아마존 SageMaker AI에서 BentoML LLM-Optimizer를 활용한 LLM 추론 최적화 가이드
도입
최근 대규모 언어 모델(LLM)의 등장은 API 기반으로 손쉽게 인공지능(AI) 기능을 애플리케이션에 통합할 수 있게 해주었습니다. 하지만 여전히 많은 기업에서 자체 호스팅 모델을 선택하고 있으며, 이는 인프라 관리의 복잡성, GPU 리소스 관리, 모델 업데이트 주기의 부담 등을 감수해야 함을 의미합니다. 이 같은 선택의 주요 이유는 다음과 같습니다:
- 데이터 주권(데이터가 외부 환경으로 나가지 않도록 제어)
- 모델 커스터마이징(산업 특화 데이터셋에 맞춘 튜닝)
이 글에서는 Amazon SageMaker AI와 BentoML LLM-Optimizer를 활용하여 대규모 언어 모델 추론을 최적화하는 방법을 상세히 소개합니다. 최적 배포 구성 찾기, 성능 지표 분석, 자동화된 설정 탐색 등 실무에서 쓸 수 있는 노하우를 중심으로 설명합니다.
본론
- Amazon SageMaker AI의 활용
Amazon SageMaker AI는 자체 호스팅에 필요한 인프라 복잡성을 간소화하는 기능을 제공합니다. GPU 자원의 프로비저닝, 스케일링, 모니터링을 자동화하며, vLLM(v0.10.2) 기반의 추론 최적화 컨테이너(LMI v16)를 미리 구성하여 인프라 자동화를 지원합니다.
- BentoML LLM-Optimizer의 역할
LLM-Optimizer는 수동 튜닝 없이 다양한 구성이 성능에 미치는 영향을 자동으로 벤치마킹합니다. 이를 통해 최적의 latency와 throughput(처리량)을 유지하며 서비스 수준 목표(SLO)에 부합하는 구성을 찾을 수 있습니다.
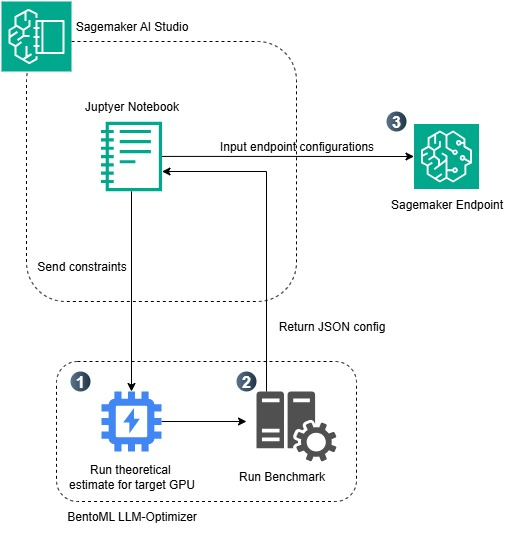
- 아키텍처 및 구성 요소
전체 워크플로우는 일반적으로 다음 3단계로 구성됩니다:
- 제약 조건 설정: 예) 5 RPS 이상, End-to-End latency < 60초
- 벤치마크 실행: tensor parallelism, 배치 크기, 시퀀스 길이 등을 조합
- 구성 배포: SageMaker의 엔드포인트에 최적의 파라미터를 자동 적용
- 주요 성능 지표 이해
- Throughput: 초당 처리 요청 수 (높을수록 좋음)
- Latency: 단일 요청에 대한 응답 시간 (낮을수록 좋음)
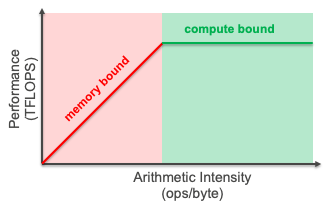
- Arithmetic Intensity: 연산량 대비 메모리 전송 비율
이를 Roofline Model로 시각화하면 어느 부분이 병목인지 파악할 수 있습니다 (메모리 vs 연산 제한 여부).
