체크포인트 없는 학습 방식, Amazon SageMaker HyperPod에서 대규모 기본 모델 학습을 자동화하는 새로운 방법
소개
오늘날의 기본 AI 모델 학습은 수십억에서 수조 개의 파라미터를 포함하며, 수천 개의 AI 가속기에서 수주에서 수개월 동안 진행되는 고비용·고성능 작업입니다. 이처럼 대규모 분산 환경에서는 단 한 개의 GPU 오류나 네트워크 문제도 전체 학습 작업을 중단시키며 수천만 원대의 손실을 유발할 수 있습니다. 기존의 체크포인트 기반 복구 방식은 주기적으로 모델 상태를 저장하고 오류 발생 시 해당 시점으로 되돌리는 방식이지만, 작업 규모가 커질수록 저장 및 재시작에 필요한 시간이 늘어나고 비용도 가중됩니다.
Amazon은 이런 병목을 해결하기 위해 Amazon SageMaker HyperPod에서 ‘체크포인트 없는 학습(Checkpointless Training)’을 도입했습니다. 이 방식은 학습 상태를 피어 간에 실시간으로 복제(Peer-to-peer state replication)하여 오류 발생 시 빠르게 복구할 수 있도록 설계되었으며, 특히 높은 수준의 자동화 및 복원력을 제공합니다.
본문
체크포인트 방식의 병목 구조
기존의 분산 학습 환경에서는 모델 상태(모델 파라미터, 옵티마이저, 데이터 로더 상태 등)를 주기적으로 저장하고 장애 발생 시 이 상태를 다시 불러와 재시작하는 방식이 표준이었습니다. 하지만 이러한 복구는 다음과 같은 여러 병목을 포함합니다:
- 모든 노드의 프로세스를 강제 종료 후 다시 시작
- 통신 설정 및 네트워크 연결 재설정
- S3 또는 파일 스토리지에서 상태 정보를 다시 불러오는 과정
- CUDA 컨텍스트 초기화, 데이터 로더 재설정
- 마지막 체크포인트 이후 계산된 작업의 손실 및 재계산
256대의 ml.p5.24xlarge 인스턴스로 구성된 클러스터에서 20분마다 체크포인트를 걸고, 중간에 장애가 발생하면 약 10분의 작업 손실 + 10분의 복구 시간 = 총 20분의 지연이 생깁니다. 인스턴스당 시간당 $55의 비용을 고려하면 단일 오류 발생으로 4693달러의 손해가 발생하며, 한 달간 매일 이런 오류가 반복되면 약 14만 달러의 추가 비용이 발생하게 됩니다.
체크포인트 없는 학습의 구조 및 자동화 구성 요소
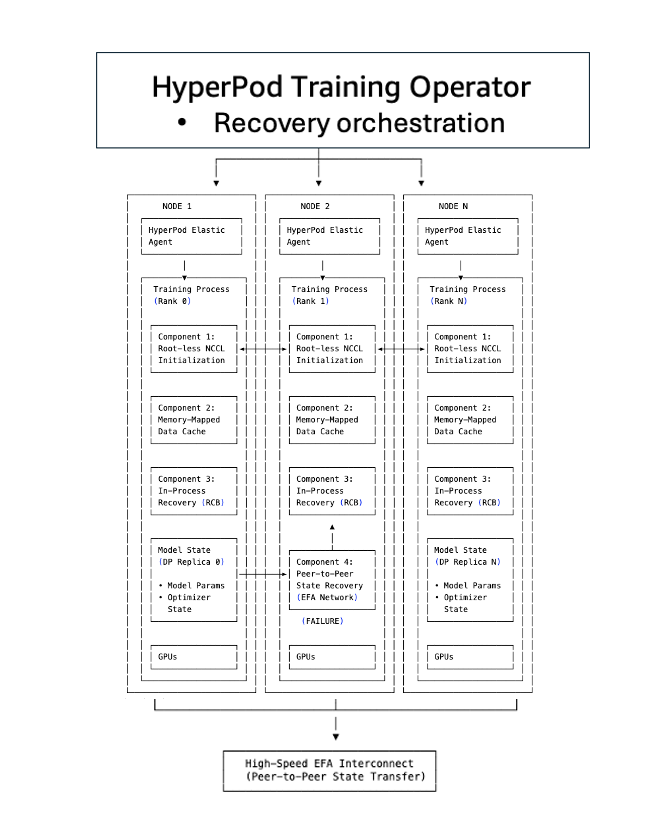
SageMaker HyperPod의 체크포인트 없는 학습은 총 5개의 핵심 구성 요소를 기반으로 하여 기존 체크포인트 복구의 병목을 제거합니다.
