가중치 및 활성화 기반 사후 훈련 양자화를 활용한 Amazon SageMaker AI에서의 대규모 언어 모델 추론 속도 향상
대규모 언어 모델(LLM: Large Language Models)은 뛰어난 언어 이해 및 생성 성능으로 혁신적인 변화를 이끌고 있지만, 이를 실제 서비스에 배포하려면 막대한 컴퓨팅 자원과 비용이 수반됩니다. 특히 수십억에서 수천억 개의 매개변수를 가지는 최신 LLM은 GPU 메모리, 추론 시간, 에너지 비용 등의 측면에서 부담이 크기 때문에 효율적인 배포 및 활용이 어려운 상황입니다.
이러한 문제를 해결하기 위한 대표적인 방안 중 하나가 사후 훈련 양자화(PTQ: Post-Training Quantization)입니다. PTQ는 학습된 모델의 가중치와 활성화를 16비트 또는 32비트에서 4비트 또는 8비트와 같은 정수로 변환하여 모델 크기를 최대 8배까지 축소하고, 추론 속도는 크게 증가시키며, 메모리 사용량과 대역폭 요구사항을 낮출 수 있습니다. PTQ는 재학습 없이 적용 가능하여, 실서비스를 위한 대형 신경망 모델을 효율적으로 배포할 수 있게 합니다.
이번 블로그에서는 Amazon SageMaker AI 상에서 AWQ(Activation-Aware Weight Quantization)와 GPTQ(Generative Pre-trained Transformer Quantization) 양자화 알고리즘을 활용하여 LLM의 추론 성능을 최적화하고, 다양한 WxAy (가중치x비트/활성화y비트) 조합을 통해 실제 추론 성능을 벤치마크한 과정을 소개합니다.
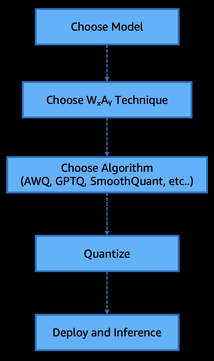
사후 훈련 양자화의 핵심 원리와 WxAy 구조
