CBRE 사례로 보는 Amazon Bedrock 기반 부동산 통합 검색 및 디지털 어시스턴트 구축 가이드
CBRE는 세계 최대 상업용 부동산 서비스 기업으로, 전 세계 100여 개국에서 투자, 운용, 임대, 프로젝트 관리 등 다양한 서비스를 제공합니다. 이러한 대규모 운영에서 생성되는 방대한 부동산 데이터를 효율적으로 처리하고, 디지털 어시스턴트를 통해 보다 직관적인 정보 탐색을 가능하게 하기 위한 AI 시스템을 도입한 사례가 이번 글의 핵심입니다.
이 글에서는 CBRE가 Amazon Bedrock, OpenSearch, RDS, ECS, AWS Lambda 등 AWS의 다양한 서비스를 활용하여 구축한 통합 검색 아키텍처와 이를 통해 구현한 비즈니스 자동화 사례, SQL 및 문서 기반 자동 검색 최적화 기법을 소개합니다. 특히 대규모 데이터 환경에서 어떻게 자연어 질의(NLQ)를 효율적으로 SQL 쿼리로 변환하고, 비정형 문서를 AI 기반으로 대화형 검색할 수 있도록 구성했는지를 포함합니다.
CBRE의 PULSE 아키텍처 개요
CBRE는 PULSE라는 내부 시스템에 Amazon Bedrock을 활용한 생성형 AI 기반 통합 검색 시스템을 구축하였습니다. 이 검색 아키텍처는 정형 DB와 비정형 문서를 함께 다루며, 사용자가 자연어로 하는 질문에 대해 문서 요약, 요점 추출, 표 형식 데이터 제공 등 다양한 정보를 실시간으로 제공합니다.
