아마존 SageMaker HyperPod의 Managed Tiered KV Cache와 Intelligent Routing 기능으로 LLM 추론 최적화하기
AI 및 생성형 언어 모델의 적용이 증가하면서 고성능 모델 추론을 위한 인프라 아키텍처의 중요성이 나날이 커지고 있습니다. 특히 대규모 언어 모델(LLM)을 활용한 긴 문서 처리나 멀티턴 대화 시, Context가 길어짐에 따라 추론 지연(Latency)과 비용이 급격히 증가하는 것이 큰 문제였습니다. 이러한 문제를 해결하기 위해 Amazon SageMaker HyperPod는 새로운 기능인 Managed Tiered KV Cache와 Intelligent Routing 기능을 도입했습니다. 이번 글에서는 이 두 기능의 작동 원리, 활용 사례, 배포 가이드와 자동화 구성, 그리고 성능 비교를 간결하게 정리해드립니다.
KV 캐시와 Intelligent Routing이란?
LLM은 토큰을 생성할 때 기존의 모든 토큰에 대해 다시 Attention 연산을 수행하므로, 문장이 길수록 추론 시간이 지연되고 비용이 상승합니다. 이를 해결하기 위해 Key-Value(KV) 캐시가 도입되었습니다. KV 캐시는 이전 연산의 결과를 저장하고 재사용함으로써 모든 토큰을 매번 재계산하지 않게 만들어 추론 지연(Time-to-First-Token, TTFT)을 크게 줄이고 전체 처리량을 높여줍니다.
Intelligent Routing은 동일한 프롬프트나 컨텍스트를 갖는 요청을 동일한 인퍼런스 인스턴스로 라우팅하여 KV Cache를 최대한 재사용하는 방식입니다. 이 기술은 특히 프롬프트가 반복되는 문서 분석이나 다중 턴의 대화형 애플리케이션에 유용합니다.
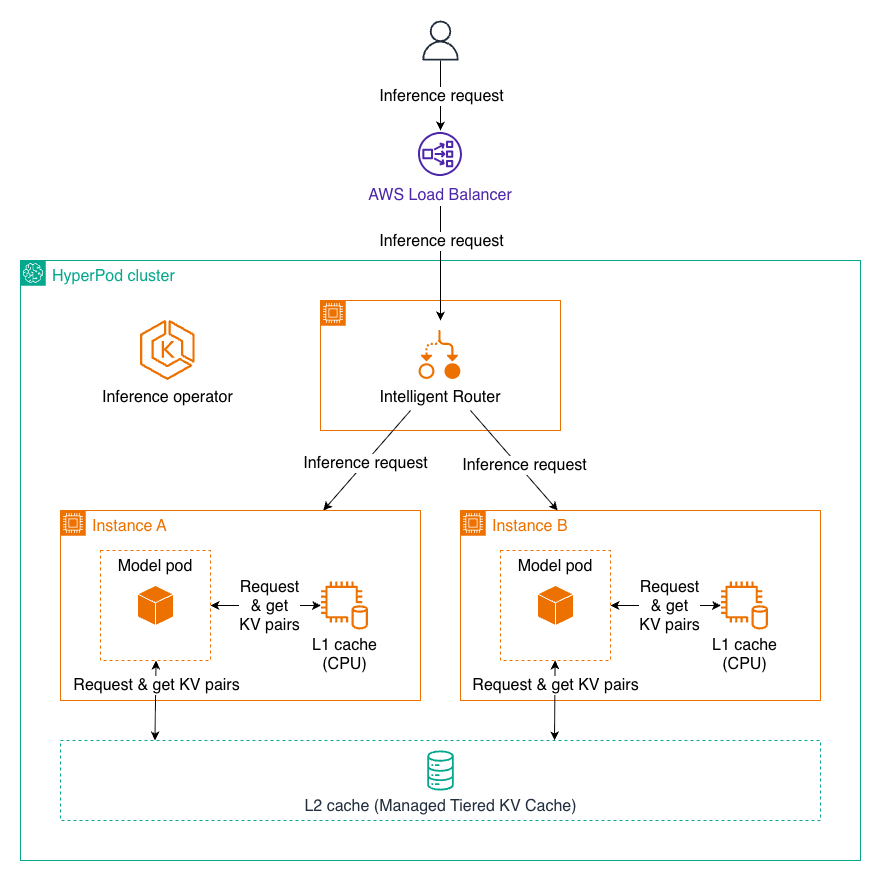
하이퍼팟의 계층형 KV 캐시 구성
SageMaker HyperPod는 새로운 Inference Operator를 통해 2단계 계층형 캐시 구조를 지원합니다:
- L1 캐시: 각 인퍼런스 노드의 CPU 메모리에 위치하며, 자주 사용되는 벡터를 빠르게 접근할 수 있습니다.
