인공지능 에이전트 시대, 고도화된 파인튜닝 기법으로 기업 경쟁력을 높이는 방법
AI 에이전트 시스템이 기업의 다양한 비즈니스 프로세스를 최적화하고 자동화하는 데 점점 더 중요한 역할을 하고 있는 가운데, 그 성능의 핵심이 되는 것은 바로 '고급 파인튜닝 기술'입니다. AWS가 수행한 다양한 엔터프라이즈 수준의 적용 사례들을 통해 알 수 있듯, 단순한 프롬프트 엔지니어링만으로는 도달할 수 없는 정확도와 도메인 지식을 요구하는 고위험(high-stakes) 작업에서는 파인튜닝이 매우 결정적인 역할을 하고 있습니다.
본 블로그에서는 대규모 언어 모델(LLM)의 고급 파인튜닝 기법의 진화와 이에 기반한 다중 에이전트 오케스트레이션 활용 방안, 아마존의 실제 적용 사례, 그리고 배포 가이드 및 아키텍처 설계까지 단계적으로 안내합니다.
고급 파인튜닝의 필요성과 활용처
기초 모델이 지닌 일반화된 능력으로도 많은 유즈케이스가 해결 가능하지만, 환자 안전, 운영 효율성, 고객 신뢰와 같은 요소가 중요한 고위험 업무에서는 다음과 같은 조건에 따라 고급 파인튜닝이 필수적입니다.
- 도메인 특화된 지식을 반영해야 할 때
- 규정·컴플라이언스 리스크가 큰 업무
- 장기적인 ROI와 운영 자동화가 중요한 기업 환경
- 도메인 맞춤형 의사결정 로직이 필요한 경우
실제 아마존에서는 약물 복약 오류를 33% 줄이고, 엔지니어링 프로세스에서 인간의 수작업 부담을 80% 줄였으며, 콘텐츠 평가 정확도를 96%까지 높이는 데 파인튜닝 기술을 활용했습니다.
진화해온 파인튜닝 기술 단계별 정리
- SFT(Supervised Fine Tuning): 지도학습 기반 파인튜닝으로, 특정 지시를 따르는 기본적인 응답 생성을 유도함.
- PPO(Proximal Policy Optimization): 강화학습 기반으로 보상 모델 정보를 바탕으로 LLM을 조정.
- DPO(Direct Preference Optimization): 명시적 보상모델을 생략하고, 선호 응답 비교를 통해 보다 간단하고 안정적인 학습 제공.
- GRPO(Grouped RL from Policy Optimization): 응답 그룹 간 상대적인 비교를 통해 경쟁적 학습 유도. 연쇄적 추론(CoT)에 매우 적합.
- DAPO(Direct Advantage Policy Optimization): GRPO보다 더 세분화된 피드백과 합리적인 시퀀스 학습 지원.
- GSPO(Group Sequence Policy Optimization): 긴 시퀀스로 이뤄진 MoE형태의 에이전트 처리에 효과적인 향상 기술.
이러한 기술들은 단순 정적 모델을 넘어, 도메인에 맞는 도구 사용, 계획 수립, 복잡한 문제 해결을 가능케 하는 에이전트 아키텍처로 진화하게 합니다.
아마존 사례로 보는 활용 방식 비교
- Amazon Pharmacy: 약물 복약 지침을 검토하는 에이전트 개발. 수천 건의 약사 전문가 주석 데이터를 기반으로 SFT, PPO 등을 이용하여 조정. 약물 복약 오류를 33% 감소시킴.
- Amazon GES(Global Engineering Services): 도면 정보 검색 Q&A 에이전트를 Fine-Tuning. PPO 기반의 피드백 반영으로 정확도 및 평가 점수 향상. 전문가 작업 시간 80% 절감.
- Amazon A+ Content: 수억 건의 콘텐츠 품질을 자동 평가하는 경량화된 모델 구성. 비전-언어 모델 기반 피처 추출 및 분류 핵심. 정확도 77% → 96% 개선.
이 세 가지 사례 모두 특화된 도메인 지식의 내재화와 자동화 흐름 구현을 통해 구체적인 비즈니스 성과로 이어졌습니다.