PTQ는 모델의 가중치 및 활성화 경로를 정밀도 측면에서 줄이는 방식으로 이루어집니다. WxAy 표기법은 가중치(W)를 x비트로, 활성화(A)를 y비트로 양자화했음을 의미합니다.
- W8A16: 가중치는 8비트 정수, 활성화는 16비트 부동소수
- W8A8: 가중치와 활성화 모두 8비트 정수 (엔드투엔드 정수 연산에 용이)
- W4A16: 가중치 4비트, 활성화 16비트 (초저비트 가중치를 사용해 메모리 절감)
- W4A16(대칭/비대칭): 대칭 스케일은 정밀도 손실에 취약, 비대칭은 높은 유지 성능 보장
비대칭 4비트(W4A16 Asymmetric) 가중치 방식은 한정된 정수 표현 범위 내에서 데이터 분포를 더 잘 반영하여, 정밀도를 유지하면서도 메모리는 크게 줄여줍니다.
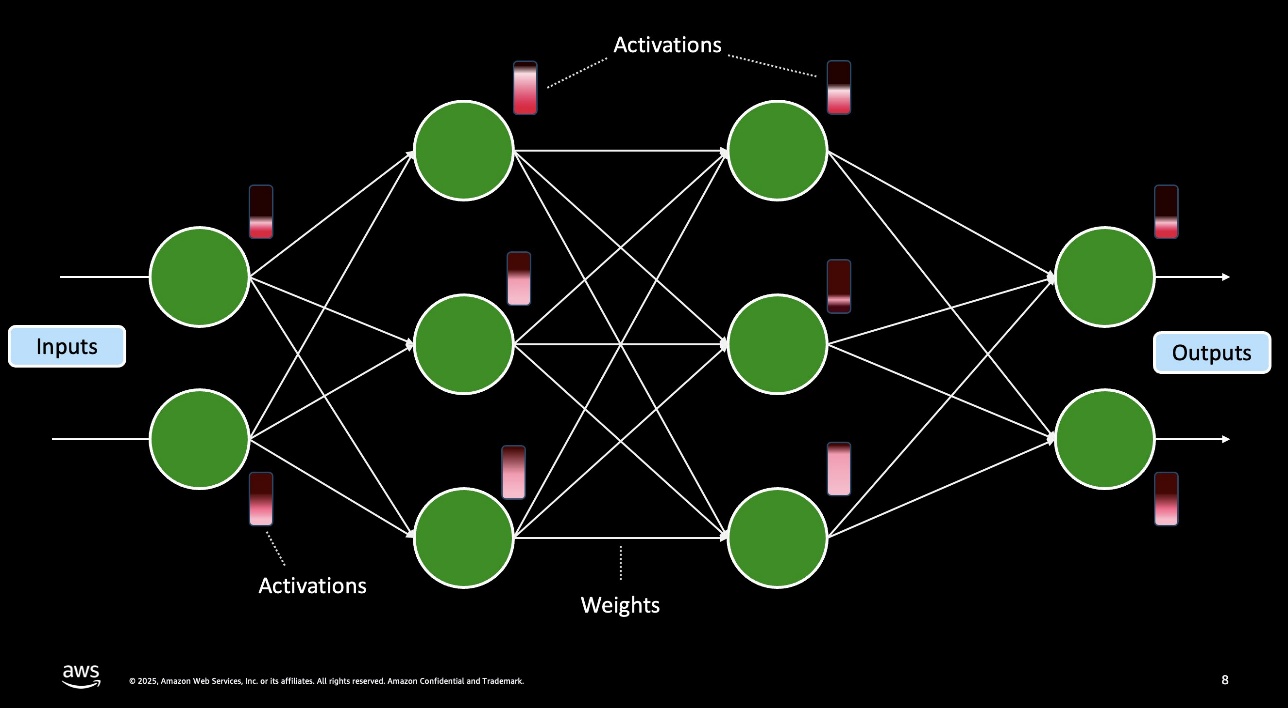
Amazon SageMaker 기반 양자화와 실배포 자동화
양자화 모델을 Amazon SageMaker AI 상에서 손쉽게 구현하기 위해 AWS는 vllm 기반의 llm-compressor 패키지를 제공합니다. Hugging Face Transformers로 모델을 불러오고, 대표 입력 샘플을 통해 통계적 calibration을 수행한 후, W4A16 혹은 W8A8과 같은 방식으로 압축 및 변환합니다. 이 모든 과정은 SageMaker Training Job을 통해 GPU 기반에서 자동화된 파이프라인으로 수행 가능합니다.
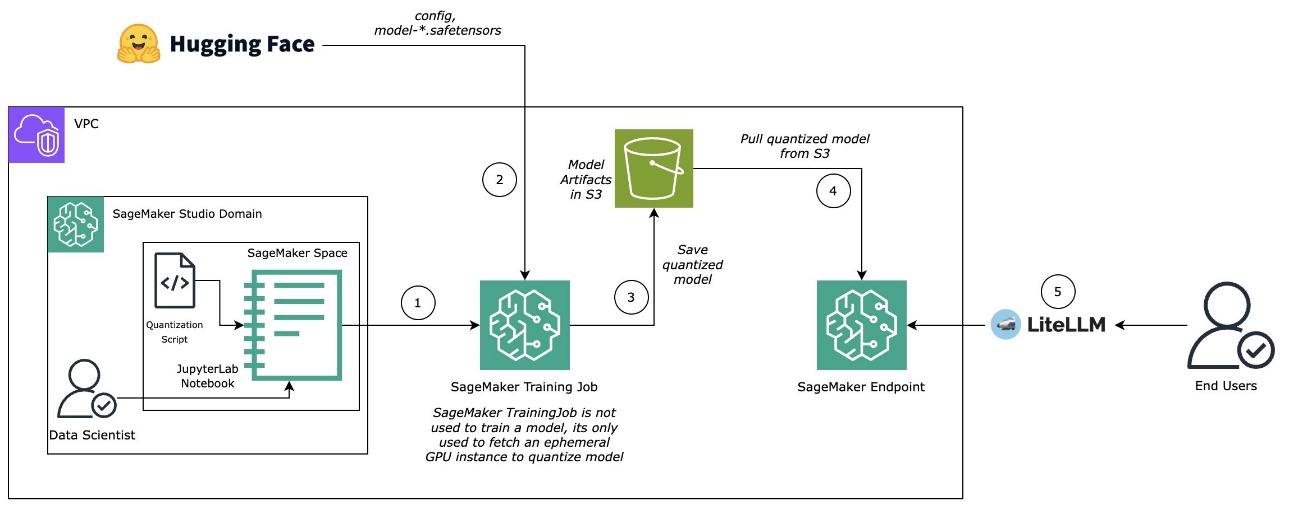
이후 아마존 S3에 저장된 양자화 모델은 DJL Inference LMI 컨테이너(vLLM 백엔드)를 통해 실시간 엔드포인트로 배포됩니다. SageMaker의 고급 보안 기능과 서버리스 배포 옵션을 활용하면, 양자화된 LLM을 기업 서비스에서도 안정적으로 활용할 수 있습니다.