-
TCPStore 제거 및 루트 없는 NCCL 초기화
- 모든 노드가 루트 프로세스를 거치지 않고 동등하게 피어를 탐색합니다.
- 대규모 클러스터에서도 수 초면 네트워크 연결이 완료됩니다.
-
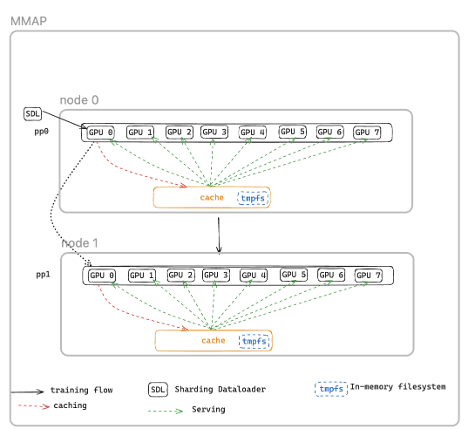
메모리 맵 기반 데이터 로딩(MMAP)
- 데이터셋이 공유 메모리 캐시에 보존되어 재시작 시 디스크 재로드 없이 즉시 학습 재개가 가능합니다.
-
인프로세스 복구
- 오류가 발생한 프로세스만 부분적으로 재시작하며 전체 작업은 중단되지 않습니다.
- CUDA 컨텍스트 및 환경 초기화를 생략할 수 있어 복구 시간을 수 분 단위에서 초 단위로 단축합니다.
-
피어 간 상태 복제
- Amazon S3나 NFS에서 데이터를 불러오는 대신, 정상 노드에서 모델 상태를 직접 가져옵니다.
- 네트워크를 통한 복제만으로 수 초 내 복구가 가능하며 I/O 병목이 제거됩니다.
-
HyperPod 전용 오퍼레이터
- 전체 복구 흐름을 자동으로 오케스트레이션하며, 프로세스 수준 복구와 클러스터 상태 모니터링을 자동화합니다.
- 장애 노드가 발생하면 핫 스페어 노드를 자동 교체 사용하여 중단을 방지합니다.
적용 가이드 및 티어별 구성 단계
체크포인트 없는 학습은 단계적으로 적용 가능하도록 설계되어 있습니다:
- 1단계: 루트 없는 초기화 (환경 변수 설정만으로 적용)
- 2단계: 메모리 맵 데이터 로딩 (기존 데이터 로더에 MMAP 모듈 추가)
- 3단계: 인프로세스 복구 (기존 학습 루프라핑으로 처리)
- 4단계: 체크포인트 제거 및 피어 간 복제 (NeMo와 연결된 GPT/Llama 파이프라인에서 자동 대응)
자동화 코드는 PyTorch와 PyTorch Lightning에서 바로 적용할 수 있으며, NVIDIA NeMo 사용 시 Tier 4 설정까지 기본 탑재 상태로 지원됩니다.
