머신러닝 인프라 최적화의 새로운 전환점, SageMaker HyperPod의 MIG 기능 소개
기업들이 생성형 AI 기술을 활용한 다양한 워크로드를 실행하면서, GPU 리소스를 보다 효율적으로 사용할 수 있는 방안에 대한 수요가 높아지고 있습니다. 아마존 SageMaker HyperPod는 이러한 요구에 부응하기 위해 NVIDIA의 MIG(Multi-Instance GPU) 기술을 정식 지원하여, 단일 GPU 내에서 여러 작업을 병렬로 처리하고 자원의 낭비 없이 최대로 활용하도록 돕습니다.
MIG 기술이란?
MIG는 NVIDIA Ampere 아키텍처와 함께 도입된 기술로, 하나의 GPU를 여러 개의 분리된 인스턴스로 나눠 사용할 수 있습니다. 각 인스턴스는 메모리, 캐시, 연산 자원을 독립적으로 가지고 있어, 서로 간섭 없이 예측 가능한 성능을 제공합니다. 예를 들어 한 GPU에서 동시에 소형 모델 추론, 실험용 노트북, 연구 목적의 추론을 병렬로 실행할 수 있게 되는 것이죠. 이러한 분할 구조는 더 작은 워크로드를 위한 적합한 하드웨어 자원을 할당하여 비용 효율성과 활용성을 끌어올리는 데 효과적입니다.
SageMaker HyperPod와의 통합
SageMaker HyperPod는 Amazon EKS 기반 클러스터에서 GPU를 관리하는 고급 기능을 제공하며, 여기에 MIG를 통합하여 다음과 같은 강점을 확보했습니다.
- 자동 구성: 클러스터 생성 시 GUI 또는 API를 통해 MIG 설정을 쉽게 구성할 수 있어 자동화된 배포가 가능합니다.
- 자원 최적화: GPU 자원을 다양한 크기로 분할함으로써 가벼운 추론, 인터랙티브 개발, 소규모 훈련 등을 보다 정밀하게 배치할 수 있습니다.
- 작업 격리: 서로 다른 사용자나 팀이 동일 GPU를 사용할 경우에도 각 작업은 분리된 환경에서 성능 저하 없이 수행됩니다.
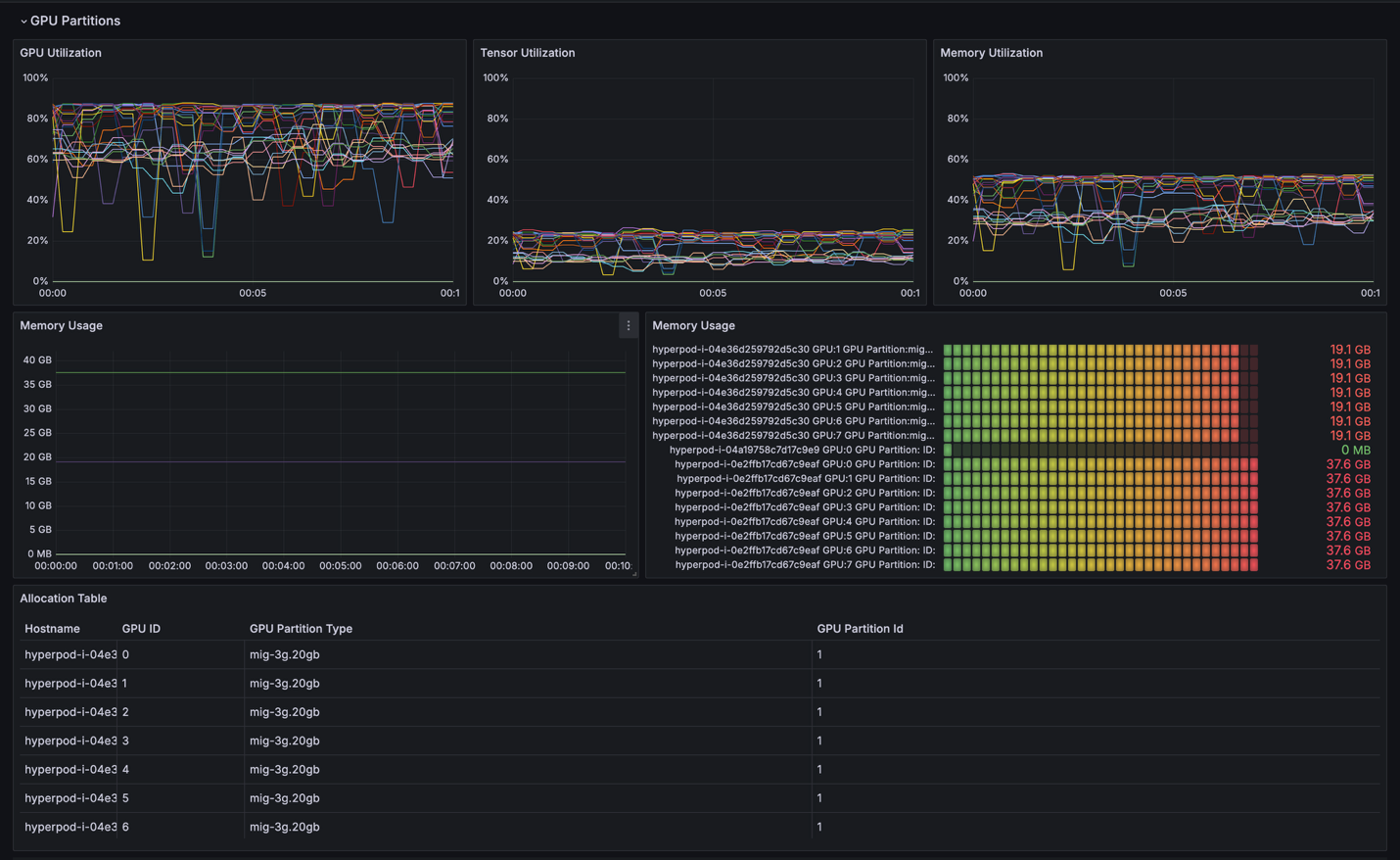
- 통합 모니터링: Grafana 기반 대시보드를 통해 MIG 파티션별 GPU 활용 현황을 실시간으로 모니터링할 수 있습니다.