AWQ와 GPTQ 알고리즘 비교
- AWQ: 활성화 값이 큰 채널(상위 1%)에 스케일 계수를 곱해 정밀도 손실을 줄여주는 방식. 계산 복잡도 없이 4비트 정밀도에서도 FP16 수준의 추론 성능을 유지합니다.
- GPTQ: 헷세안 행렬 기반의 민감도 평가를 통해 각 레이어의 출력을 최대한 유지하면서 가중치를 단계적으로 양자화합니다. 3–4비트까지 손실 없이 가능하며 대규모 모델에도 적용 가능합니다.
성능 벤치마크: 메모리, 지연 시간, 처리량, TTFT, ITL
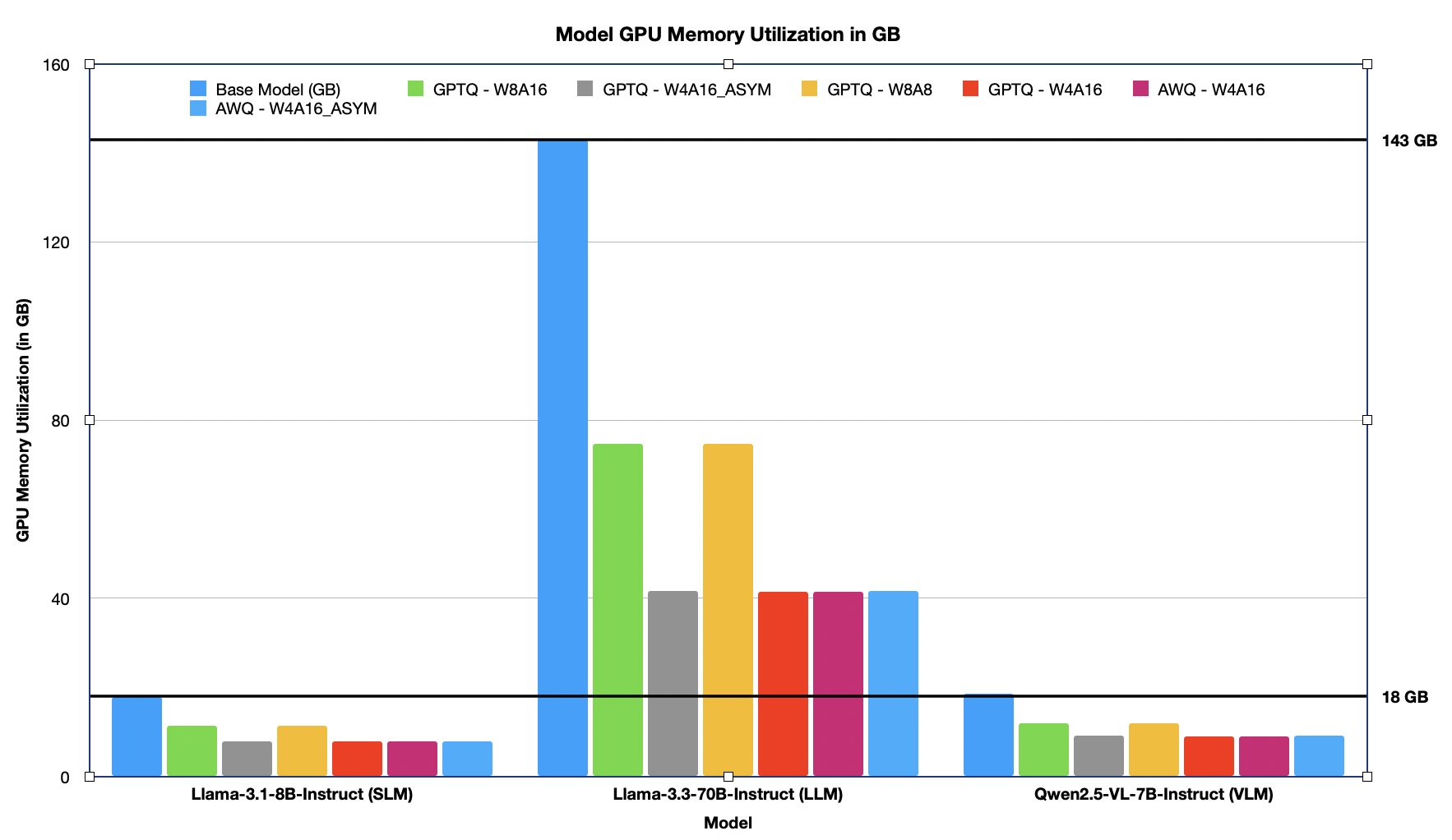
우리는 Llama-3.1-8B, Llama-3.3-70B, Qwen2.5-VL-7B 모델을 각각 다양한 WxAy 양자화 조합으로 적용해 아래의 주요 메트릭을 평가했습니다.
