인공지능 시대의 효율적인 추론 인프라: AWS에서의 Disaggregated Inference 도입
인공지능이 발전하고 대규모 언어 모델(LLM)의 사용이 증가하면서 효과적인 추론 인프라의 중요성이 커지고 있습니다. 특히, 대규모 AI 솔루션을 배포하는 과정에서는 추론 효율성이 중요한 요소로 작용합니다. AWS에서는 이러한 필요를 충족하기 위해 Disaggregated Inference를 도입하여 성능을 최대화하고 비용을 절감할 수 있는 방법을 제공합니다.
새로운 세대의 추론: Prefill과 Decode의 분리
LLM 추론은 주로 두 가지 단계로 나누어집니다: Prefill과 Decode 단계입니다. Prefill 단계는 컴퓨팅 파워가 집중되며, 초기 키-값(KV) 캐시 항목을 생성합니다. 반면, Decode 단계는 메모리 대역폭을 집중 사용하여 하나의 토큰을 생성합니다. 이러한 각각의 단계에서 요구되는 자원이 다르므로, 분리하여 처리함으로써 최적의 자원 활용이 가능합니다. 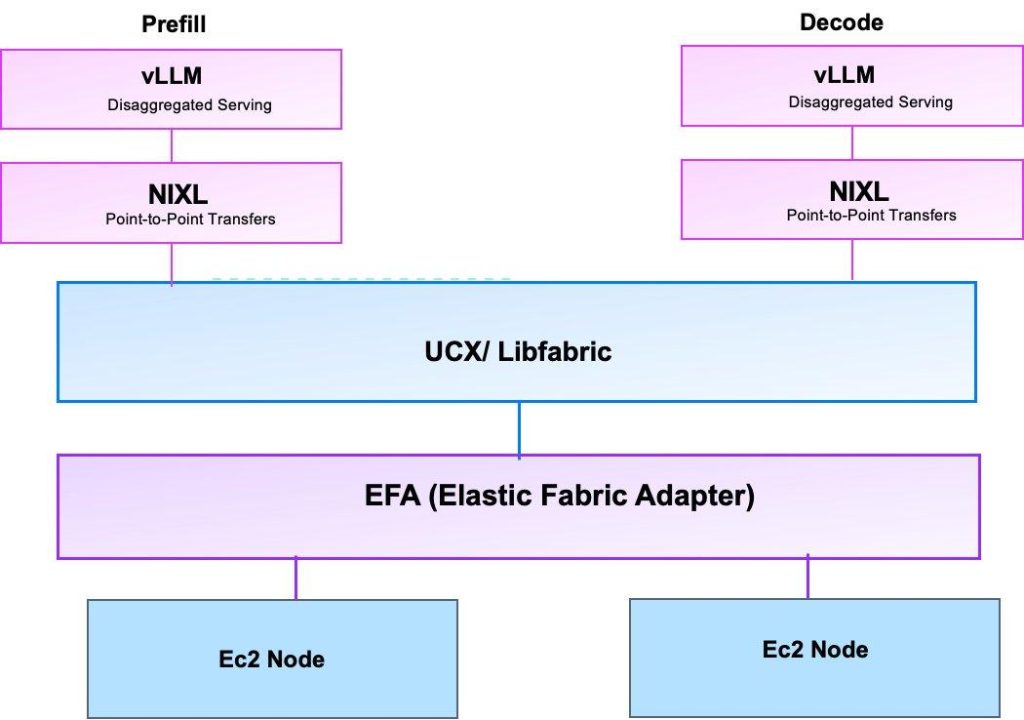
AWS에서의 Disaggregated Inference 구현 방법
AWS는 고객들이 대규모 추론 작업을 보다 효과적으로 처리할 수 있도록 새로운 기능들을 제공하고 있습니다. 아마존 Elastic Kubernetes Service(Amazon EKS)와 Amazon SageMaker HyperPod는 높은 성능의 클러스터를 제공하여 대규모 모델 추론을 지원합니다. 특히, llm-d 팀과의 협력으로 Disaggregated Inference를 제공함으로써 보다 지능적인 요청 스케줄링과 GPU 활용도를 극대화할 수 있습니다.
Disaggregated Inference의 실제 활용
llm-d는 대규모 언어 모델(LLM)을 분산 처리하기 위한 Kubernetes 기반 오픈 소스 프레임워크입니다. 기존의 단일 노드 문제를 넘어서 Prefill과 Decode, 그리고 KV 캐시 관리단계를 분리하여 보다 효율적인 활용이 가능합니다. 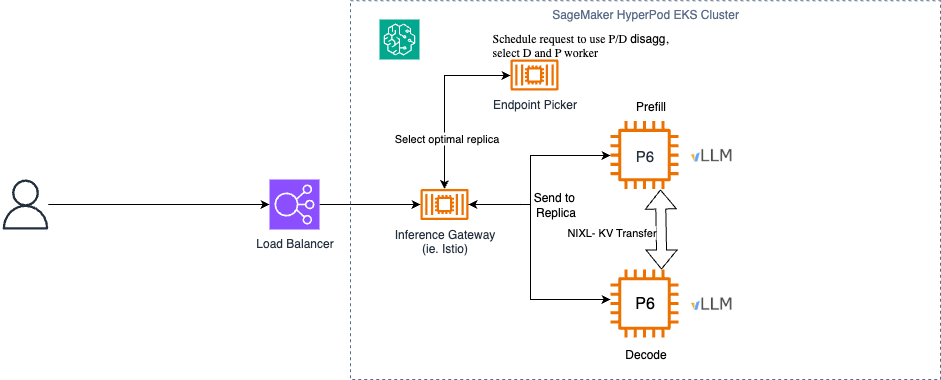
결론
Disaggregated Inference를 통한 AWS 인프라의 활용은 대규모 추론의 성능 개선과 비용 절감에 큰 기여를 합니다. 고성능의 추론 작업을 필요로 하는 현대의 인공지능 시대에서, llm-d와 같은 프레임워크는 이러한 요구에 부응하기 위해 탄생한 혁신적인 기술입니다. 이제 AWS 환경에서 다각적으로 접목하여 더 높은 수준의 AI 서비스를 제공할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
