아마존 노바 기반 LLM 룰 기반 심사자(AI 평가자)를 통해 생성형 AI 모델을 쉽게 비교 평가하는 방법
서론
생성형 AI의 발전은 놀라운 속도로 진행되고 있으며, 다양한 언어 모델 간 성능 차이를 정량적으로 평가하고 비교하는 것은 필수적인 과제가 되었습니다. 그러나 지금까지 많은 개발자와 머신러닝 엔지니어들이 모델 간 비교 평가를 위해 텍스트 결과를 수동으로 판별하거나, 일관되지 않은 기준으로 판단하는 등의 비효율적인 과정을 거쳐야 했습니다.
이러한 문제를 해결하기 위해 Amazon은 Amazon SageMaker AI 상에서 사용할 수 있는 Amazon Nova 기반 LLM Rubric Judge(룰 기반 심사자)를 제공하고 있으며, 이를 통해 모델 결과 평가의 효율성과 신뢰도를 획기적으로 높일 수 있습니다. 본 포스트에서는 해당 기능이 어떻게 작동하는지, 어떤 구성으로 동작하는지, 실제 적용 사례와 시각화 결과를 통해 생생하게 소개합니다.
본론
- Rubric 기반 LLM 평가자는 무엇인가?
Rubric 기반 LLM 평가자는 고성능 대형 언어 모델인 Amazon Nova를 활용하여 다양한 LLM의 출력값(응답)을 자동으로 비교, 평가하는 시스템입니다. 기존 평가 방식이 고정된 단일 체크리스트(“정중한가?”, “짧은가?” 등)로 평가했다면, Nova 기반 평가는 각 질문에 최적화된 평가기준을 실시간 생성하여 훨씬 세밀하고 유연한 평가를 가능하게 합니다.
예를 들어 “이 의학 문서를 환자를 위해 요약해줘”라는 프롬프트가 들어오면, Nova는 다음과 같은 체크리스트를 즉시 생성합니다.
- 쉬운 비의학 용어를 사용하는가?
- 진단 내용을 정확히 담았는가?
- 공감가는 어조를 유지하는가?
이 기준에 맞춰 두 개의 모델 응답을 비교하고, 점수를 부여해 최종 평가 결과를 도출합니다.
- 응답 비교 예시
질문: “공룡은 정말 존재했나요?”
응답 A와 응답 B 중 Amazon Nova는 A를 높은 점수로 선택했습니다. 그 이유는 A가 풍부하고 체계적인 역사적 증거를 포함하며, 창의적이고 응집력 있게 설명했기 때문입니다.

- 기업 활용 사례
-
모델 개발 및 체크포인트 선택
- 훈련 단계에서 각 모델 버전에 대해 자동 평가를 적용하여, 어떤 버전이 향상되었고 어떤 기준에서 퇴보했는지를 알 수 있어 하이퍼파라미터 최적화나 데이터셋 개선에 도움을 줍니다.
-
학습 데이터 품질 관리
- 오류 데이터를 사전에 걸러내거나, 너무 한쪽으로 치우친 답변쌍을 제거하여 효율적인 Curriculum Learning에 활용합니다.
-
원인 분석 및 디버깅 자동화
- 천 단위 이상 결과를 프롬프트별로 자동 분석하여 문제 원인을 특정 기준에서 정확히 파악할 수 있습니다.
- 동작원리 및 모델 구성
LLM 평가자는 JSONL 형태로 <프롬프트, 응답A, 응답B>를 받아 응답 별 점수와 지표를 YAML 형태로 출력합니다. 각 기준은 가중치 합이 1이 되도록 설계되며, 각 항목에 대해 1~5 점수 또는 True/False로 평가하고 세부 근거를 제공합니다.
예를 들어 특정 비교 항목에서 다음과 같은 기준이 사용됩니다.
- completeness (완전성): 2점 vs 5점
- clarity (명확성): 3점 vs 5점
- accuracy (정확성): 4점 vs 5점
이것을 종합해 A보다 B가 우수하다고 판단하고, 결과는 [[B>A]]로 표시됩니다.
- 이전 버전과의 차이
이전 LLM judge는 단순히 선호 응답만 표시한 데 비해, Rubric 기반 버전은 다음과 같은 메타데이터를 포함합니다.
- 평가 기준별 가중치와 설명
- 각 의사결정에 대한 점수 근거
- 1:1 비교 결과 및 점수 차이
- 평가 기준 재구성 및 가중치 조정 가능
사용자는 CI/CD 수준의 평가 자동화와 커스터마이징이 가능해집니다.
- 실제 예시 – Qwen 모델 비교 사례
Qwen2.5 1.5B Instruct vs Qwen2.5 7B Instruct 두 모델의 SQuAD 데이터 질문 응답 결과를 Amazon Nova로 비교 평가했습니다.
