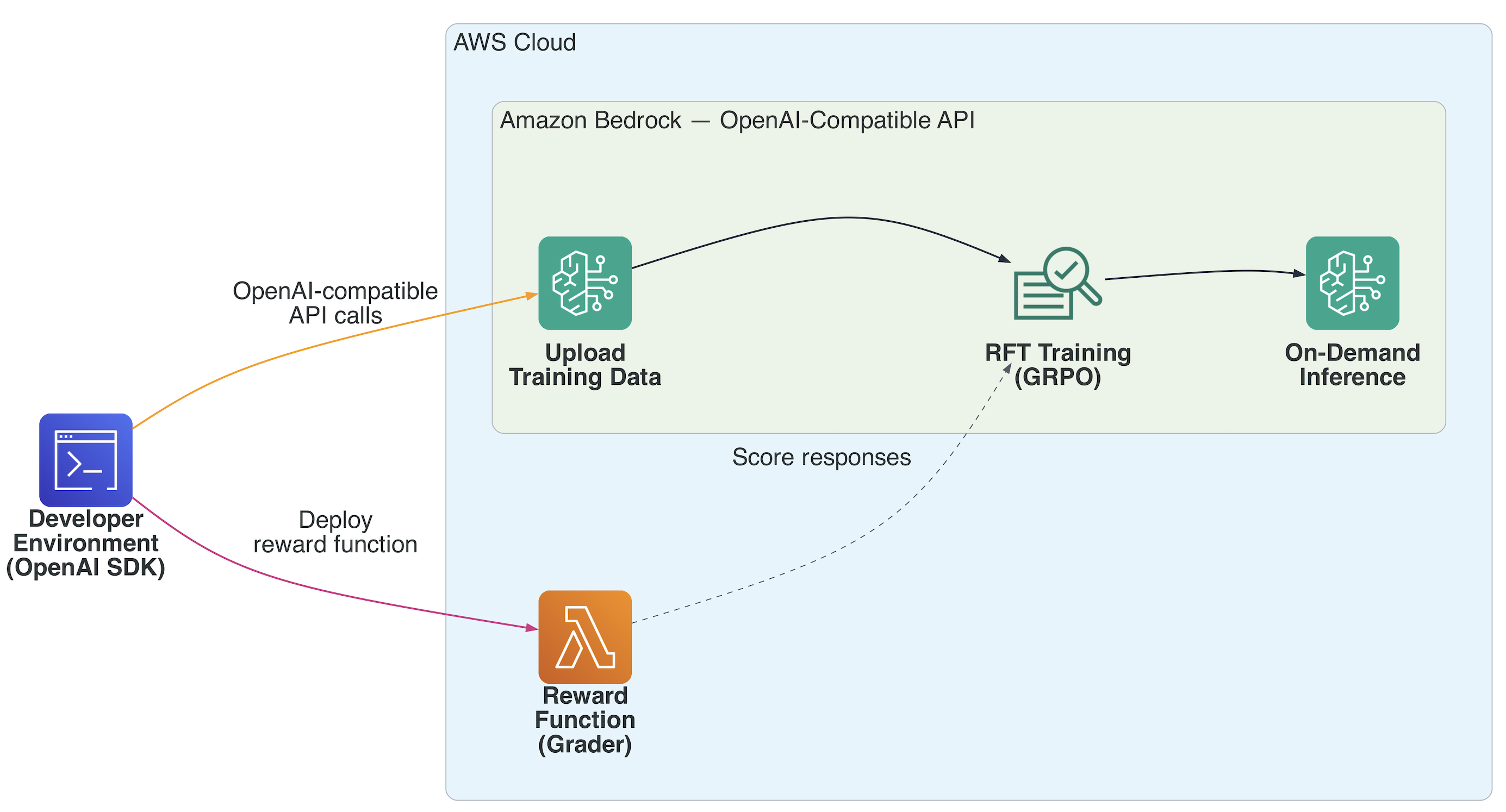
결론
Amazon Bedrock에서 강화 학습 세부 조정을 수행하면, 엔드 투 엔드 워크플로우가 다음과 같이 구성됩니다. OpenAI SDK와의 호환성, Lambda 기반 보상 기능, 및 주문형 추론 기능은 장기적으로 효율적이고 실용적인 맞춤형 워크플로우를 제공합니다. [1] 자세한 사항은 Amazon Bedrock 강화 학습 세부 조정 문서를 참조하세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
