멀티 에이전트 AI 아키텍처: Meta의 Llama 4와 Amazon Bedrock, Strands Agents로 영상 분석 자동화하기
최근 AI 기술의 발전과 함께 멀티 에이전트 시스템(Multi-Agent Systems)의 효율성과 확장성, 반응성이 다양한 산업군에서 주목받고 있습니다. 특히, Meta의 Llama 4, Amazon Bedrock, Strands Agents SDK를 연계해 구현된 영상 분석 자동화 워크플로우는 영상 콘텐츠를 지능적으로 이해하고 요약하는 예로 손꼽힙니다. 본 포스팅에서는 멀티 에이전트 활용 방법과 사례 중심으로 시스템의 구성, 배포 가이드, 자동화 흐름 등을 정리해보았습니다.
AI 멀티 에이전트 아키텍처의 가치
전통적 AI 파이프라인은 단일 모델 기반으로 구성되어 있어 처리 효율성과 전문성에 한계가 있었습니다. 하지만 LLM(Large Language Model) 위에 소형 추론 유닛(에이전트)을 구성하고, 이를 조율하는 구조를 도입하면 다음과 같은 이점을 얻을 수 있습니다.
- 확장성(Scalability): 병렬 처리를 통해 대량의 데이터 또는 영상 스트리밍에도 실시간으로 대응
- 복원력(Resilience): 하나의 에이전트 실패 시 다른 에이전트로 대체하거나 오류 방지 가능
- 전문화(Specialization): 각 영역별(영상 분석, 시간 순서 처리, 요약 등)에 전문화된 에이전트를 배치
- 자동화 및 유연성(Automation): 동적 시나리오 변경에 따라 유연하게 워크플로우 조정 가능
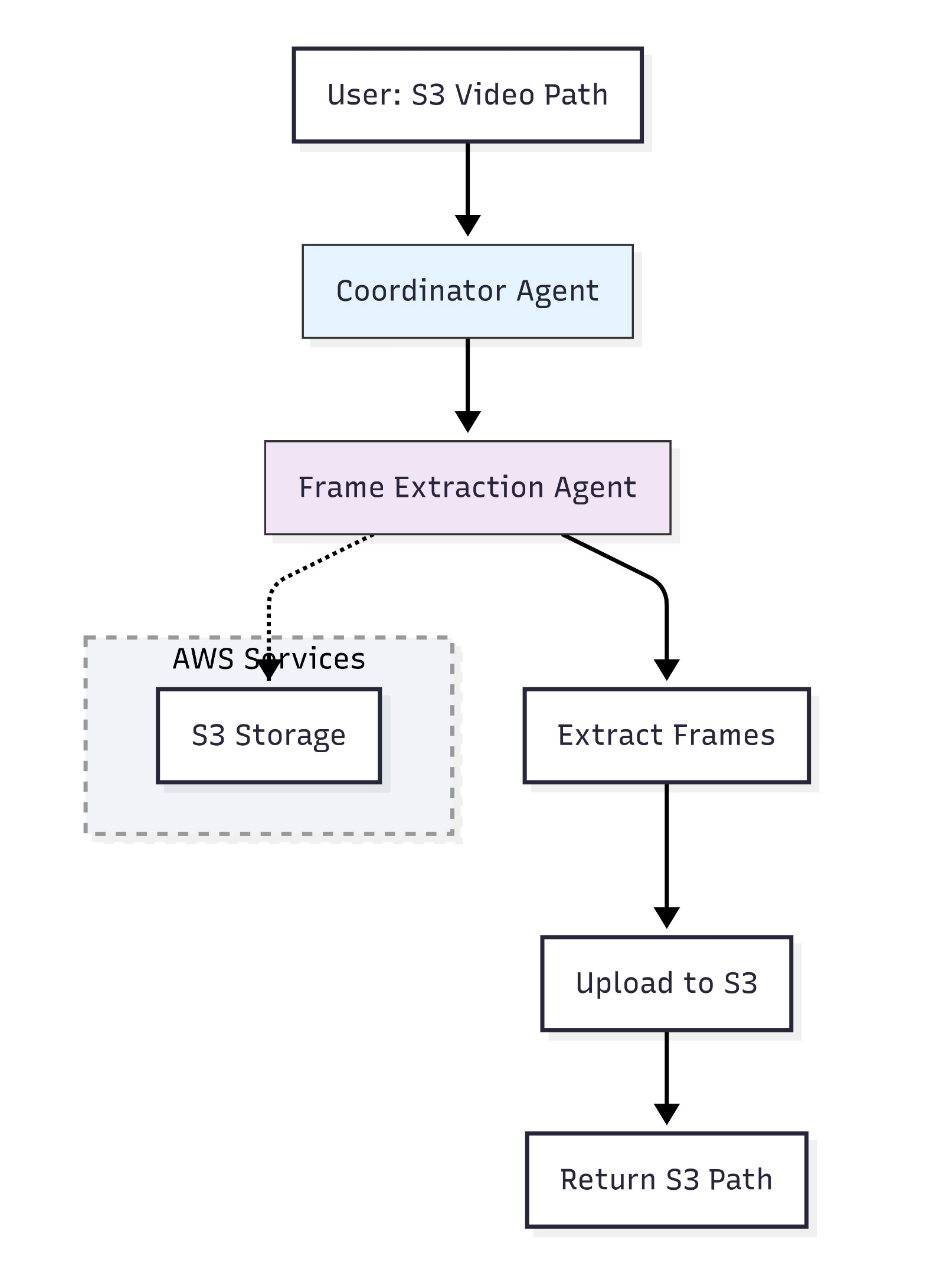
Strands Agents SDK와 Meta’s Llama 4 멀티 에이전트 구성
전체 워크플로우는 6개의 특화 에이전트(각 기능 모듈화)로 구성됩니다. Strands의 Agents as Tools 개념은 각 에이전트를 함수처럼 호출 가능한 도구로 구성하여 모듈 간 유기적 협업을 가능하게 합니다.
