기업을 위한 텍스트 및 오디오 감정 분석: AWS 생성형 AI 서비스 활용 가이드
고객의 목소리를 정확히 이해하고 분석하는 것은 현대 비즈니스 전략에서 핵심입니다. 특히 텍스트나 음성을 통해 이루어지는 고객과의 상호작용이 증가함에 따라, 감정 분석(Sentiment Analysis)은 고객 만족도 향상 및 개인화된 경험 제공을 위한 중요한 기술로 부상하고 있습니다. 이 글에서는 AWS 생성형 AI 서비스를 활용한 텍스트 및 오디오 기반 감정 분석 접근 방식을 소개하고, 실제 실험을 통해 분석된 모델 비교 및 아키텍처 구현 가이드를 포함해 기업 환경에서 바로 적용 가능한 인사이트를 제공합니다.
텍스트 기반 감정 분석
텍스트로 이루어진 데이터는 SNS 포스트, 고객 서비스 채팅, 전자상거래 리뷰 등 다양한 형태로 존재합니다. 이들을 효과적으로 분석하기 위해 AWS는 다음과 같은 서비스를 제공합니다.
-
Amazon Bedrock
Bedrock은 Anthropic, Meta, Mistral 등 다양한 LLM 제공자의 모델을 API 방식으로 접근할 수 있는 서버리스 플랫폼입니다. 다양한 모델을 실시간으로 테스트하고, 요구사항에 맞는 맞춤형 모델을 선택할 수 있다는 강점이 있습니다. -
Amazon SageMaker AI
SageMaker AI는 Llama 3, Mixtral, DeepSeek 등의 오픈소스 모델을 활용할 수 있게 해주는 관리형 플랫폼입니다. 또한 JumpStart를 통해 간편한 배포가 가능하며, GPU 지원 인프라와 함께 맞춤형 모델 파인튜닝도 수행할 수 있습니다. -
Amazon Comprehend
Comprehend는 기본적인 감정 분류 뿐 아니라 엔터티 인식, 주제 모델링 기능도 갖춘 범용 텍스트 분석 API입니다. 다양한 언어와 형식을 지원하여 멀티 채널 텍스트 분석용으로 유용합니다. -
Amazon Kinesis
Kinesis는 실시간 텍스트 데이터 스트리밍을 위한 고성능 인프라입니다. 챗봇 로그, 트위터 스트림, 고객 서비스 채팅 등 다양한 소스와 연동해 분석 파이프라인을 자동화할 수 있습니다.
모델 간 성능 비교
다양한 LLM 모델을 테스트한 결과, 전체적으로 텍스트만으로 감정을 분류하는 정확도는 다소 낮았습니다. 이는 텍스트만으로는 풍부한 맥락이나 어조를 파악하기 어려운 경우가 많기 때문입니다. 예를 들어, Llama 3는 약 19%의 정확도를 보였으며, Claude, Mixtral 등의 모델도 비슷한 수준에 머물렀습니다. 다만, OpenAI의 파인튜닝된 모델은 높은 정밀도와 재현율을 보여주며, 도메인에 특화된 학습이 중요함을 시사하였습니다.
활용 및 향후 방향
- 고급 프롬프트 엔지니어링: 세분화된 명령어 설계, 체계적 추론 프롬프트를 통해 LLM의 성능을 향상할 수 있습니다.
- 다국어 적용: 다른 언어나 방언에서도 효과적인 결과를 얻기 위해 멀티링구얼 모델을 활용하거나 현지화된 데이터로 파인튜닝이 필요합니다.
- 하이브리드 모델 설계: 텍스트, 오디오, 메타데이터 등을 결합한 멀티모달 접근 방식을 적용해 더 풍부한 감정 표현을 분석할 수 있습니다.
오디오 기반 감정 분석
오디오는 말투, 강세, 억양과 같은 감정 신호가 풍부하게 담긴 정보원이며, 텍스트 기반 분석으로는 포착하기 어려운 미묘한 감정까지 감지할 수 있게 합니다. AWS를 활용한 오디오 기반 분석은 다음과 같은 특징을 가집니다.