-
GPU 메모리 사용량: 약 30~70% 감소. 양자화를 통해 더 작은 인스턴스에서도 LLM 활용 가능.
-
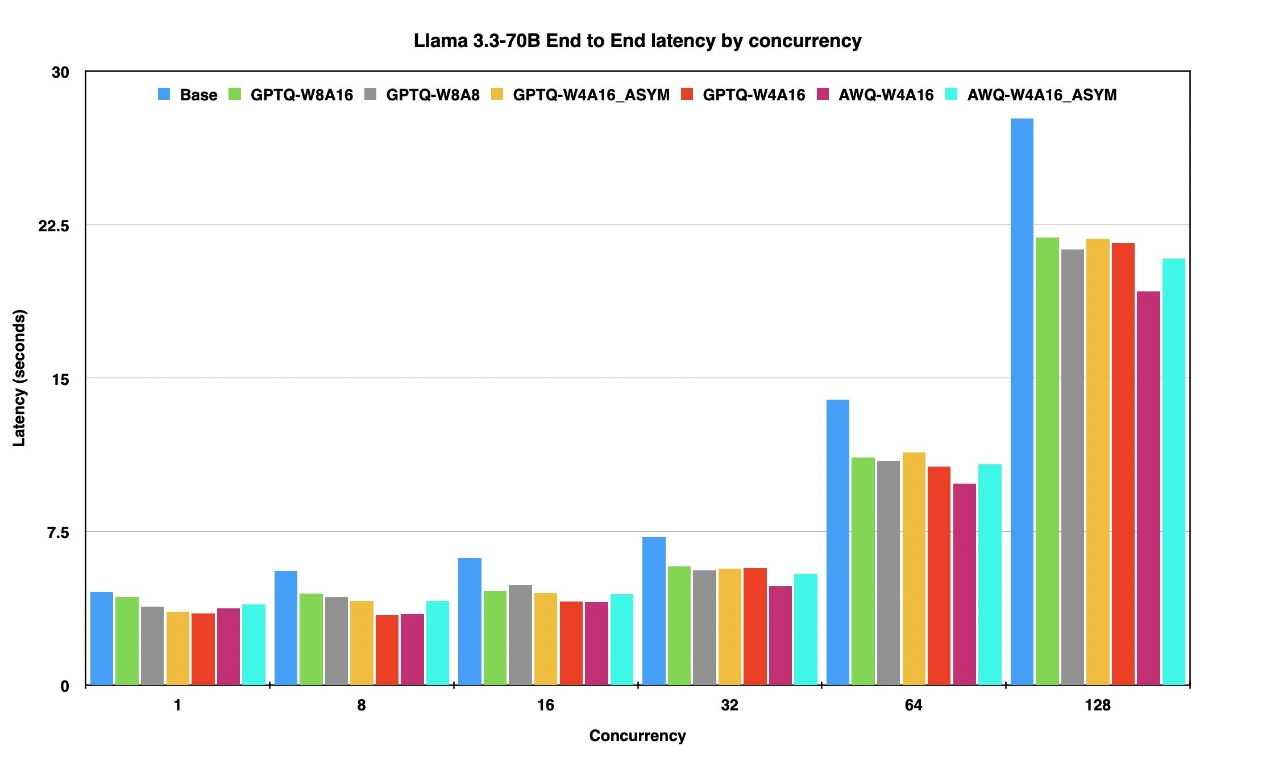
End-to-End 지연 시간: Raw 모델 대비 최대 60% 이상 단축. 고부하 상황에서도 응답 속도 개선.