- Llama4_coordinator_agent: 전체 플로우를 관리, 구성하는 중앙 지휘 에이전트
- s3_frame_extraction_agent: 영상에서 프레임을 추출하여 S3에 업로드
- s3_visual_analysis_agent: Llama 모델을 통해 이미지 인식 및 JSON 파일 생성
- retrieve_json_agent: 분석된 JSON 데이터를 S3에서 가져오는 역할
- c_temporal_analysis_agent: 시간 순서에 따라 영상 프레임을 분석
- summary_generation_agent: 최종 보고서 형식의 요약을 생성
각 에이전트는 Amazon S3, Amazon Bedrock(AgentCore 포함), SageMaker와 자연스럽게 통합되며, 이 구조를 통해 다양한 환경에서 자동화된 분석을 설계할 수 있습니다.
Llama 4의 초장기 메모리 Context 처리 기능
Meta의 Llama 4 Scout/ Maverick 모델은 각각 1백만~1천만 토큰 규모의 초장기 컨텍스트 윈도우를 지원합니다. 이는 단일 입력 내에서 방대한 양의 문서, 이미지, 코드 등을 통합 분석하고, 맥락에 맞는 정밀 추론 및 다단계 워크플로우가 가능합니다.
- Llama 4 Scout: 10M 토큰 (Amazon Bedrock 활용 시 최대 약 3.5M 지원)
- Llama 4 Maverick: 1M 토큰, 멀티모달 문서 이해, 코드 분석 등 최적
이 기능은 예를 들어 수천 개의 문서 요약, 코드베이스 전체 분석, 대화 지속성 유지 등 광범위한 업무에 적합합니다.
Gradio 기반 영상 분석 자동화 앱 배포 가이드
자동화 앱 배포는 CLI 터미널에서 간단한 명령어 실행만으로 이루어집니다. Gradio UI를 활용하면 영상 파일을 업로드하고 분석 결과를 바로 확인할 수 있습니다.
-
프로젝트 Git 클론:
git clone https://github.com/aws-samples/Meta-Llama-on-AWS.git
cd agents/strands/Bedrock/multi-agent-video-processing/ -
종속 라이브러리 설치:
pip install -r requirements.txt -
앱 실행:
python gradio_app.py 실행 후, 생성된 링크 클릭하여 브라우저 UI 접속 -
영상 업로드 및 Run 버튼 클릭하여 자동 분석 시작
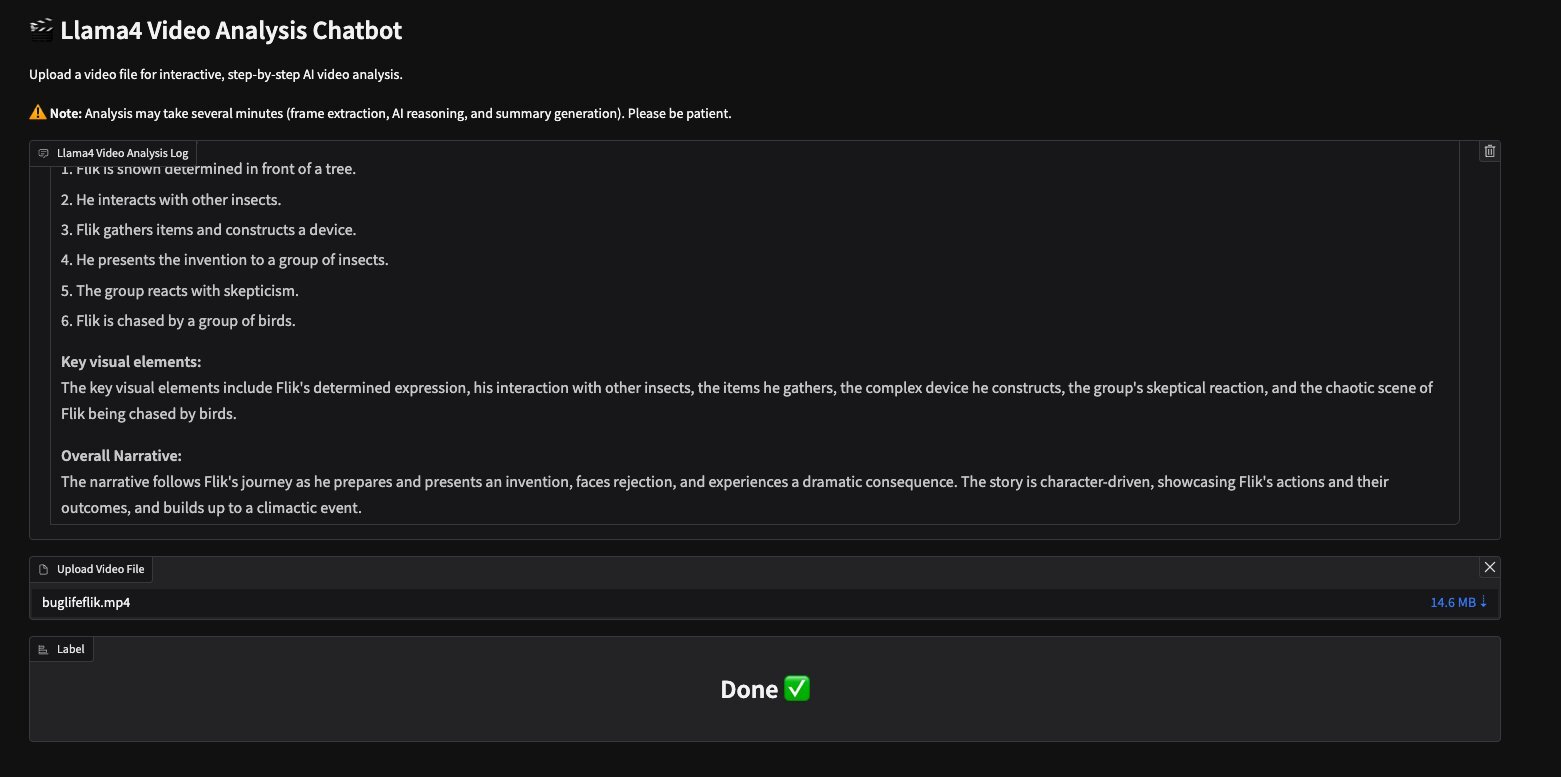
영상 분석 예시 결과:
- 등장인물: Flik 및 다른 곤충들
- 행동 요약: 아이템 수집 → 장치 제작 → 발표 시도 → 회의적 반응 → 새 떼 추격
- 핵심 시각 요소: Flik의 표정, 장치, 반응 장면
- 전체 시나리오: 혼자에서 시작하여 집단 행동으로 마무리됨
Jupyter Notebook 활용 자동화 가이드
SageMaker 버킷에 영상을 업로드하고, Python 코드를 통해 전 과정을 순차 진행할 수 있습니다.
- 영상을 S3에 업로드 후 S3 URI 확보
- new_llama4_coordinator_agent()를 실행하여 워크플로우 시작
- 영상 분석 지시 텍스트를 전달하여 자동 실행
활용 예:
video_instruction = f"Process a video from {s3_video_uri}. Use tools in this order: run_frame_extraction, run_visual_analysis…"
활용 시나리오 및 업무 적용 예시
- 스마트시티: 수천 대의 CCTV 스트림 실시간 분석 및 이상 감지
- 제조업/IIoT: 예지보수(Predictive Maintenance)를 위한 센서+영상 분석
- 금융: 상담 내역 등 멀티미디어 기반 협업 분석
- 미디어 산업: 자동 태깅 기반 콘텐츠 검색 엔진 구성
시스템 구성도 및 다양한 AWS 서비스(Amazon S3, SageMaker, Bedrock)의 활용은 엔터프라이즈 솔루션의 확장성과 안정성을 보장합니다.
결론
이번 사례는 Strands Agents, Meta Llama 4, Amazon Bedrock을 활용하여 멀티 에이전트 기반 영상 분석 자동화 시스템을 효율적으로 구현한 활용 방안입니다. 고정된 수작업 파이프라인이 아닌 도메인 특화 에이전트를 조합해 높은 자동화율과 유연한 워크플로우 구성이 가능합니다. 여러분의 조직에서도 이 아키텍처를 기반으로 산업 특정 요구에 맞는 멀티 에이전트 서비스를 개발해보시길 추천드립니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