- 실전 예시: Qwen-3-4B 모델 최적화
벤치마크 조건
- 모델: Qwen/Qwen3-4B
- 인스턴스: ml.g6.12xlarge (NVIDIA L4 4개)
- 입력: 1024 토큰 / 출력: 512 토큰
- 목표: 5~10 RPS 이상
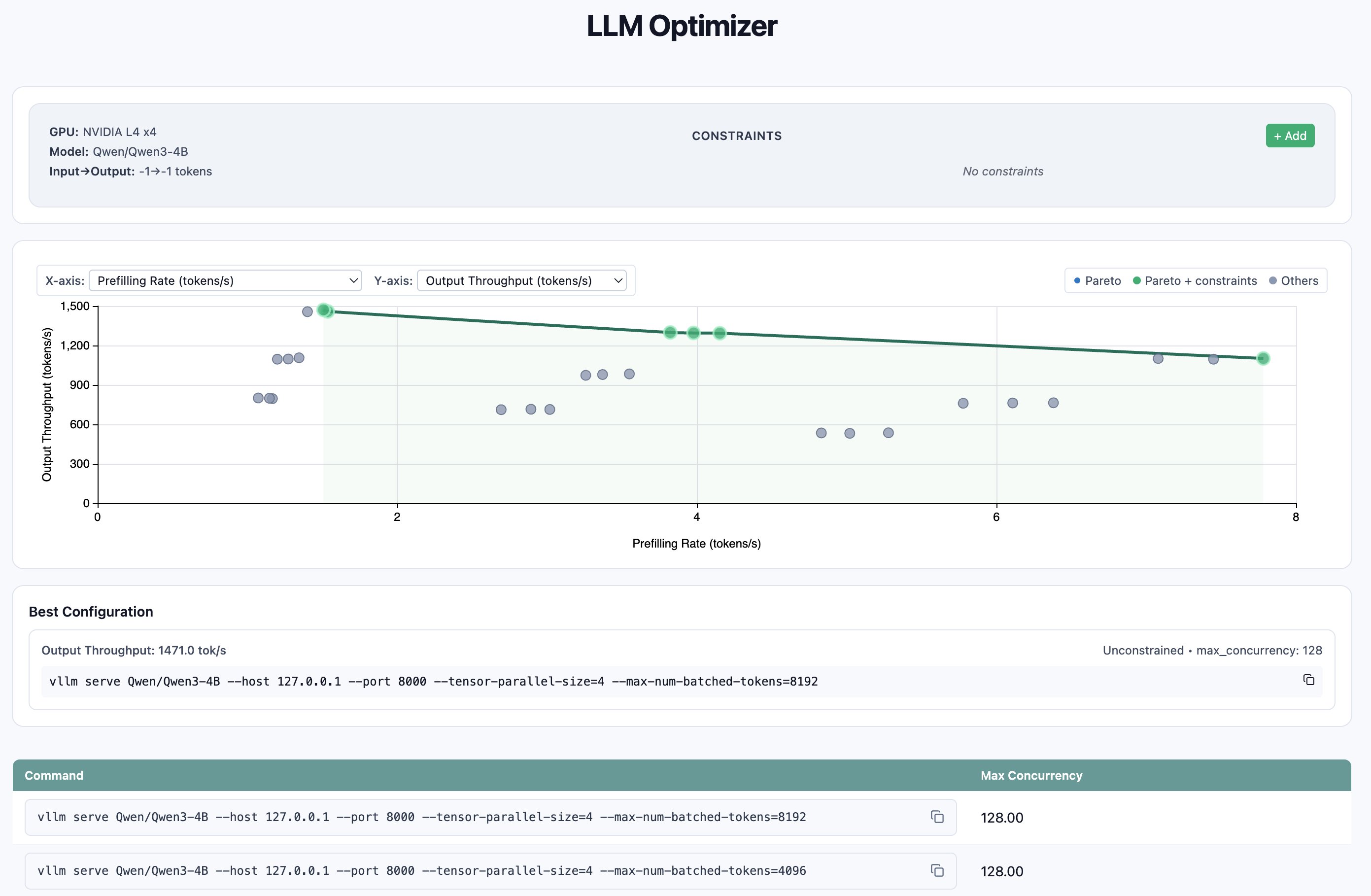
벤치마크 결과
- 최적 구성:
- tensor_parallel_size=4
- max_num_batched_tokens=8192
- max_concurrency=128
- 처리량: 7.51 RPS
- 99퍼센타일 latency: 61.4초

Latency 민감 서비스를 위한 구성(최대 24초 내):
- tensor_parallel_size=4
- max_num_batched_tokens=4096
- max_concurrency=32
- throughput: 5.63 RPS
벤치마크 대시보드 결과 시각화:
- 실제 배포
SageMaker AI로 최적화된 구성을 배포할 때는 다음과 같은 환경 변수(env)를 사용합니다:
env = {
"HF_MODEL_ID": "Qwen/Qwen3-4B",
"OPTION_ASYNC_MODE": "true",
"OPTION_ENTRYPOINT": "djl_python.lmi_vllm.vllm_async_service",
"OPTION_MAX_ROLLING_BATCH_PREFILL_TOKENS": "8192",
"OPTION_TENSOR_PARALLEL_DEGREE": "4",
}
이 값을 바탕으로 LMI 컨테이너 구성 후 SageMaker 엔드포인트에 등록하면 실시간 추론이 가능해집니다. 이 과정은 배포 자동화를 통해 몇 줄의 코드로 간단하게 이뤄집니다.
결론
LLM 모델의 실무 배치는 이제 수동적인 추측과 시행착오 대신, 데이터 기반의 자동화된 최적화 루프로 발전하고 있습니다. BentoML의 LLM-Optimizer는 다양한 구성 조합을 자동 테스트하고, Amazon SageMaker AI는 이 구성을 배포 가능한 형태로 완성하는 역할을 합니다. 단일 GPU에서 시작한 모델이, GPU 4개를 사용하는 병렬 세팅으로 이전하면서 2.7배 이상 향상된 처리 성능을 보였으며, 이는 실질적인 비용 절감과 사용자 경험 향상을 의미합니다.
이처럼 자동화된 벤치마크와 관리형 추론 인프라의 조합은 AI 기술의 확산과 기업 내 활용을 가속화하는 중요한 동력이 될 것입니다. 궁극적으로 가장 좋은 구성은 ‘가장 빠른 속도’가 아니라, ‘목표한 지연 시간과 비용 조건을 만족하는 구체적인” 구성입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
