머신러닝 인프라 효율의 정점, SageMaker HyperPod의 Elastic Training
머신러닝(ML) workloads의 다양성과 대규모 AI 모델 학습 수요가 급증함에 따라, 더 이상 고정된 자원 할당으로는 클러스터 인프라를 효율적으로 운영하기 어렵습니다. 특히 사전 학습(Pre-training), 파인튜닝(Fine-tuning), 추론(Inference) 등 다양한 워크로드가 동시에 구동되는 환경에서는 자원 수요가 시간대와 트래픽에 따라 계속해서 변합니다. 이에 대응하기 위해 Amazon SageMaker HyperPod는 Elastic Training 기능을 도입했습니다. 이를 통해 학습 작업은 가용한 자원에 따라 자동으로 확장하거나 축소되며, 비용 절감, 자원 효율 향상, 빠른 모델 배포 등 다양한 이점을 제공합니다.
Elastic Training의 필요성과 등장 배경
예를 들어, 256 GPU 클러스터에서 야간 비사용 시간에 추론 작업이 축소되어 96개의 GPU가 유휴 상태로 남을 수 있습니다. 전통적인 고정 자원 할당 방식에서는 이 유휴 자원이 적절히 활용되지 못하고 그대로 낭비됩니다. 이러한 비효율성은 클러스터 규모가 커질수록 심화되며, 하루 수천 달러의 비용 손실로 이어질 수 있습니다.
무엇보다 기존 방식에서는 자원을 동적으로 조절하려면 수동 개입이 불가피했습니다. 학습 작업 중단, 파라미터 재조정, 체크포인트 분할 저장 등 복잡한 프로세스를 거쳐야 하므로, ML 엔지니어의 업무 효율을 심각히 저해합니다.
Elastic Training은 이러한 문제를 자동화로 해결합니다. SageMaker HyperPod에서는 자동 스케일링을 지원하며, PyTorch, NeMo 등 주요 프레임워크와의 연동을 통해 트레이닝 품질을 유지하면서도 유연하게 리소스를 조절할 수 있습니다.
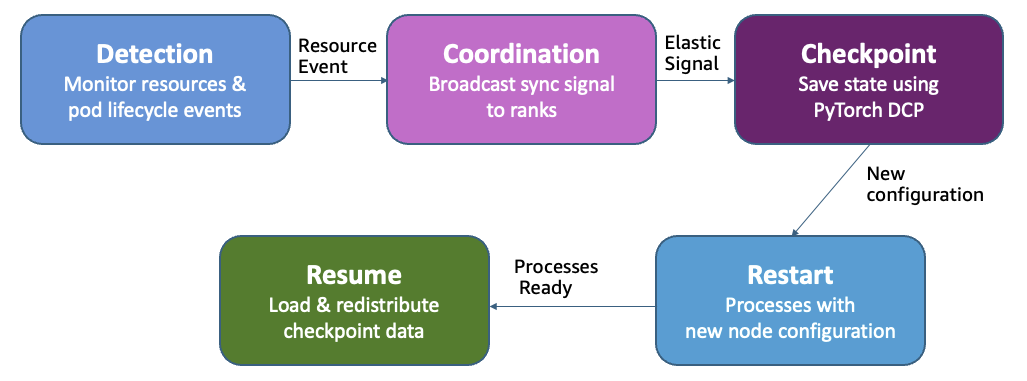
Elastic Training 작동 방식 분석
Elastic Training은 학습 중 자원이 추가되면 해당 자원을 자동으로 할당하고, 우선순위가 높은 작업에 자원을 넘겨줄 경우에는 일부 replica만 제거하여 전체 작업을 중단하지 않고도 축소가 가능합니다. 전체 학습 과정을 PyTorch Distributed Checkpoint(DCP)를 통해 체크포인트 저장 및 불러오기를 수행하며, 이는 스케일 간에도 학습 상태의 일관성을 유지합니다.
이러한 구조는 아래와 같은 방식으로 작동합니다:
- 스케일링 이벤트가 발생하면 training operator가 동기 신호를 모든 노드에 전달합니다.