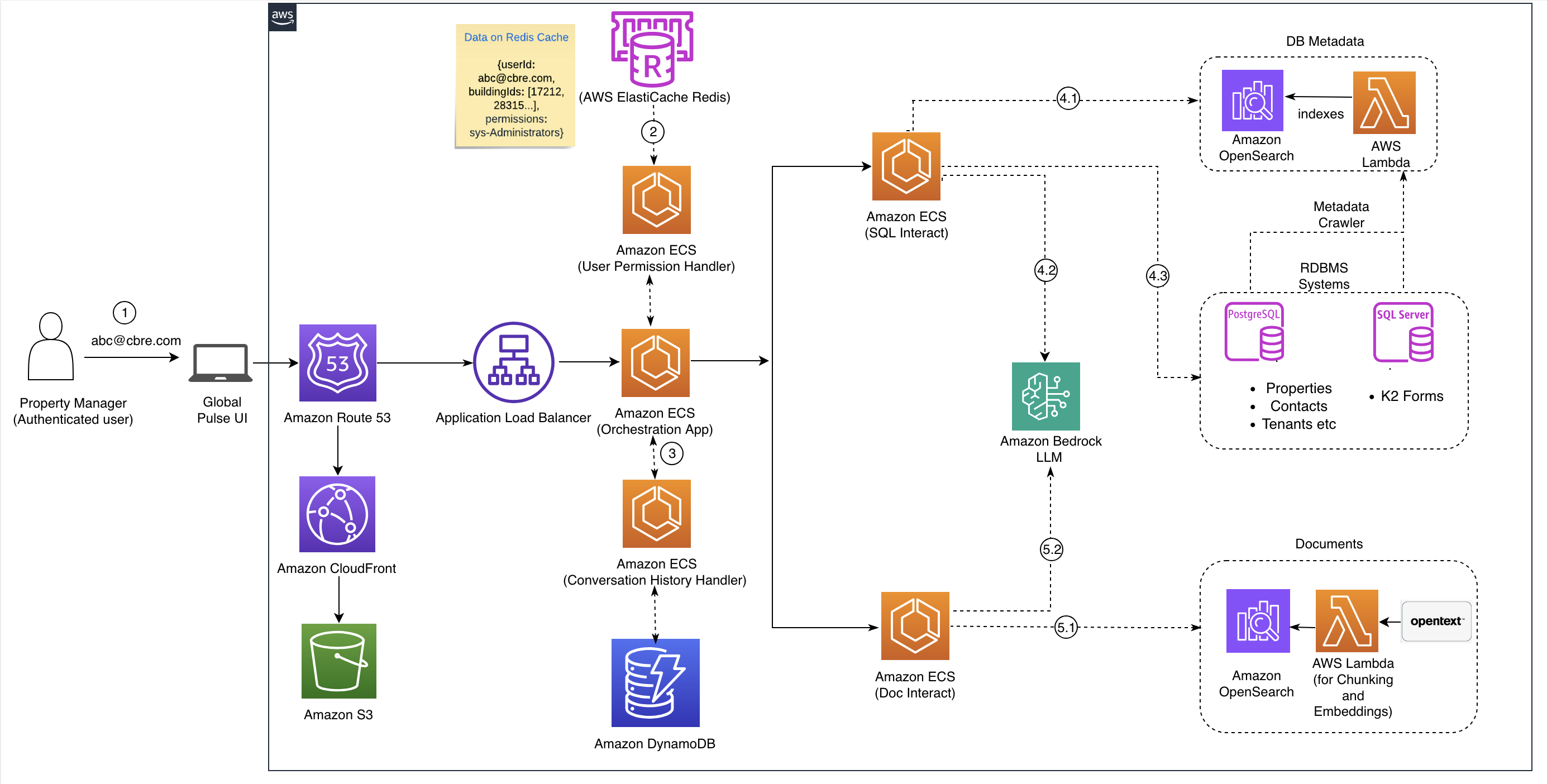
핵심 구성 요소
-
PULSE UI와 사용자 상호작용:
사용자들은 NLQ와 키워드 검색 방식을 통해 다양한 형태의 부동산 데이터에 접근합니다. Claude Haiku 기반 LLM을 통한 문서 대화 기능도 제공되어 문서 내 정보를 빠르게 이해할 수 있습니다. -
허가 기반 검색 제어:
사용자 권한은 Redis에서 실시간으로 조회되며, 이 권한을 기반으로 데이터 접근이 제한됩니다. 이는 보안성과 데이터 무결성을 강화하는 핵심 요소입니다. -
오케스트레이션 계층:
검색 요청은 오케스트레이션 계층에서 SQL 관련 요청은 SQL Interact로, 문서 관련 요청은 Doc Interact로 라우팅되어 병렬 검색을 수행하며 결과 정렬 및 중복 제거가 이루어집니다.
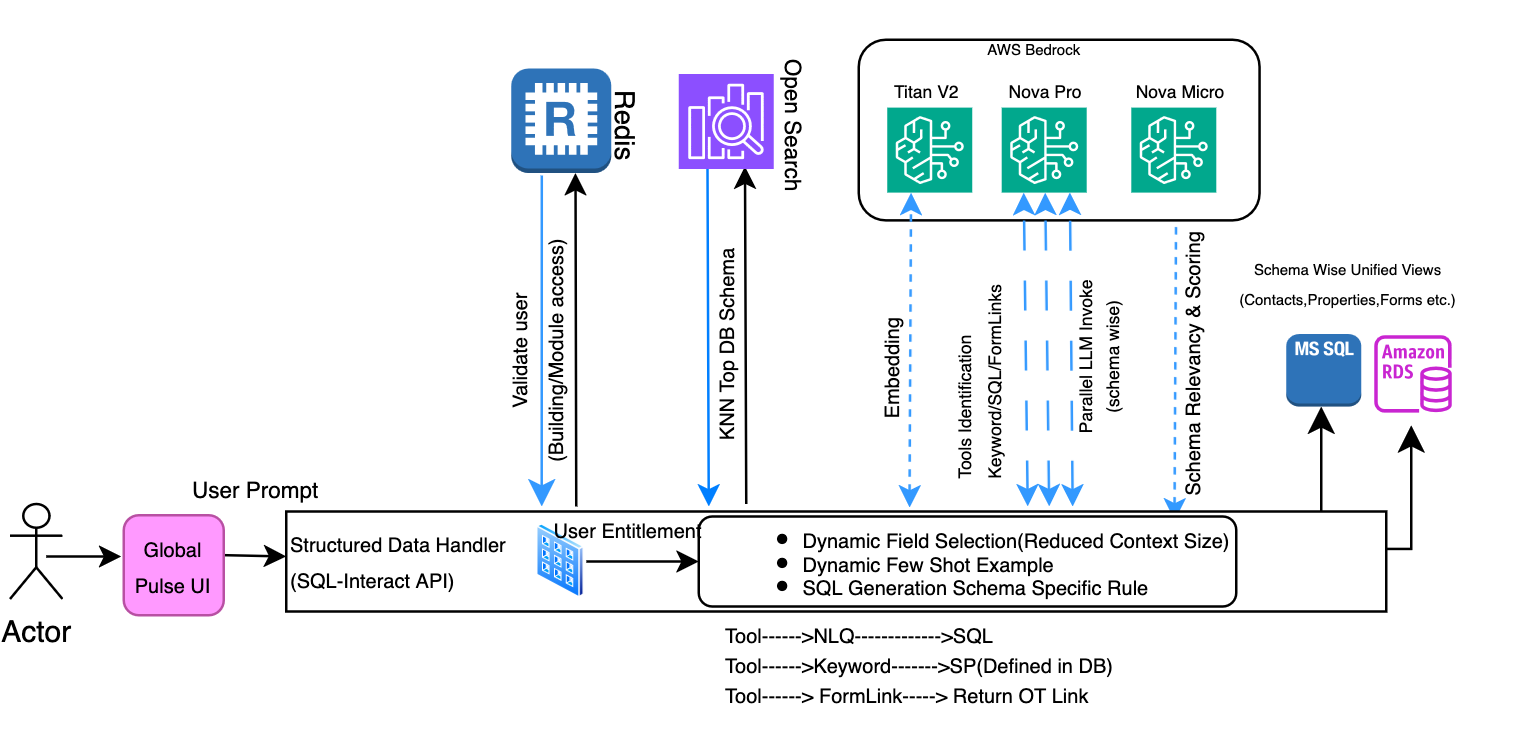
SQL Interact 구성: 자연어를 SQL로 자동 변환
이 컴포넌트는 PostgreSQL, MS SQL 등 정형 DB에 저장된 부동산 데이터에 자연어 질의를 자동으로 SQL로 변환합니다. Amazon Nova Pro 모델을 통해 질의 변환 시간을 12초에서 4초로 단축하는 동시에, 정확도와 규칙 일관성을 확보했습니다.