AWS 기반의 고급 파인튜닝 및 에이전트 배포 가이드
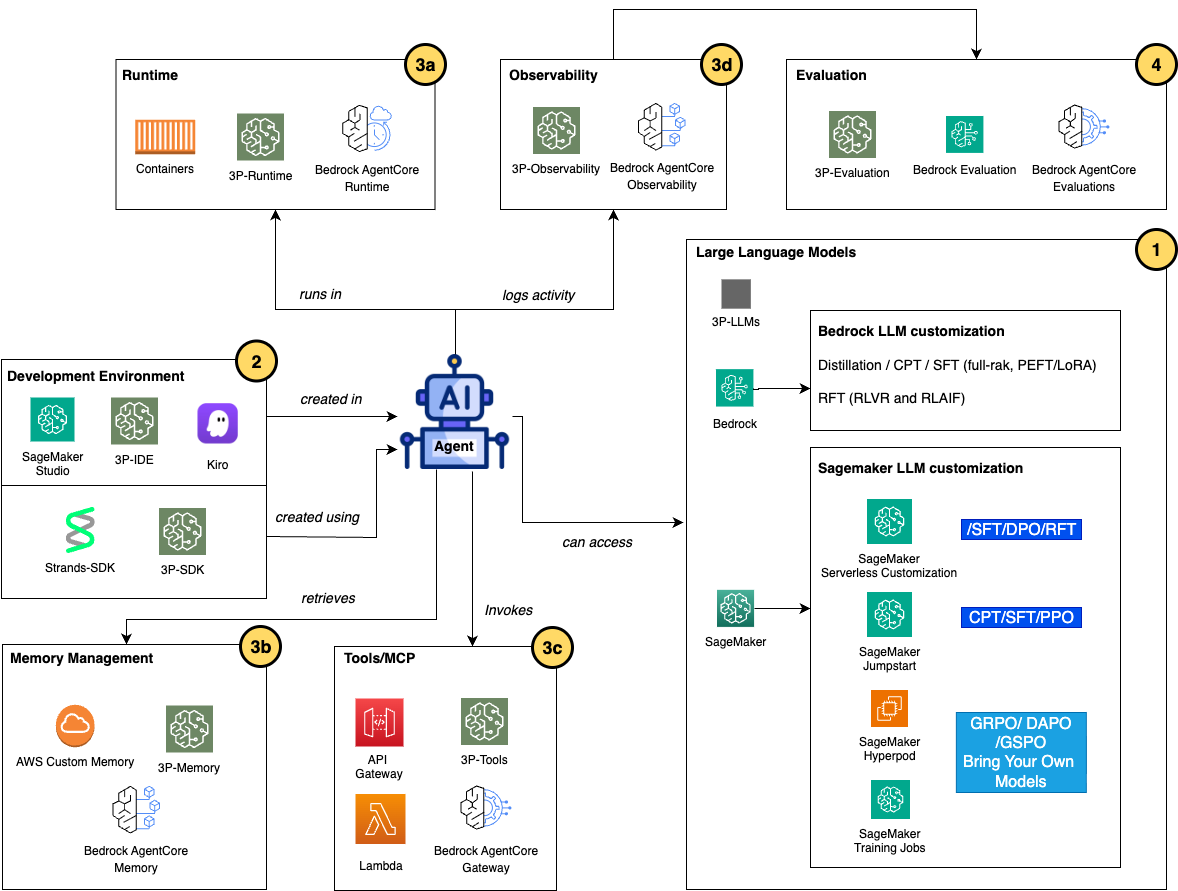
AWS는 다양한 파인튜닝 및 자동화 기술을 AI 에이전트에 손쉽게 적용할 수 있도록 지원하고 있습니다.
- Amazon Bedrock + AgentCore: 프롬프트 엔지니어링, SFT, RFT, DPO 등 다양한 방식의 모델 커스터마이징 및 배포 지원.
- Amazon SageMaker AI: 하이브리드 형태의 Jupyter 기반 개발, 학습/추론 환경 제공. SageMaker Training Jobs 또는 HyperPod를 통한 분산 학습 가능.
- 무서버(Serverless) 커스터마이제이션: SageMaker Studio UI 혹은 SDK 환경에서 손쉽게 모델 파인튜닝, 추론 서비스 배포 가능.
- Nova Forge: 고성능 자체 모델 학습용 프레임워크. 구축부터 평가, 호스팅까지 End-to-End 가능.
개발, 운영, 모니터링 구성 요소들은 Amazon Kiro, PyCharm, AgentCore의 Gateway, Memory, Observability 등으로 구성되어 있으며, 도구 수준의 연동 및 과거 상호작용 기억, 실패 처리까지 고려된 구조로 되어 있습니다.
기술 도입을 위한 단계별 로드맵
1단계: Prompt Engineering (60–75% 정확도, 간단한 업종·업무).
2단계: SFT (80–85% 정확도, 전문가 피드백 내재화).
3단계: DPO 적용 (안정성·스타일·컴플라이언스 요구).
4단계: GRPO / DAPO 고도화 (복잡한 사고·계획·대규모 판단 등).
이러한 단계별 접근법은 12~18개월 내 안정적인 ROI를 보장하며, 지속 가능한 AI 전략을 구축하는 근간이 됩니다.
결론
단순한 키워드 응답형 챗봇을 넘어서 고차원적인 의사결정과 도구 활용 기능을 가진 에이전트를 구축하려면, 이에 맞는 고급 파인튜닝이 반드시 필요합니다. AWS는 서버리스 옵션부터 분산형 학습 파이프라인, 고도화된 옵티마이저와 평가 메커니즘까지 다양한 툴을 제공하고 있습니다. 무엇보다 중요한 것은 ‘기술의 고도화’가 아닌, 현재 업무가 요구하는 최적 지점을 파악하고 지속적으로 조직에 맞는 활용 전략을 구축하는 것입니다.
고위험 환경일수록, 정밀한 판단이 요구될수록 고급 파인튜닝은 단순한 선택이 아닌 비즈니스 경쟁력의 필수 역량으로 작용합니다. 지금의 에이전트를 보다 전략적인 아키텍처로 성숙시켜야 할 이유입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
