머신러닝 훈련에서 Amazon S3 데이터 로딩 최적화를 위한 실전 가이드
클라우드 기반 머신러닝(ML) 훈련 시 가장 큰 병목 중 하나는 데이터를 GPU에 적시에 공급하는 것입니다. 고성능 GPU를 도입해도 데이터 전달이 느리다면 훈련 성능은 제자리걸음일 수밖에 없습니다. 본 포스팅에서는 Amazon S3를 데이터 소스로 사용할 때 최대한의 처리량을 유지하면서 효율적인 모델 훈련을 가능하게 하는 데이터 로딩 방식과 자동화 기술, 그리고 실전 배포에 유용한 활용 사례들을 소개합니다.
S3에서 발생하는 병목 지점과 데이터 입출력 패턴 이해
일반적으로 ML 훈련 파이프라인은 다음과 같은 네 단계로 구성됩니다:
- S3 등에서 데이터를 읽어 메모리로 로딩
- 이미지 등의 데이터를 디코딩·변환하는 전처리 작업
- GPU에서 모델 가중치 학습 및 업데이트
- 체크포인트 저장으로 훈련 상태 보존
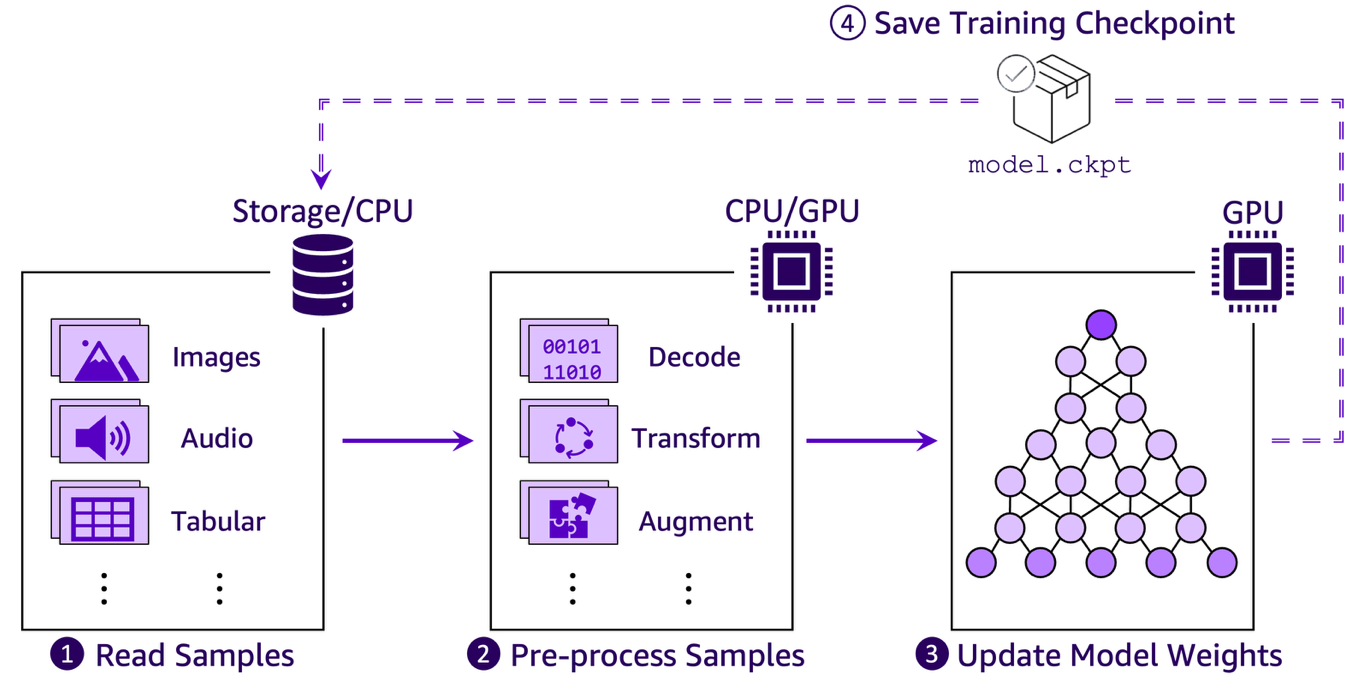
이 중 S3에서 데이터를 불러오고 전처리하는 1~2단계가 특히 클라우드 환경에서는 병목 지점으로 자주 등장합니다. 원하는 훈련 속도를 확보하기 위해서는 S3 데이터 접근 방식 자체를 구조적으로 최적화해야 합니다.