- 시스템은 데이터베이스 스키마를 OpenSearch에서 조회하고 유사도 기반으로 연관된 필드를 선별해 효율적인 프롬프트 구성을 합니다.
- Prompt Engineering 기법을 통해 동적으로 적절한 few-shot 예제를 삽입하여 SQL 생성의 품질과 일관성을 높였습니다.
- 추가적으로 Relevancy Scoring을 도입해 벡터 유사도만으로는 판단하기 어려운 "의도 기반" 스키마 선별을 가능하게 하였습니다.
또한, 병렬 LLM 추론을 통해 고도화된 파이프라인을 구현했습니다.
Doc Interact 구성: 비정형 문서 검색 및 대화형 어시스턴트
PULSE는 다양한 문서 포맷(PDF, 워드, 이메일 등)을 OpenSearch 벡터 인덱스로 저장하고, Claude Haiku 기반 LLM을 통해 자연어 질의에 대한 의미 기반 검색을 수행합니다.
- 키워드 기반 검색은 phrase match와 메타데이터 병합 검색 방식으로 구성되어 있으며, 빠른 결과 제공이 가능합니다.
- NLQ 검색은 KNN 벡터 기반 의미 유사도 탐색과 함께 LLM을 사용한 자연어 DSL 변환 방식이 병행됩니다.
- 문서 채팅 기능은 특정 문서에 대해 사용자가 대화를 이어가며 내용을 요약하거나 특정 정보를 요청할 수 있게 합니다.
문서 업로드 후에는 Amazon Textract와 Bedrock 기반 텍스트 임베딩 모델을 활용한 자동 분할 및 메타 정보 추출을 수행하여 검색 효율과 맥락 파악을 최적화합니다.
보안 처리 및 권한 제어
보안 측면에서는 Microsoft B2C 인증, Redis 기반 권한 검증, 건물별 권한 필터링 등 복합적인 보안 레이어가 구현되었습니다. 사용자가 데이터에 접근하기 전 모든 권한 검증이 병렬로 처리되며, Redis를 통해 고속 접근이 가능하도록 구성되어 있습니다.

주요 효과 및 자동화 성과
- 운영 비용 절감: 반복적인 정보 검색과 문서 리뷰에 소요되던 시간을 수 시간에서 수 초로 단축하여 인건비 절감 효과 달성
- 의사결정 개선: 신뢰성 높은 데이터 기반 검색으로 95% 이상 정확도 도달, 오류로 인한 리스크 감소
- 사용성 향상: 직관적인 검색 UI와 모바일 환경 지원으로 사용자 만족도 향상
활용 가이드 및 최적화 베스트 프랙티스
- Prompt 모듈화: 유지보수성과 정확성 향상을 위해 YAML/JSON 기반 템플릿 분리
- Few-shot 예제 구성: 동적 매칭 시스템 도입으로 빈도 높은 케이스를 커버
- 컨텍스트 윈도우 최소화: 불필요한 토큰 최소화로 LLM 처리 시간 단축
- LLM 기반 Relevancy 재정렬: KNN만으로 부족한 경우 LLM을 통해 스키마 순위를 재조정
결론
CBRE의 사례는 AWS Generative AI 생태계를 통해 어떻게 기존 서비스를 지능화하고, 데이터 기반의 정확한 의사결정 체계를 구현할 수 있는지를 여실히 보여줍니다. 특히 자동화를 통해 반복 작업을 줄이고, 고부가가치 업무에 집중할 수 있는 환경을 마련했다는 점에서 기업 내 AI 도입 시 우선 고려해야 할 방향성을 제시합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