-
Amazon SageMaker Studio
HuBERT, Wav2Vec, Whisper와 같은 음성 기반 모델을 GPU 인스턴스에서 손쉽게 학습하고 평가할 수 있게 해주는 관리형 플랫폼입니다. -
Amazon Transcribe
필요시 오디오를 텍스트로 변환해 하이브리드 분석 방식에 적용할 수 있습니다.
모델 성능 비교 실험
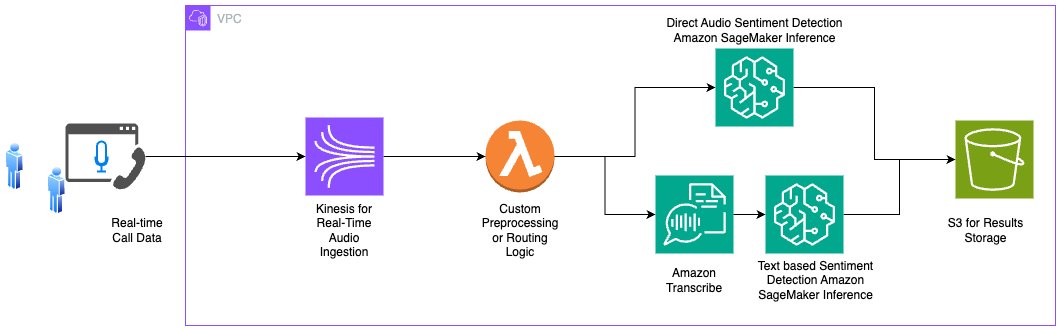
HuBERT, Wav2Vec, Whisper 등 세 가지 주요 음성 모델을 사용해 두 가지 유형의 데이터셋으로 실험을 진행했습니다.
- Type 1: 특정 문장을 다양한 감정으로 말한 음성 (고정된 콘텐츠, 다양한 억양)
- Type 2: 다양한 문장과 감정이 혼합된 복합 음성 (콘텐츠 복잡도 증가)
실험 결과, Type 1 데이터셋에서는 Whisper가 최고 정확도(91%)를 기록했으며, Type 2에서는 모든 모델의 성능이 60% 이하로 낮아졌습니다. 이는 다양한 문맥과 어휘가 포함되어 억양만으로는 감정 구분이 어려운 경우가 많음을 의미합니다.
활용 방안과 개선 방향
- 데이터 다변화 및 확장: 다양한 환경 소음, 억양, 지역 방언을 포함한 데이터 수집이 필요합니다.
- 멀티모달 결합: 오디오 모델의 억양 분석 결과와 텍스트 모델의 의미 분석을 결합해 더욱 정확한 감정 분석 수행
- 실시간 처리: Amazon Connect 등 고객센터 솔루션에 실시간 피드백 제공이 가능한 추론 워크플로우 구성 지원
결론
텍스트 및 오디오 기반 감정 분석은 고객 경험 혁신의 핵심 기술입니다. AWS는 다양한 생성형 AI 및 데이터 스트리밍, 전처리, 추론, 시각화 도구를 통해 전체 워크플로우를 자동화 및 최적화할 수 있도록 지원합니다. 정확도, 확장성, 비용 최적화를 고려해 텍스트, 오디오 또는 하이브리드 방식 중 최적의 접근 방식을 선택하는 것이 중요합니다.
AWS를 기반으로 한 다음과 같은 주요 구성 요소를 고려하면 효과적인 적용이 가능합니다.
- 데이터 수집: Amazon Kinesis
- 전처리: AWS Lambda, Amazon EMR
- 추론: Amazon Bedrock, SageMaker AI, Amazon Comprehend
- 오디오 변환 및 분석: Amazon Transcribe, HuBERT, Wav2Vec, Whisper
- 고객 서비스 연동: Amazon Connect
기업은 이러한 기술 스택을 적절히 활용해 고객의 감정을 정밀하게 분석하고, 차별화된 경험을 제공하는 자동화된 인프라를 구축할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