- L2 캐시: 클러스터 전체에 걸쳐 분산되며 여러 노드가 계산된 KV 벡터를 공유해 효율적인 리소스 활용이 가능합니다.
두 계층은 자동으로 연동되어, L1에서 찾지 못하면 L2를 탐색하고, L2에서도 없을 때만 전체 계산을 수행합니다.
L2 백엔드 옵션은 다음과 같습니다:
- Managed Tiered Storage(권장): AWS 네트워크 최적화, GPU 친화적인 설계, 제로 카피 등 엔터프라이즈급 확장성과 성능을 제공합니다.
- Redis: 빠른 구축과 통합 환경에 적합하지만, 대규모 운영에는 한계가 있습니다.
지능형 라우팅 전략
하이퍼팟의 Intelligent Routing은 3가지 주요 전략을 제공합니다:
- Prefix-aware Routing (기본값): 동일한 프롬프트 전두부(prefix)를 식별하여 자동 라우팅하며, 멀티턴 챗봇 등에 적합합니다.
- KV-aware Routing: 캐시 위치와 수명을 실시간으로 관리하는 고급 전략으로, 긴 대화나 대형 문서 처리에 최적화되어 있습니다.
- Round-robin Routing: 요청을 균등하게 분산하여 독립적인 작업이나 배치 처리에 적합합니다.
각 전략은 애플리케이션의 특성과 사용량에 따라 맞춤형으로 활용 가능합니다.
SageMaker HyperPod에 기능 배포하기
이 기능들을 활용하려면 Amazon EKS 기반의 HyperPod 클러스터를 생성하고 inference operator를 활성화해야 합니다. SageMaker 콘솔 UI에서 클릭 한 번으로 배포가 가능하며, 커스텀 리소스 정의(CRD)를 통해 InferenceEndpointConfig에 다음과 같이 설정을 추가합니다:
- enableL1Cache: true
- enableL2Cache: true
- l2CacheBackend: "tieredstorage" 또는 "redis"
- routingStrategy: prefixaware, kvaware, 또는 roundrobin
kubectl을 통해 YAML 파일을 배포한 후, 해당 인퍼런스 워크로드에서 실시간 TTFT, 처리량, 캐시 활용률 등의 메트릭을 Amazon Managed Grafana 또는 SageMaker Observability로 관찰할 수 있습니다.