운영 성능 및 비교 결과
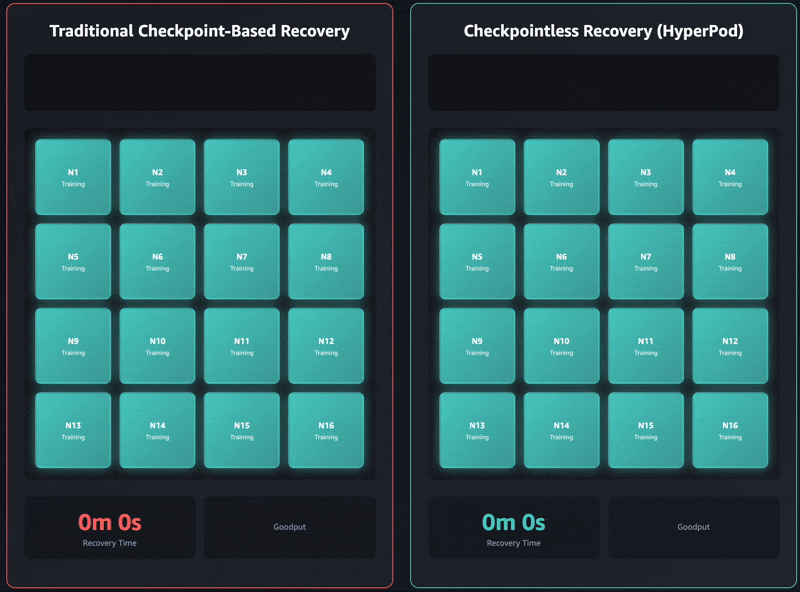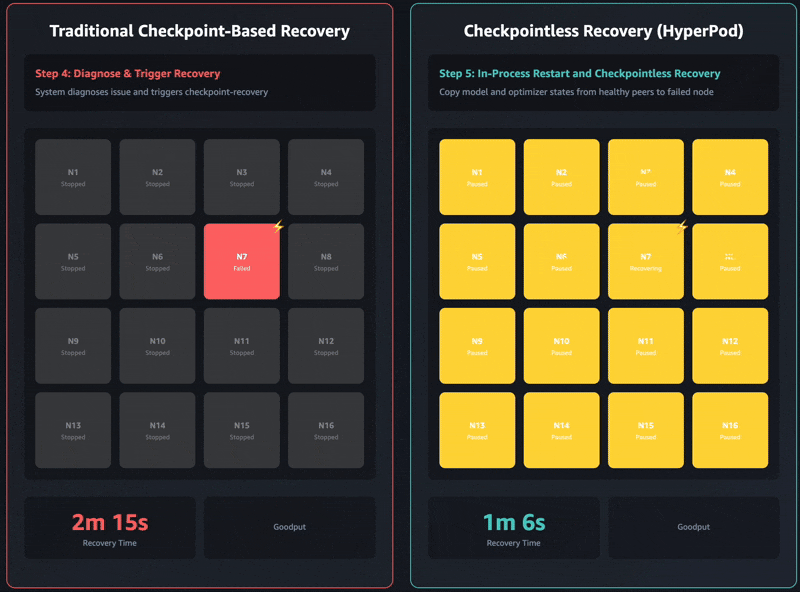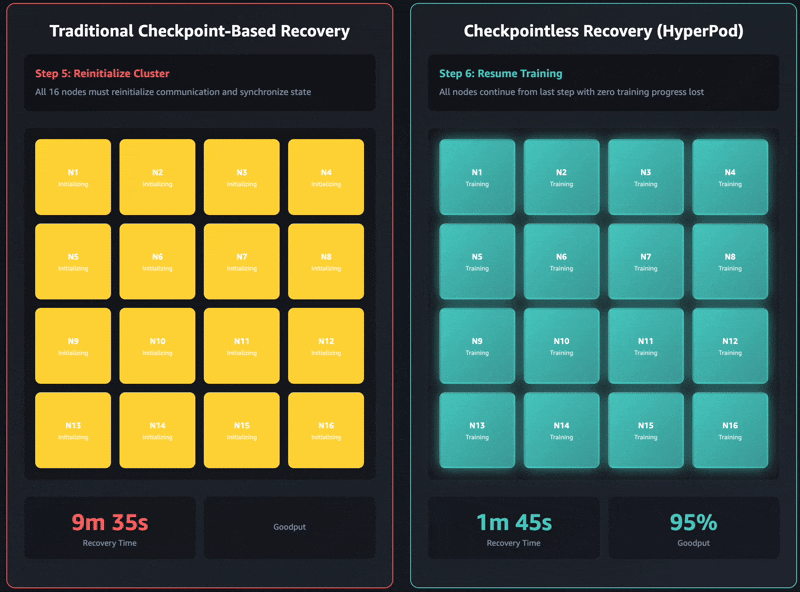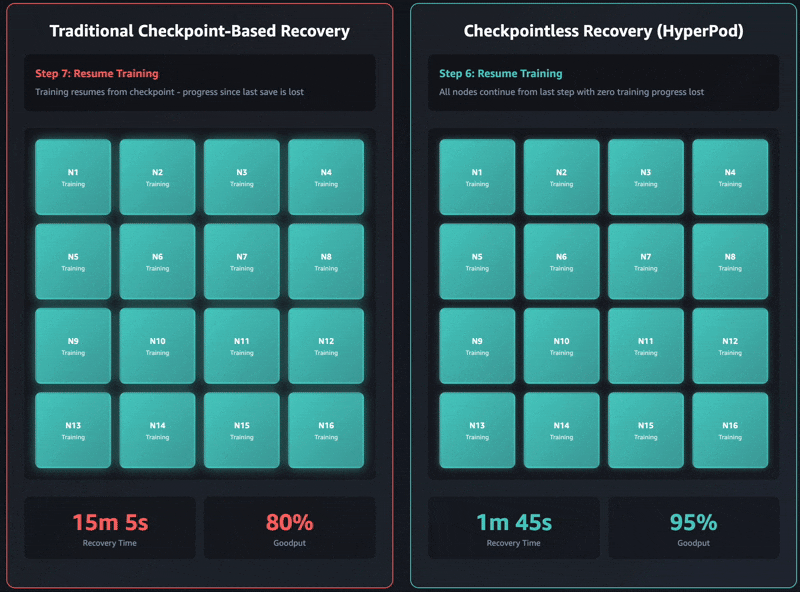
아래는 기존 체크포인트 복구 대비, 체크포인트 없는 복구 속도 비교입니다:
- 2304 GPU 클러스터에서: 15
30분 → 2분 이내 (93% 개선) - Llama-3 70B 모델 학습 시: 약 5분 → 47초 (~84% 개선)
- GPU 16개 소규모 클러스터에서도 안정적인 성능 개선 관찰
이러한 개선은 단순히 충돌에서의 복구 시간 절감을 넘어서, 전체 학습 시간의 'Goodput'(실제 유효한 연산 시간)을 95% 이상으로 높이는 데 기여합니다.

결론
대규모 AI 학습 작업에서 '체크포인트 없는 학습'은 더 빠른 복구, 자동화된 오류 대응, I/O 비용 절감이라는 세 가지 핵심 이점을 제공합니다. 특히 SageMaker HyperPod에서의 통합 운영은 최소 인프라 오버헤드로 최대 자동화/대응 성능을 보장하며, 사용자의 파이프라인 복잡도를 낮추고 DevOps 효율성을 극대화합니다.
기존의 “빠르게 재시작하자(Recover Fast)” 접근이 아닌, “아예 중단되지 말자(Avoid Stopping Altogether)”라는 사고의 전환이 필요한 시점입니다. SageMaker HyperPod 및 체크포인트 없는 학습 도입으로 경쟁력 높은 AI 학습 인프라를 갖추어 보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
