기업을 위한 음성 기반 AI, Mistral Voxtral 모델을 Amazon SageMaker에서 배포하는 방법
최근 음성 및 텍스트를 동시에 처리할 수 있는 멀티모달 인공지능 모델이 주목받고 있습니다. 특히, Mistral AI에서 개발한 Voxtral 시리즈는 단일 프레임워크 내에서 고도화된 음성-텍스트 이해를 제공하며, 자동 언어 감지, 긴 오디오 문맥 처리, 함수 호출 지원 등 다양한 기능을 제공합니다. 본 글에서는 이러한 Voxtral 모델을 Amazon SageMaker AI 위에 효율적으로 배포하고 테스트하는 자동화된 가이드를 소개합니다.
Voxtral 모델이란?
Mistral AI의 Voxtral은 음성과 텍스트를 통합 처리할 수 있는 멀티모달 모델입니다. 주요 특징은 다음과 같습니다.
- 자동 언어 감지 및 최대 40분 분량 오디오 입력 지원
- 최대 32,000 토큰까지 문맥 유지
- 오디오로부터 감정 및 의미 추출 가능
- 오디오 기반으로 함수 호출 가능 (예: “144의 제곱근을 구해줘” → 계산 도구 자동 실행)
두 가지 버전이 제공됩니다:
- Voxtral-Mini-3B-2507 : 3B 파라미터의 경량 모델(빠른 속도, 적은 리소스)
- Voxtral-Small-24B-2507 : 24B 파라미터의 모델(고성능 챗, 음성 기반 함수 호출 등 지원)
SageMaker를 활용한 배포 구조
SageMaker에서는 BYOC(Bring Your Own Container) 기능을 이용해, Voxtral 모델을 사용자 정의 컨테이너에 담아 배포합니다. 이 컨테이너는 vLLM 프레임워크 위에 구성되며, 모델 실행에 필요한 오디오 특화 라이브러리(librosa, soundfile, pydub)와 토크나이저 라이브러리(mistral_common)를 포함하고 있습니다.
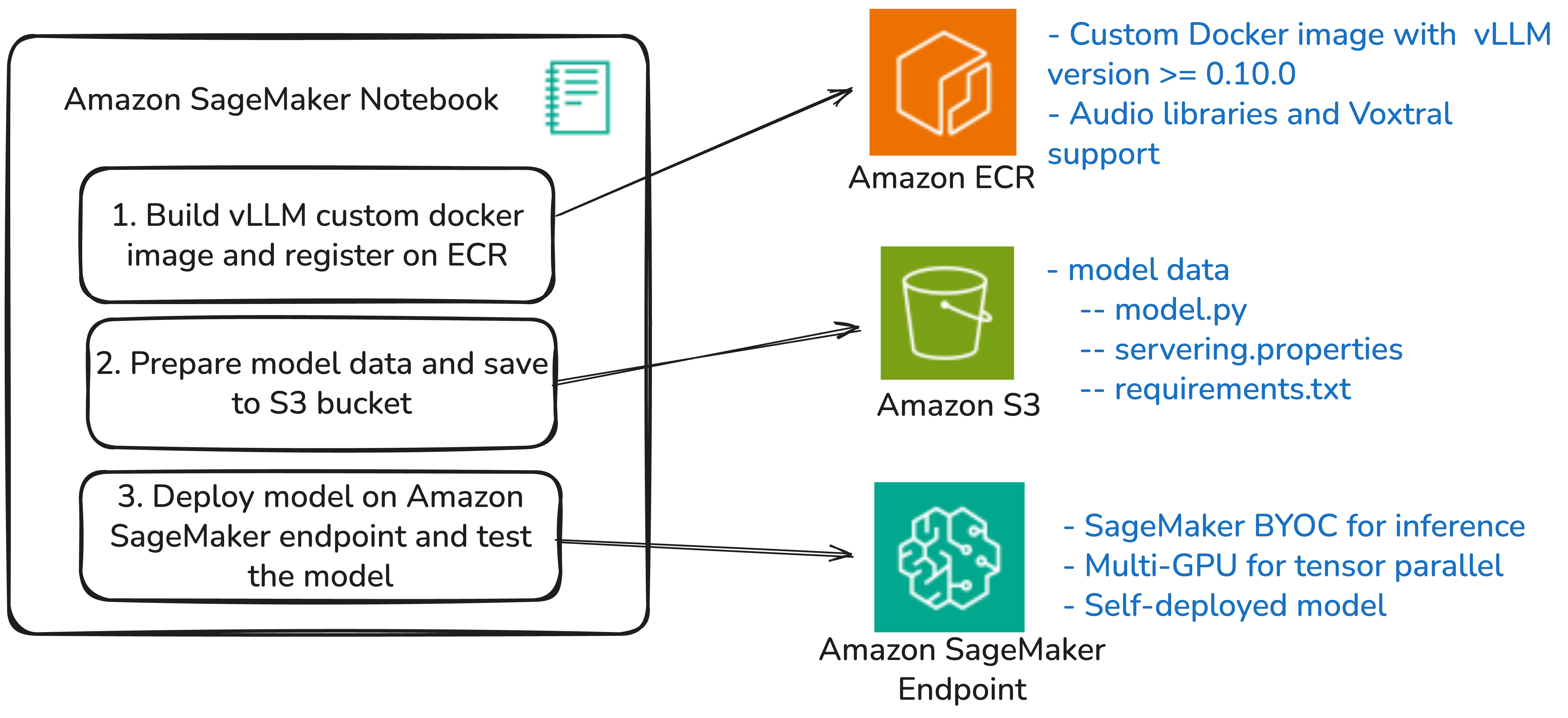
이 아키텍처는 다음의 구성 요소로 조합됩니다:
- SageMaker Notebook: 배포 자동화와 테스트
- Amazon ECR: 사용자 정의 컨테이너 이미지 저장소
- Amazon S3: 모델 설정 파일(model.py, serving.properties, requirements.txt) 저장소
- SageMaker Inference Endpoint: 모델 서비스 실행 공간
배포 절차 요약
- GitHub에서 코드 복제 및 폴더 이동
- 빌드 스크립트 실행하여 컨테이너 이미지 생성 및 ECR에 푸시
- serving.properties 파일 구성 (Voxtral-Mini 또는 Small 설정 택일)
- SageMaker 노트북(Voxtral-vLLM-BYOC-SageMaker.ipynb) 실행
자동화된 컨테이너 구성 및 확장성