- 클러스터 회복력: HyperPod의 자동 복구 시스템은 하드웨어 장애 시 작업을 체크포인트에서 재개하게 하여 안정적인 운영을 지원합니다.
사례: 다양한 워크로드 병렬 실행
MIG의 활용성은 실제 워크로드 구성을 통해 명확해집니다. 예를 들어 하나의 ml.p5en.48xlarge 인스턴스에서 다음 세 가지 작업을 병렬로 실행하는 구성을 살펴보겠습니다.
- 추론 작업: DeepSeek-R1-Distill-Qwen-1.5B 모델을 SageMaker JumpStart를 통해 HyperPod Inference Operator로 배포하고, MIG의 4g.71gb 파티션에서 구동합니다.
- 분리된 추론 단계: 모델 생성의 prefill과 decode 단계를 각각 자원이 다른 MIG 파티션(4g.71gb 및 1g.18gb)에 배치하여, 각 단계의 특성에 최적화한 할당치를 적용합니다.
- 개발 환경: Data Scientist가 실험을 진행할 수 있도록, Jupyter Notebook을 1g.18gb 파티션에 지정하여 독립적인 개발 공간을 제공합니다.
HyperPod 클러스터에서 MIG를 설정하는 방법
- 관리형 설정 (추천 방식)
- 콘솔 UI 또는 UpdateCluster API 를 통해 인스턴스 그룹 차원에서 MIG 구성을 적용
- 예: nvidia.com/MIG.config 레이블을 mixed-3-1g.18gb-1-4g.71gb 와 같이 지정하여 혼합형 파티션 구성
- DIY (직접 설정) 방식
- 쿠버네티스 CLI(kubectl)를 사용하여 노드 단위로 nvidia.com/MIG.config 레이블을 수동 적용
- HyperPod Helm Chart 또는 GPU Operator 를 활용해 필요한 구성 요소를 배포
MIG 프로파일과 활용 시나리오
다양한 MIG 구성 중 특히 유용한 예시는 다음과 같습니다.
- 1g.18gb: 소규모 추론 및 노트북 환경
- 4g.71gb: 중간 규모의 LLM 추론
- mixed-3-1g.18gb-1-4g.71gb: 다양한 유형의 작업을 조합하여 최적화

운영 자동화 및 거버넌스 통합
SageMaker HyperPod에서 제공하는 Task Governance 기능은 다음의 사항을 가능하게 합니다.
- 팀 단위 Quota 설정 및 MIG 단위 리소스 할당
- 우선순위 기반 작업 배치 및 리소스 자동 회수
- 실시간 자원 대시보드 및 사용량 기반 할당
이미 DIY 환경을 운영 중이라면, managed 환경으로 쉽게 마이그레이션할 수 있으며, HyperPod CLI를 통해도 단순하게 설정을 이전할 수 있습니다.
결론
Amazon SageMaker HyperPod에서 MIG 지원의 정식 출시는 AI/ML 인프라 운영에 있어 중요한 전환점을 맞이하고 있습니다. GPU 자원의 분할 사용을 통해 다양한 워크로드를 동시에 실행할 수 있으며, 추론, 개발, 실험, 테스트 등 다양한 작업을 MIG 기반의 격리된 환경에서 병렬로 운영할 수 있습니다. 이를 통해 기업은 인프라 비용은 줄이고, 리소스 활용률은 높이며, 개발 속도는 가속하는 혁신적인 AI 환경을 구축할 수 있게 되었습니다.
자세한 구성 방법과 실습은 하이퍼포드 공식 문서를 참고해보세요!
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