랜덤 vs 순차 접근 패턴: 처리량 차이는 왜 생길까?
Amazon S3는 요청당 고정 지연(TTFB, Time-To-First-Byte)을 수반하며, 소규모 파일을 다수 호출할 경우 지연이 누적되어 훈련 속도에 악영향을 줍니다. 이는 마치 하드 디스크에서 이곳저곳 점프하면서 데이터를 읽는 것과 유사합니다.
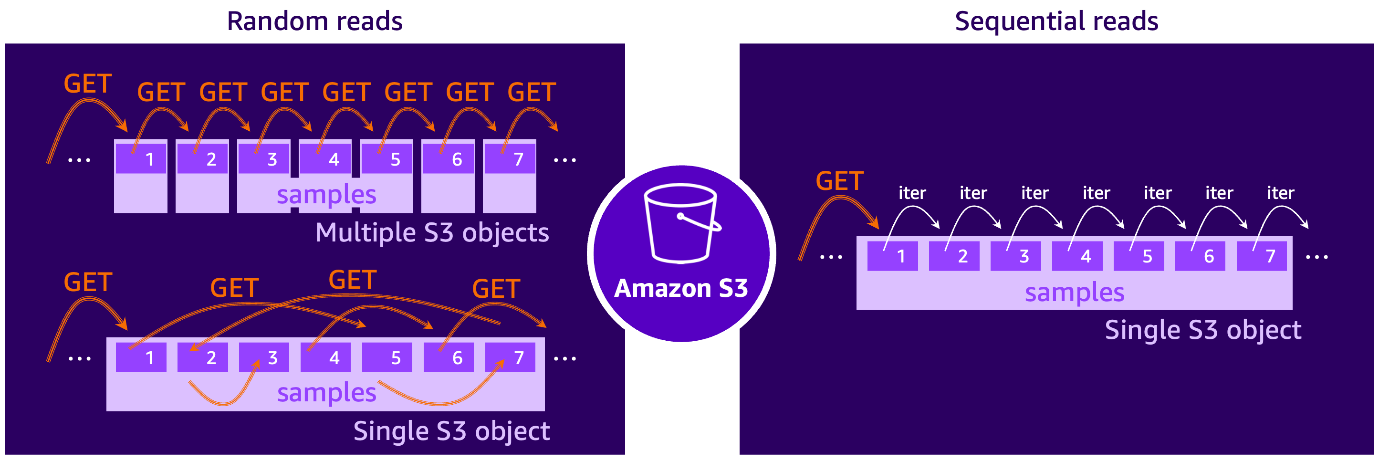
반면 대규모 샤딩(sharding)을 통해 데이터를 연속적으로 저장하고 한 번의 요청으로 다량의 샘플을 가져오는 순차 접근 방식이라면 TTFB 지연이 최소화되며 높은 처리량이 보장됩니다.
최적의 사용법: 성능 향상을 위한 데이터 샤딩 및 최적화된 클라이언트 활용
- 데이터 샤딩 적용
S3에서 작은 이미지 파일을 하나씩 랜덤하게 읽기보다, 여러 샘플을 하나의 파일 shard(예: tar, TFRecord 등)로 묶아 저장하는 것이 바람직합니다. AWS 실험 결과에 따르면 shard 크기를 100MB~1GB로 구성하면 가장 우수한 처리량을 보였습니다.
