강화 세부 조정: 데이터 기반 학습을 통한 AI 최적화의 새로운 패러다임
인공지능(AI) 모델의 기초적인 성능은 뛰어넘지만, 각 기업의 고유한 비즈니스 요구에 맞는 모델을 만들기 위해서는 맞춤화가 필요합니다. 여기서 강화 세부 조정(Reinforcement Fine-Tuning, RFT)이 등장하게 됩니다. 이 글에서는 아마존 노바(Amazon Nova) 모델에 대한 RFT를 통해 AI 모델을 최적화하는 방법과 그 활용 사례를 알아보고자 합니다.
강화 세부 조정의 핵심 원리
RFT는 모방 학습이 아닌 평가 기반 학습을 통해 모델을 커스터마이즈합니다. 모델이 탐색하며 스스로 솔루션 경로를 찾아가도록 하여 여러 다양한 솔루션 경로가 존재하는 실제 상황에 적합한 접근 방식을 제공합니다. 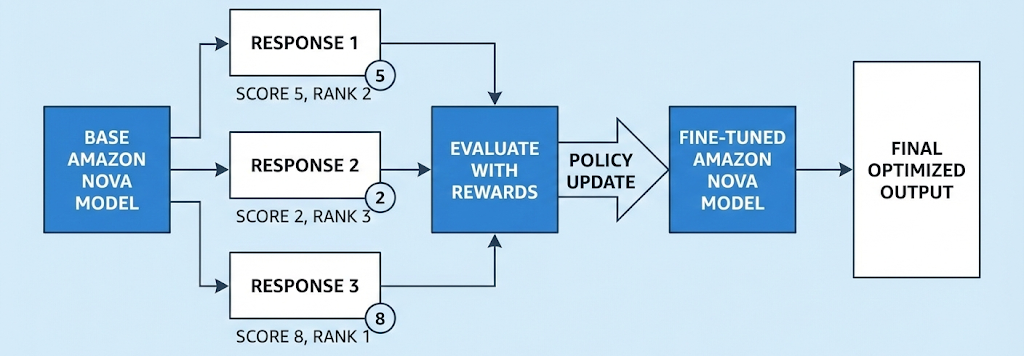
RFT의 주요 활용 사례
강화 세부 조정은 코드 생성, 고객 서비스, 콘텐츠 검토 등 다양한 분야에서 활용될 수 있습니다. 특히 복잡한 다중 단계 추론 작업이나 라벨링 데이터가 제한적인 상황에서 큰 이점을 제공하며, 모델이 학습할 수 있는 경로 다양성을 높여줍니다.
RFT의 구현 단계
- 데이터 준비 및 보상 함수 설계: 평가 기준을 기반으로 한 보상 함수를 설계하고, 이를 통해 모델의 응답을 평가합니다.
- 훈련 및 평가: Amazon SageMaker Training Jobs, SageMaker HyperPod, Nova Forge와 같은 다양한 인프라 옵션을 통해 모델 훈련과 평가를 진행할 수 있습니다.
- 결과 모니터링 및 반복: Amazon CloudWatch를 통해 훈련 중인 모델의 메트릭스를 실시간으로 모니터링하고 개선 사항을 적용합니다.
결론
강화 세부 조정은 AI 모델의 커스터마이징을 데이터 기반의 평가 학습을 통해 수행하며, 방대한 라벨 데이터 없이도 효과적인 모델 최적화를 가능하게 합니다. Amazon Bedrock에서 시작하고, 필요에 따라 SageMaker Training Jobs로 확장하며, Enterprise 수준에서는 SageMaker HyperPod를 활용할 수 있습니다. 더 나아가 복잡한 AI 애플리케이션을 위해 Nova Forge를 통한 맞춤형 환경을 탐색할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