- 각 노드는 학습을 일시 저장한 후 종료.
- 변경된 replica 수에 맞춰 랭크를 재할당하고 학습을 재시작.
- DCP를 통해 모델과 옵티마이저 상태를 불러오고 학습을 재개.
또한, SageMaker HyperPod는 우선순위 기반 리소스 스케줄링 프레임워크(Kueue)를 활용하여, 부분 자원 선점(partial preemption)을 자동 처리합니다.

Elastic Training 설정 및 구축 가이드
Elastic Training 기능을 배포하려면 다음과 같은 사전 조건이 필요합니다:
- Kubernetes v1.32 이상에서 Amazon EKS 기반의 SageMaker HyperPod 클러스터 구성
- HyperPod training operator v1.2 이상 설치
- 작업 큐 관리 및 우선순위 정책 구현을 위한 Task Governance v1.3.1 이상
Karpenter와 같은 클러스터 오토스케일러를 사용할 경우, Namespace 단위로 ResourceQuota를 설정해 과도한 자원 요청 예방이 필요합니다. 이를 통해 자동화 범위 내에서 자원 사용량 제어가 가능합니다.
Elastic Agent 패키지를 설치하고, 기존 PyTorch 학습 실행 명령을 hyperpodrun으로 대체합니다:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected
def train_epoch(...):
for ...:
loss = ...
should_checkpoint = (batch_idx + 1) % checkpoint_freq == 0
elastic_event = elastic_event_detected()
if should_checkpoint or elastic_event:
save_checkpoint(...)
if elastic_event:
return
확장 대비 정확도 유지를 위해 DCP 기반 checkpoint 저장/복구 함수를 구현해야 하며, 배치 데이터를 정확히 재사용하기 위해 Stateful Dataloader도 도입할 수 있습니다.
Elastic Training Job 제출 가이드
Elastic Training 작업은 HyperPodPyTorchJob을 통해 정의되며, 다음과 같은 정책을 포함합니다:
- 최소/최대 replica 수 정의
- 증분 확장 방식 또는 특정 노드 수만 허용
- graceful shutdown 타임아웃으로 체크포인트 시간 확보
- 스케일링 이벤트 지연 정책을 통한 시스템 안정성 확보
elasticPolicy:
minReplicas: 2
maxReplicas: 8
replicaIncrementStep: 2
scalingTimeoutInSeconds: 60
SageMaker HyperPod Recipe를 활용하면 GPT-OSS, Llama 등의 오픈소스 모델 학습에서도 코드 변경 없이 elastic 설정만 별도 yaml에서 조정 가능하여 굉장히 빠르게 배포 가능합니다.
Elastic Training 성능 Benchmark
Llama-3 70B 모델을 최대 8노드의 ml.p5.48xlarge 인스턴스 기반 HyperPod 클러스터에서 학습한 결과, 1노드 당 2,000 token/sec, 8노드에서는 14,000 token/sec으로 처리량이 직선적으로 향상됨을 확인했습니다. 학습 손실(loss)은 지속적으로 감소하며 모델 수렴도 보장됩니다.


결론: AI 인프라 자동화의 키, Elastic Training
Elastic Training은 고정 자원 구조로는 해결할 수 없는 AI 인프라의 비효율 문제를 해결합니다. 자동화된 동적 스케일링은 다음과 같은 주요 이점을 제공합니다:
- 운영 측면: 지속적인 자원 수동 설정 불필요 → ML 개발팀 생산성 향상
- 비용 측면: GPU 시간 활용률 증가 → 운영 비용 대폭 절감
- 비즈니스 측면: AI 모델 개발 및 배포 속도 향상 → 타임투마켓 단축
SageMaker HyperPod를 기반으로 구축된 이 체계는 반복적인 수작업 없이, 머신러닝 학습 작업의 자원 활용을 극대화하고 기업의 AI 자동화 수준을 한 단계 끌어올릴 수 있는 강력한 수단으로 자리매김할 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
