Amazon SageMaker와 Bedrock을 활용한 다중 LoRA 모델 구현 가이드
서론
오늘날 많은 조직과 개인이 다양한 AI 모델들을 운영하고 있으며, 특히 최근 각광받는 Mixture of Experts (MoE) 모델들은 효율적인 GPU 자원 활용이 필요합니다. 이러한 모델들을 효과적으로 운영하는 방법 중 하나는 Multi-LoRA 접근 방식으로, 이 방법을 통해 모델을 재학습하는 대신 작은 어댑터를 모델의 레이어에 삽입함으로써 모델을 조정합니다.
본문
Multi-LoRA의 구현 및 활용 사례
Amazon은 VLLM 커뮤니티와 협력하여 Multi-LoRA를 MoE 모델에서 효율적으로 서빙할 수 있는 솔루션을 개발했습니다. 이 방법을 통해 여러 사용자나 작업 요청에 대해 다중 LoRA 어댑터를 동시에 서빙할 수 있으며, 각 요청은 하나의 GPU에서 효율적으로 관리됩니다.
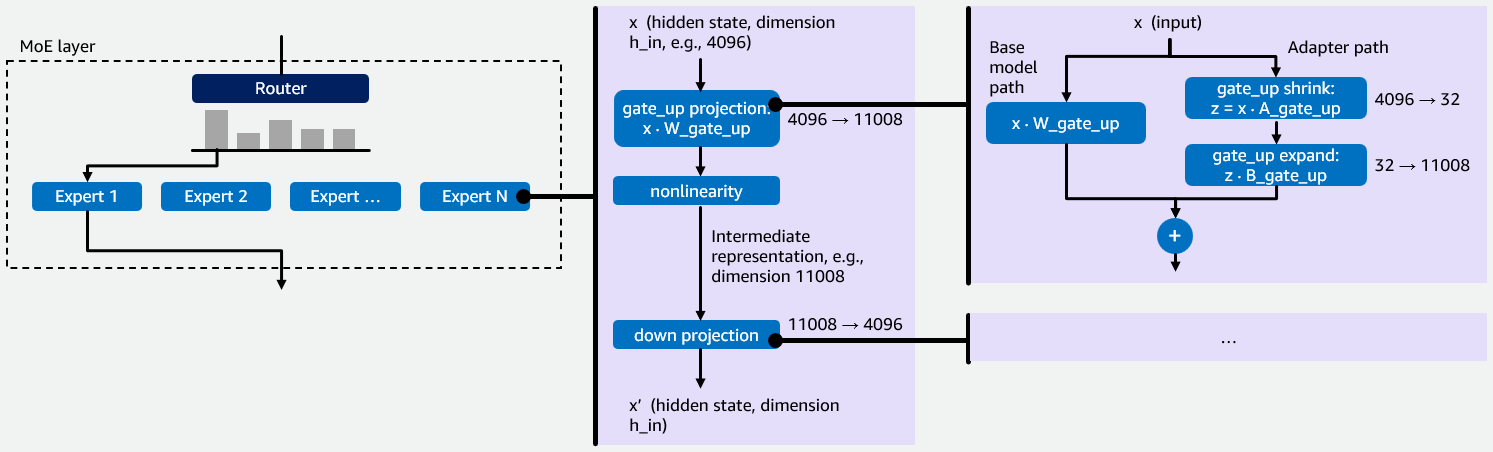
위 이미지처럼 MoE 모델은 전문가 네트워크와 라우터를 통해 입력 토큰을 가장 관련 있는 전문가에게 보내고, 해당 전문가의 출력을 집계하는 방식으로 운영됩니다. LoRA 어댑터가 적용되면 각 레이어의 프로젝션에 수축(shrink)과 확장(expand) 작업이 추가됩니다. 이러한 작업은 GPU 상에서 효율적으로 관리되며, 이를 통해 성능 병목 현상을 해결할 수 있습니다.
AWS는 Amazon SageMaker AI와 Amazon Bedrock에서 이러한 최적화를 통해 다양한 모델의 대기 시간을 줄이고 더 많은 출력 토큰을 빠르게 생성할 수 있게 합니다. 이를 통해 모델의 효율성을 19% 향상시키고 대기 시간을 8% 단축하는 성과를 얻었습니다.
결론
Amazon은 VLLM 커뮤니티와의 협력을 통해 MoE 모델, 특히 GPT-OSS, Qwen3 MoE 등의 Multi-LoRA 서빙을 구현하고 이를 공개 소스로 제공했습니다. 이로 인해 OTPS는 454% 개선되고 TTFT는 87% 줄어들었습니다. 이러한 최적화는 Amazon SageMaker AI와 Bedrock에서도 추가적인 이점을 제공합니다.
Multi-LoRA를 효과적으로 활용하려면 최신 vLLM 버전을 사용하고, Amazon SageMaker AI 또는 Bedrock에서 호스팅해야 합니다. 구체적인 세부 사항은 Amazon의 SageMaker AI 호스팅 문서와 Bedrock 가이드를 참조하세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