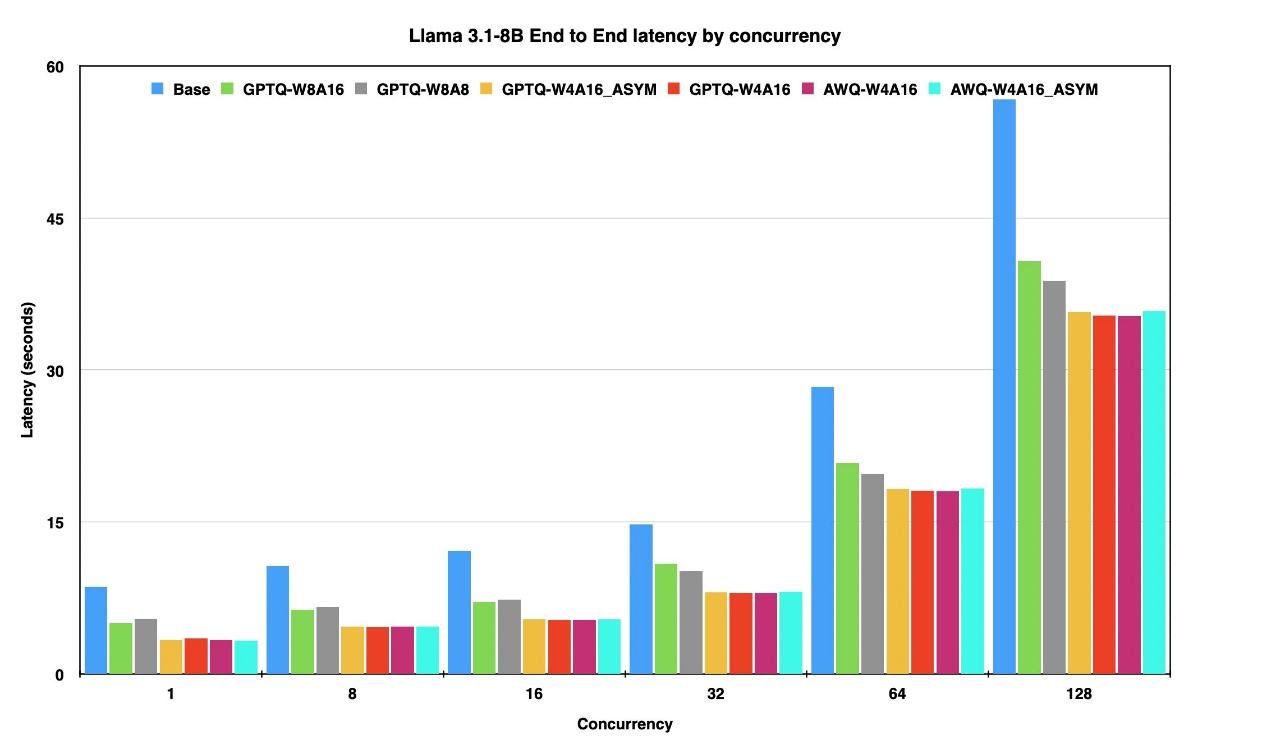
-
첫 토큰 생성까지 걸린 시간(TTFT): 상대 반응성을 결정하는 TTFT가 양자화 모델에서 50% 이상 향상되었습니다.
-
Inter-Token Latency(ITL): 각 토큰 사이 평균 출력 속도 개선. 스트리밍 응답 속도 향상에 효과적.
-
처리량(Throughput): 초당 생성 토큰 수 기준, Raw 모델 대비 1.5~3배 처리량 증가.
결론
이 글에서는 GPTQ 및 AWQ와 같은 사후 훈련 양자화 기법을 Amazon SageMaker에서 활용하여 LLM의 추론 효율을 극대화하는 방법을 소개했습니다. 이 기법은 성능 저하를 최소화하면서도 메모리, 속도, 비용 문제를 해결하기 위한 효과적인 솔루션으로 자리 잡고 있으며, GPU 자원이 제한된 환경에서도 LLM을 안정적으로 서비스할 수 있게 해줍니다.
Amazon SageMaker AI와 함께 llm-compressor 도구를 활용하면, 몇 줄의 코드로 초대형 LLM을 불과 수 시간 내에 양자화하고 실서비스에 연동할 수 있습니다. 기업 내 LLM 활용을 고려하는 조직이라면, 이와 같은 자동화된 추론 최적화 가이드를 반드시 확인해 보시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