현실 환경에서의 활용 사례
Managed Tiered KV Cache와 Intelligent Routing을 활용한 실제 사용 사례는 다음과 같습니다:
- 법률 부서: 200페이지 계약서를 분석할 때 연속된 질의에 대해 지연 없이 바로 응답 가능
- 헬스케어 챗봇: 환자와의 20턴 이상의 대화를 자연스럽게 이어가며 데이터 유지
- 고객 서비스: 일일 수백만 건의 요청을 빠르게 처리하면서 인프라 비용 절감
성능 벤치마크 결과
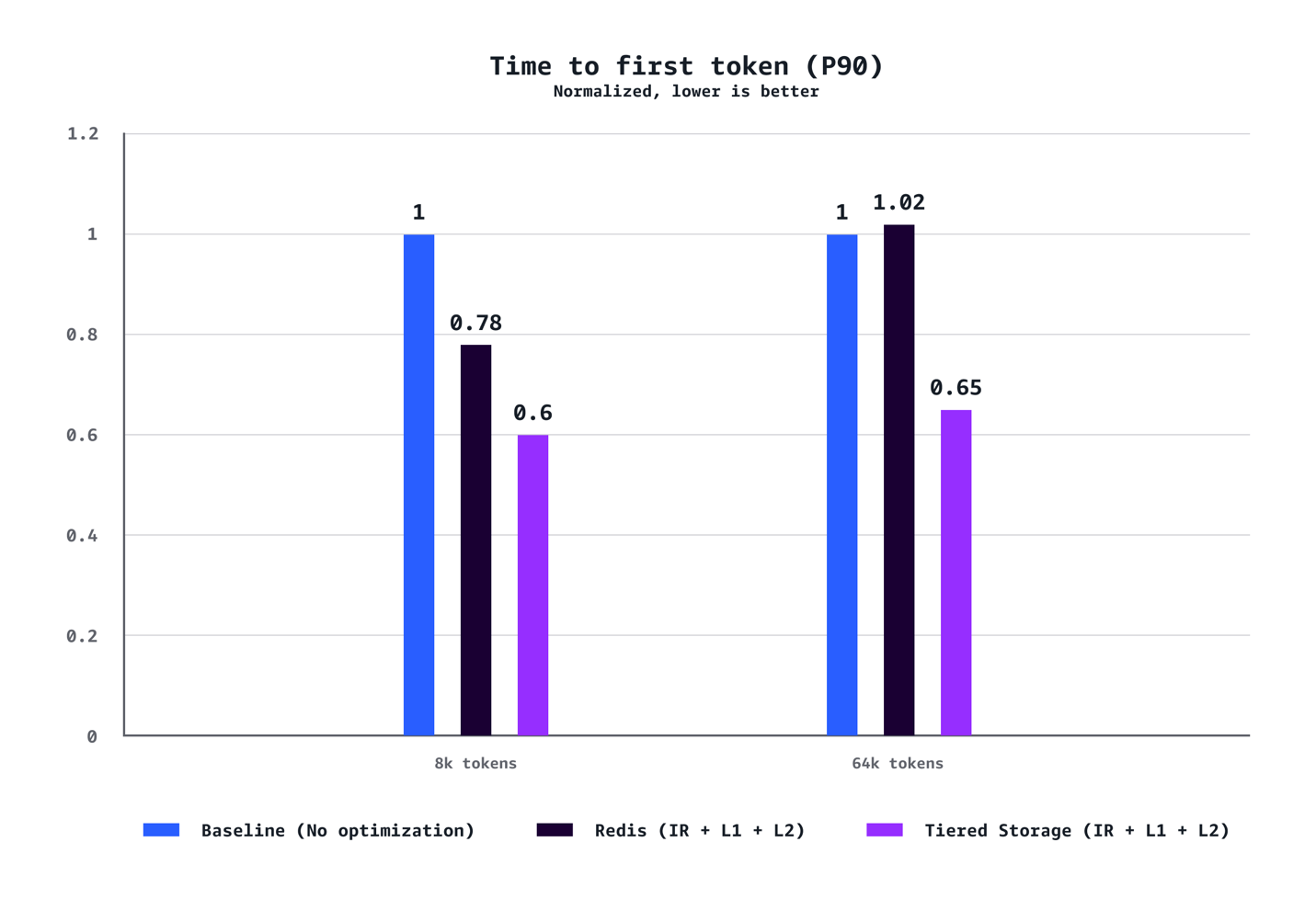
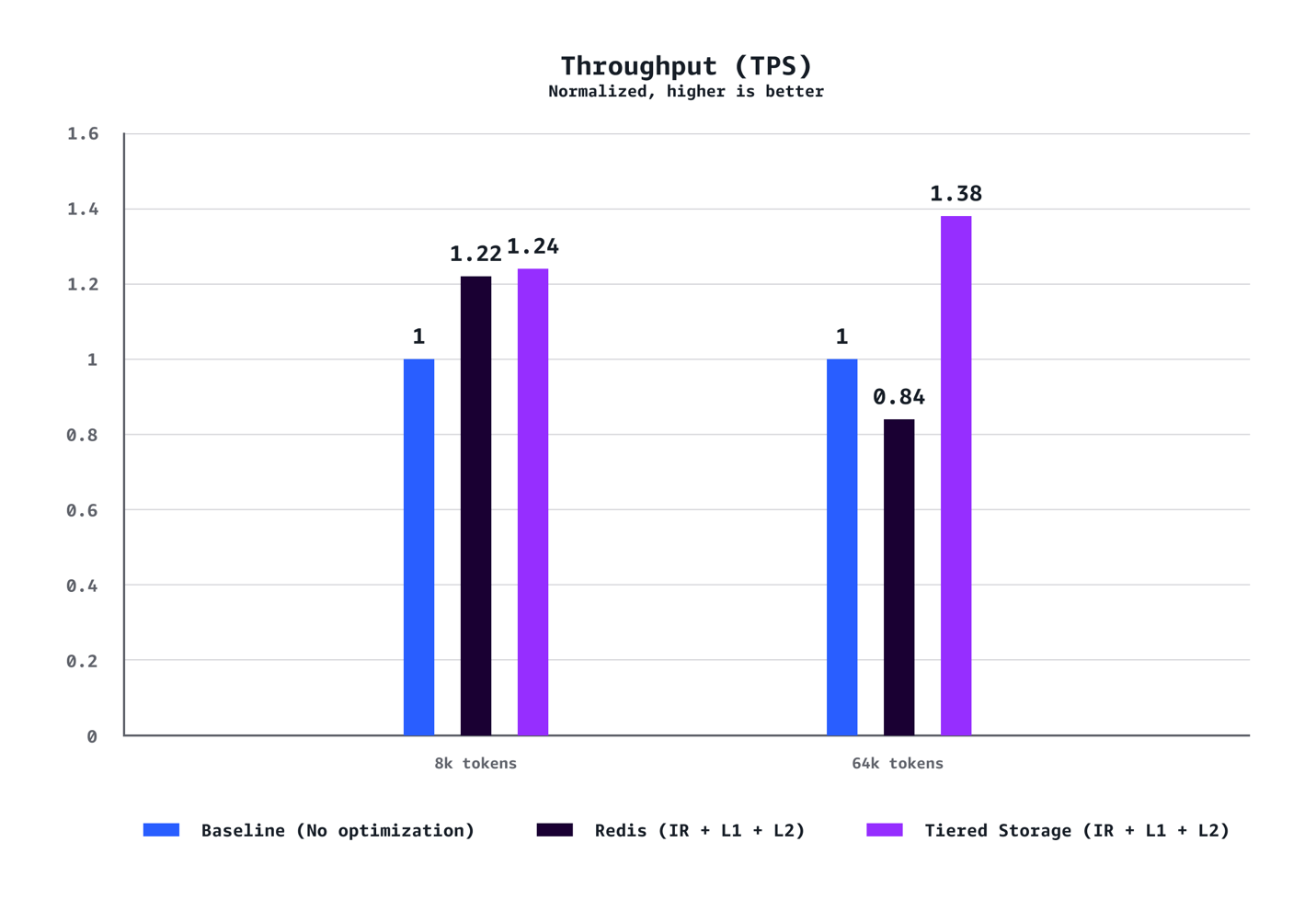
Llama-3.1-70B 모델을 p5.48xlarge 인스턴스 7개로 배포한 실험에서 다음과 같은 최적화 결과를 얻었습니다:
- 8K 토큰 기준:
- TTFT P90: 40% 감소
- 처리량: 24% 증가
- 비용: 21% 절감
- 64K 토큰 기준:
- TTFT P90: 35% 감소
- 처리량: 38% 증가
- 비용: 28% 절감
결론
Amazon SageMaker HyperPod의 Managed Tiered KV Cache와 Intelligent Routing은 LLM 추론 인프라의 자동화, 활용성, 확장성, 그리고 비용 효율성을 동시에 만족시키는 획기적인 기능입니다. 모델 추론 초기 지연을 줄이고, Context가 긴 생성형 AI 응용 프로그램에서도 높은 성능을 유지할 수 있도록 돕습니다. KV 캐시에 대한 효율적인 구성과 요청 라우팅 전략은 미래의 엔터프라이즈 AI 시스템 설계에서 필수적인 요소가 될 것입니다.
이 기능들은 SageMaker HyperPod가 제공되는 AWS 리전에서 현재 사용 가능하며, 지금 바로 모델 배포 구성에 적용해 보시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
