아마존 베드락의 커스텀 모델 임포트 최적화 기능 소개: 모델 추론 성능 향상을 위한 자동화 전략
최근 아마존 웹 서비스(AWS)는 Amazon Bedrock에서 커스텀 모델 임포트(Custom Model Import, 이하 CMI)의 추론 성능을 획기적으로 향상시키는 새로운 최적화를 발표하였습니다. 이번 블로그에서는 모델 성능 향상이 어떤 식으로 작동하며, 실제 배포 시 어떤 이점을 제공하는지 배포 가이드와 활용 사례를 중심으로 설명합니다.
CMI 최적화 기능은 딥러닝 모델의 초기화 지연 시간과 병목 현상을 줄이며, 동시에 추론 처리량(throughput)을 증가시키는 데 초점을 둡니다. 특히 Time to First Token(TTFT) 및 End-to-End Latency(전체 응답 시간)를 줄이고 Output Tokens per Second(OTPS)를 개선하여 대규모 동시 요청을 효과적으로 처리할 수 있도록 설계되었습니다.
CMI 최적화 작동 방식: 아키텍처 기반 자동화 전략
이번 고도화는 PyTorch 컴파일과 CUDA 그래프 최적화 기술을 활용한 컴파일 아티팩트 캐싱(Compilation Artifact Caching)에 기반하여 성능을 향상시킵니다. 첫 실행 시 모델의 연산 그래프 최적화, 커널 컴파일, 메모리 계획(메모리 할당 최적화)을 수행해 생성된 결과물을 저장해두고, 이후 동일한 설정의 인스턴스가 재사용 시에는 해당 결과물만 불러오도록 자동화됩니다.
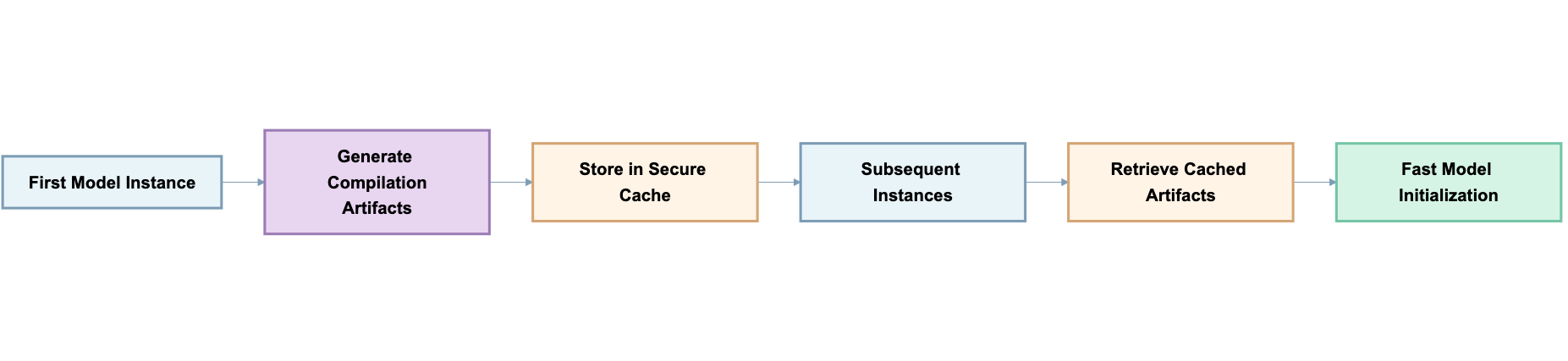
이 과정은 모델 아키텍처, 배치 크기, 시퀀스 길이, 하드웨어 사양 등을 바탕으로 고유한 식별자를 생성하여 캐시의 유효성을 검증합니다. 파일이 손상되었을 경우를 대비하여 체크섬 검증 기능도 포함되어 있으며, 손상 시 자동 재컴파일 후 캐시를 갱신합니다.
모델별 최적화 효과 비교: Granite 20B vs Llama 3.1 8B
성능 비교 대상은 코드 생성에 특화된 Granite 20B 모델과 일반 지시문 처리용 Llama 3.1 8B 모델입니다. 두 모델 모두 다양한 입출력 토큰 조합(예: 1000입력 / 250출력, 2000입력 / 500출력)과 부하 수준(1~32 동시 요청)을 기준으로 성능 향상 폭을 분석했습니다.
Granite 20B 모델의 대표적 성능 향상 결과:
- TTFT: 989.9ms → 120.9ms (87.8% 개선)
- E2E Latency: 12,829ms → 5,290ms (58.8% 개선)
- Throughput: 360.5 → 450.8 tokens/sec (25% 증가)
- OTPS: 44.8 → 48.3 tokens/sec (7.8% 향상)

Llama 3.1 8B 모델의 성능 개선 지표:
- TTFT: 366.9ms → 85.5ms (76.7% 개선)
- E2E Latency: 3,102ms → 2,532ms (18.4% 개선)
- Throughput: 714.3 → 922.0 tokens/sec (29.1% 증가)
- OTPS: 93.9 → 102.4 tokens/sec (9.1% 향상)

활용 방안 및 자동화 배포 시나리오
Amazon Bedrock의 컴파일 캐시 최적화는 다음과 같은 실제 활용 환경에서 높은 효과를 보입니다.
-
자동 스케일링 환경:
스케일 아웃이 발생할 때에도 새 인스턴스가 동일한 컴파일 캐시를 활용해 짧은 시간 내에 고성능을 유지할 수 있습니다. -
AI 챗봇 및 콘텐츠 생성기:
초기 응답 지연 시간을 줄여 사용자 경험을 향상시키고, 더욱 많은 사용자 요청을 동시에 처리할 수 있습니다. -
개발 및 테스트 환경:
전체 추론 사이클이 짧아지기 때문에 모델 배포 주기를 단축하고 시나리오 변경에 빠르게 대응할 수 있습니다.
비용 측면에서도 매우 경쟁력 있습니다. 동시성 부하 증가에도 기존 인프라에서 더 많은 사용자 요청을 처리할 수 있어 리소스 효율성이 극대화됩니다.
성능 영향 지표 종합 정리
다음은 주요 성능 지표별 정의와 각 배포 비교 지표입니다.
- TTFT (Time to First Token): 응답이 시작되기까지의 시간
- E2E Latency: 요청부터 응답 완료까지의 전체 소요 시간
- OTPS (Output Tokens per Second): 출력 생성 속도
- Throughput: 초당 처리 가능한 토큰 수 (입력+출력 합산)
성능이 일관되게 개선되었으며, 높은 동시 요청 수(최대 32)의 경우에도 성능 저하 없이 응답 품질을 유지할 수 있음이 입증되었습니다.
결론 및 도입 가이드
Amazon Bedrock CMI의 향상된 컴파일 캐싱 최적화는 구체적인 하드웨어 사양과 신경망 구조를 기반으로 성능을 높이면서도, 기존의 콜드 스타트 성능을 유지하는 방식으로 우수한 사용자 경험과 인프라 활용도를 제공합니다. 새로운 사용자뿐 아니라 기존 고객도 아무런 조정 없이 즉시 이점을 누릴 수 있기 때문에 대규모 AI 추론 시스템의 자동화 및 효율화 전략 수립에 아주 적합합니다.
Amazon Bedrock을 활용한 커스텀 모델 자동 배포의 성능 향상을 경험해보려면, 지금 CMI를 통해 모델을 임포트하고 최적화를 활성화해보시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