- 고성능 S3 클라이언트 사용
- Mountpoint for Amazon S3: 로컬 파일 시스템처럼 S3를 마운트하며 변경 없는 코드로도 사용 가능
- Amazon S3 Connector for PyTorch: PyTorch용 기본 데이터 로더와 통합되며 체크포인트 저장 등도 효율적으로 자동화
- Mountpoint CSI Driver: 쿠버네티스 환경에서 컨테이너가 S3를 볼륨처럼 다룰 수 있도록 함
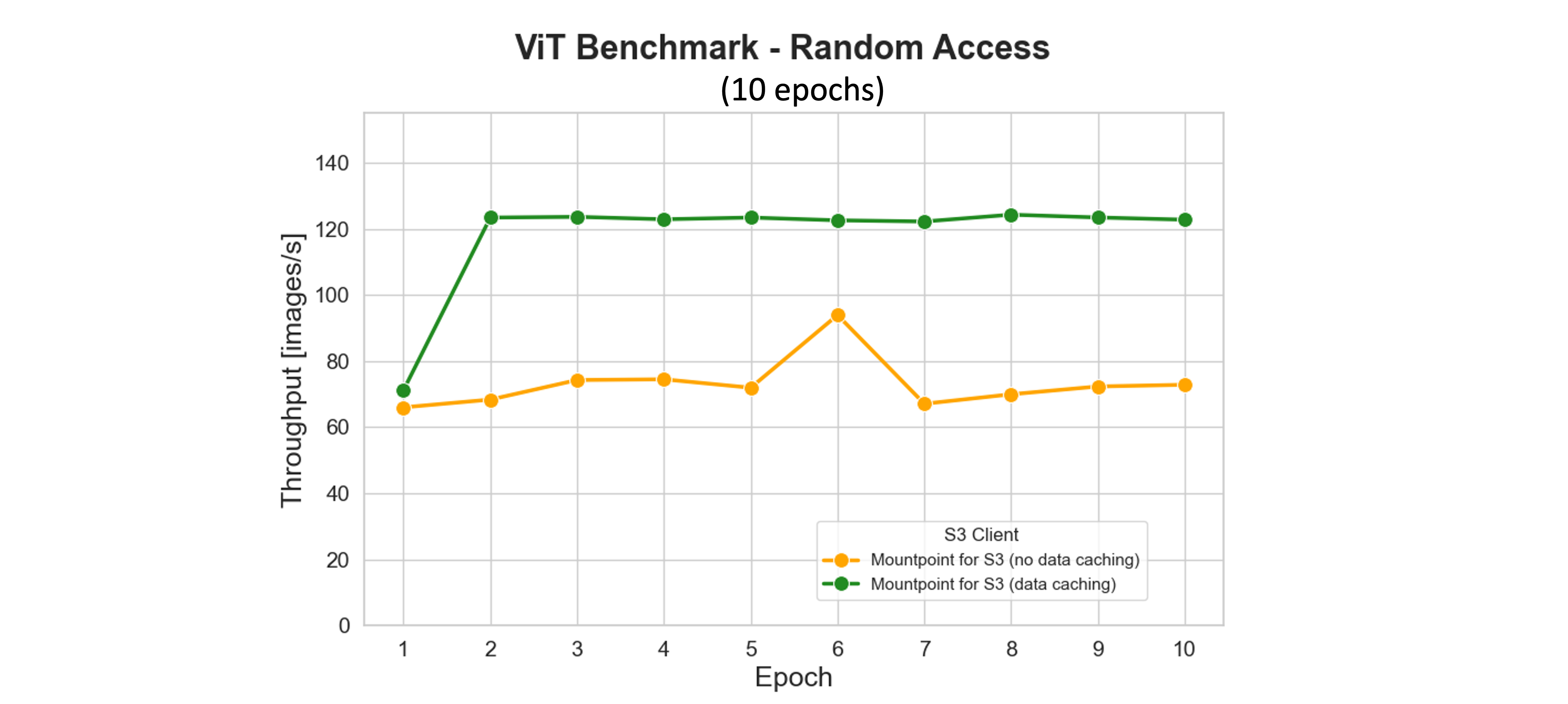
이 중 S3 Connector for PyTorch는 처리량 측면에서 가장 우수한 성능을 제공하며, 많은 병렬 worker 환경에서도 CPU 자원을 상대적으로 덜 사용하기 때문에 더 많은 학습 단계에 집중할 수 있습니다.
- 캐싱과 프리패칭 기술 활용
특히 여러 번 같은 데이터를 처리하는 multi-epoch 훈련에서는 반복적으로 S3에서 데이터를 다시 읽는 대신 SSD 등에 로컬 캐싱하면 네트워크 지연을 없앨 수 있습니다. Mountpoint는 이를 자동으로 처리하며 자주 쓰는 데이터를 우선 보존합니다. 또한 프리패칭(prefetch)을 통해 GPU에 필요한 데이터를 미리 준비해 GPU 사용률을 최대로 끌어올릴 수 있습니다.