컨테이너 내부는 빠른 모델 로딩을 위해 SageMaker 환경 변수와 캐시위치를 명확히 설정합니다. 오디오 처리와 모델 추론 시 독립적인 설정 파일(serving.properties)을 통해 유연하게 옵션을 조정합니다. 예를 들어, 모델 버전(Voxtral-Mini/Small) 변경 시에도 이미지 재빌드 없이 단순 설정만 수정하면 됩니다.
모델 설정 예시:
- model_id: mistralai/Voxtral-Small-24B-2507
- tensor_parallel_degree: 4
- tokenizer_mode, load_format: “mistral”
- audio_sampling_rate: 16000
- limit_mm_per_prompt=audio:8 → 한 요청당 최대 8개의 오디오 파일 사용 가능
활용 시나리오
Voxtral은 다음과 같은 다양한 활용을 지원합니다.
- 텍스트 응답형 챗봇
- 회의 자동 음성 기록 및 분석
- 콜센터 인사이트 추출 시스템
- 다국어 음성 인터페이스 및 함수 핸들링
활용 예제: 오디오 기반 날씨 정보 요청
사용자가 음성으로 “서울 날씨 알려줘”라고 하면, 모델은 자동으로 해당 도구를 호출하고 응답을 제공합니다.
Strands Agent와의 통합
Strands Agents 프레임워크를 활용하면, Voxtral 모델을 에이전트화하고 다양한 도구(calculator, shell 등)를 결합하여 복잡한 멀티 스텝 작업도 자연어로 처리할 수 있습니다. SageMaker API와 연동되는 구조로, 최소한의 코드 작성만으로도 자동화된 에이전트를 구성할 수 있습니다.
SageMaker 배포 시 고려사항
- 최소 요구사항: ml.g6.4xlarge (Voxtral-Mini), ml.g6.12xlarge (Voxtral-Small)
- IAM 권한: EC2InstanceProfileForImageBuilderECRContainerBuilds 정책 필요
- SageMaker 자원 할당량: 사용 전 사전 할당량 요청 필요
결론
Voxtral 모델은 고성능 멀티모달 AI를 구축하고자 하는 기업에게 뛰어난 선택입니다. 이번 포스트에서 소개한 BYOC 방식과 vLLM 서버 통합을 통해 텍스트-음성 혼합 AI 시스템을 빠르고 유연하게 구축할 수 있습니다. 회의 기록 자동화, 콜센터 음성 분석, 음성 기반 어시스턴트 등 실무 활용 사례에 바로 도입할 수 있는 강력한 구조입니다.
지금 GitHub에서 전체 코드를 다운로드하고 여러분만의 음성 인텔리전스 애플리케이션을 구현해 보십시오!
https://aws.amazon.com/blogs/machine-learning/deploy-mistral-ais-voxtral-on-amazon-sagemaker-ai/
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