전처리: prompts → Qwen 출력값 생성 → JSONL 파일
처리: SageMaker AI 평가 Job 실행 → Nova로 평가
결과: 기준점수(e.g. completeness, clarity, accuracy), 각 모델의 평균 점수, 오차 범위, 승/패 비율 기록
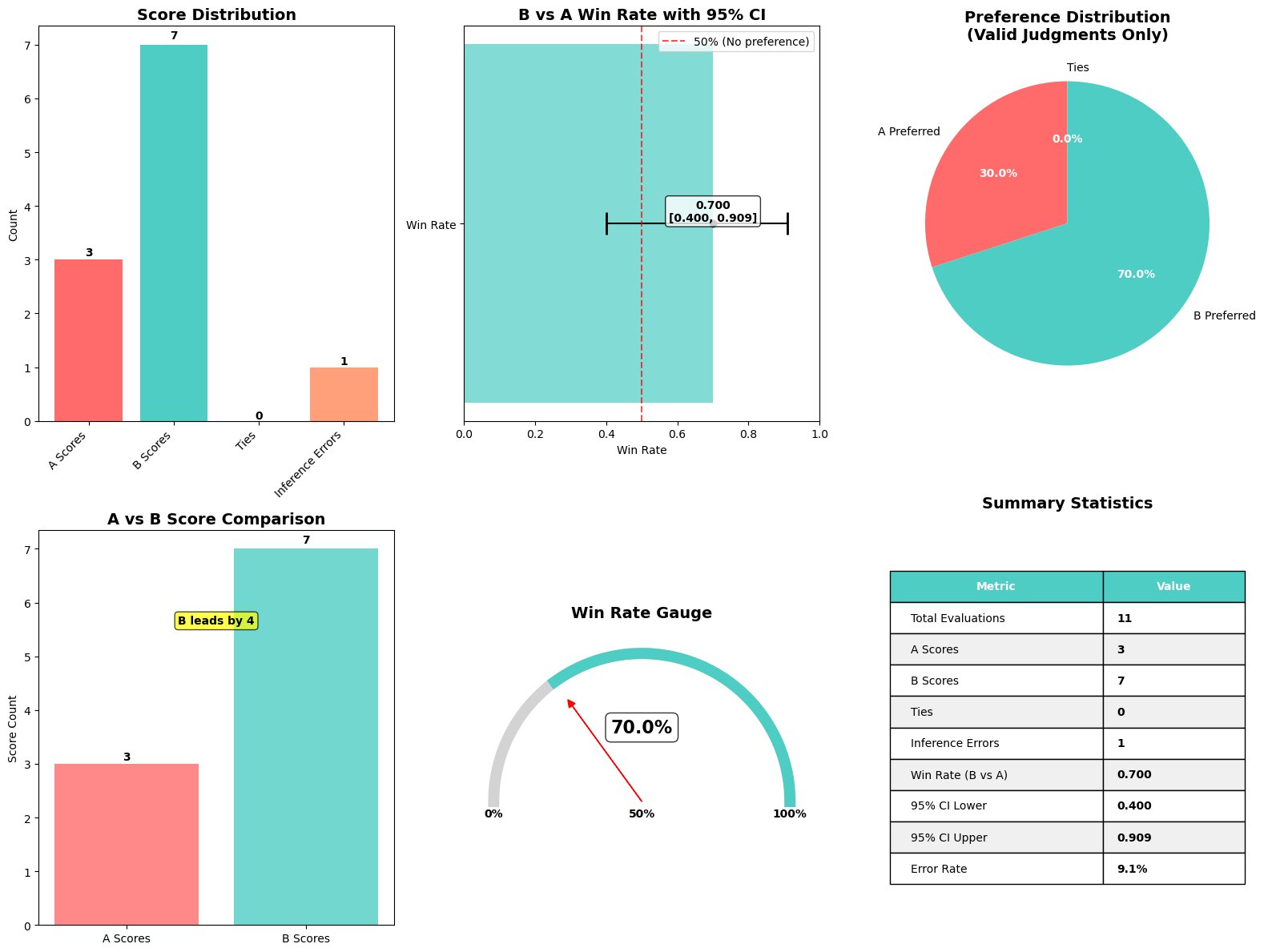
시각화 결과는 다음을 포함합니다.
- 모델 승률 비교 (예: 7B 모델 70% 승)
- 점수 마진: Model A(0.495) vs Model B(0.630)
- 기준별 점수 분석 및 응답별 지표
- 신뢰 구간 포함 승률 게이지
이를 통해 단순 비교 차원을 넘어 어떤 기준이 왜 우위였는지까지 명확히 해석 가능합니다.
결론
Amazon Nova 기반 LLM Rubric Judge는 생성형 AI 출력 평가를 단순화하면서도 정밀도·유연성·신뢰도를 모두 확보할 수 있는 혁신적 솔루션입니다. 특히 다음과 같은 상황에 매우 유용합니다.
- 모델 체크포인트 자동 선택 및 버전 비교
- 학습 데이터 품질 자동 평가
- LLM 출력 결과 분석 및 디버깅
이제 수천 개의 프롬프트에 대해 사용자가 원하는 기준을 기반으로, 자동 — 동시에 정량적 — 으로 평가하여 투명하고 의미 있는 결정을 내릴 수 있습니다. AI 시스템 운영자, 데이터 사이언티스트, 엔지니어에게 강력한 자동화 도구가 될 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