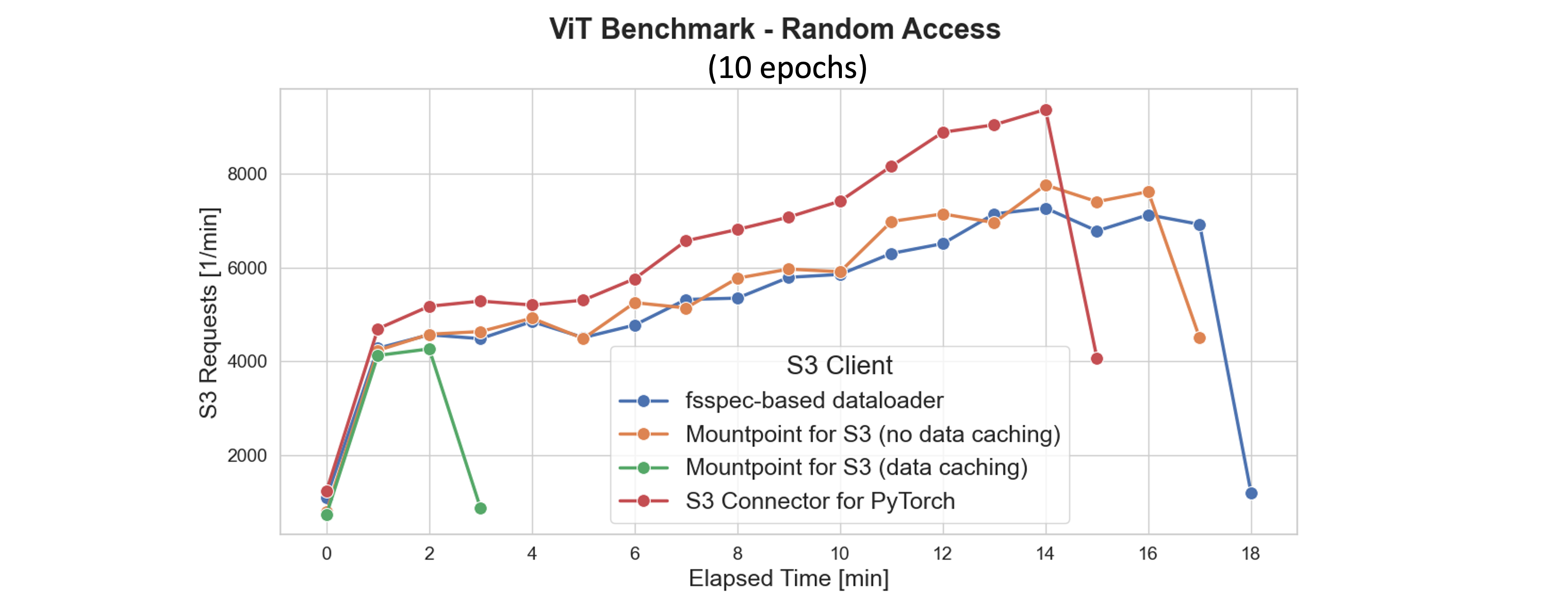
실험으로 본 성능 변화: S3 순차 vs 랜덤 접근 시 실제 차이
실험 환경: NVIDIA A10G GPU, 100,000개 JPEG 이미지 (~10GB) S3에 저장
- 랜덤 접근 (각 이미지 요청): 처리량은 S3 클라이언트 및 worker 수 조정에 따라 극명하게 차이 발생
- 순차 접근 (tar 형태로 large shard 구성): 작은 shard(4MB)부터 큰 shard(256MB)까지 GPU 사용률은 일정하게 100% 유지하며 최상의 처리량 보장
S3 Connector는 특히 대용량 shard에서 샘플 처리율이 12,000 samples/sec 이상으로 타 클라이언트를 압도했습니다.
결론
클라우드 기반 ML 환경에서 GPU 리소스를 효율적으로 활용하려면 데이터 파이프라인의 설계가 핵심입니다. S3에서 대량의 학습 데이터를 불러올 때 무작정 작은 파일을 증설하기보다 Sharding, 고성능 클라이언트 활용, 캐싱, 프리패칭 등을 통한 시스템 최적화가 필요합니다. 특히 자동화된 S3 접근 구조와 효율적인 파일 구성은 비용 절감과 훈련시간 단축이라는 두 마리 토끼를 잡을 수 있는 필수 전략입니다.
앞으로의 모델 훈련 과정에서도 다양한 작업 환경에 맞는 맞춤형 데이터를 설계하고, 도구들의 기능을 실무에 효과적으로 배치하기 위한 꾸준한 튜닝과 가이드는 필수가 될 것입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
