기업용 검색 엔진을 위한 Cohere Embed 4 모델의 Amazon Bedrock 접목 가이드
최근 기업 데이터가 텍스트, 이미지, 표 등 다양한 형식으로 확장되면서 멀티모달 데이터를 빠르게 이해하고 활용할 수 있는 검색 시스템의 중요성이 커졌습니다. 이에 따라 AWS는 Cohere의 최신 Embed 4 모델을 Amazon Bedrock에 통합하여 멀티모달 임베딩 기반의 엔터프라이즈 검색 솔루션을 손쉽게 구현할 수 있도록 지원하고 있습니다. 본 포스팅에서는 Embed 4의 주요 기능과 활용법, 그리고 실제 금융 업계 사례를 기반으로 한 자동화된 배포 가이드를 소개합니다.
Embed 4 개요 및 기능
Cohere Embed 4는 단일 벡터 표현으로 텍스트, 이미지, 혼합 콘텐츠를 동시에 처리할 수 있는 강력한 멀티모달 임베딩 모델입니다. 최대 128,000개의 토큰을 처리할 수 있어 문서 분할이 최소화되며, 최대 83%까지 벡터 저장 용량을 절감할 수 있는 압축 임베딩 옵션도 제공합니다. 특히 100개 이상의 언어를 지원함으로써 다국어 문서 검색에 강점을 가지며, 의료/금융/제조 등 규제 산업의 복잡한 비정형 데이터를 효과적으로 활용할 수 있습니다.
Amazon Bedrock에서 Embed 4 배포하는 법
Amazon Bedrock은 서버리스 형태로 AI 모델을 손쉽게 배포하고 관리할 수 있는 환경입니다. 사용자는 코드를 작성함과 동시에 Bedrock에 호스팅된 모델을 활용하여 임베딩 생성부터 응답 생성까지 자동화된 워크플로우를 구축할 수 있습니다. 아래는 Python 기반 AWS SDK(Boto3)를 활용해 Embed 4 모델을 호출하는 기본 코드입니다.
텍스트 기반 입력 처리 예시:
response = bedrock_runtime.invoke_model(
modelId='cohere.embed-v4:0',
body=json.dumps({
"texts": [text1, text2],
"input_type": "search_document",
"embedding_types": ["float"]
}),
accept='/',
contentType='application/json'
)
텍스트 + 이미지 혼합 입력 예시:
response = bedrock_runtime.invoke_model(
modelId='cohere.embed-v4:0',
body=json.dumps({
"inputs": [{
"content": [
{ "type": "text", "text": text },
{ "type": "image_url", "image_url": image_base64_uri }
]
}],
"input_type": "search_document",
"embedding_types": ["int8", "float"]
}),
accept='/',
contentType='application/json'
)
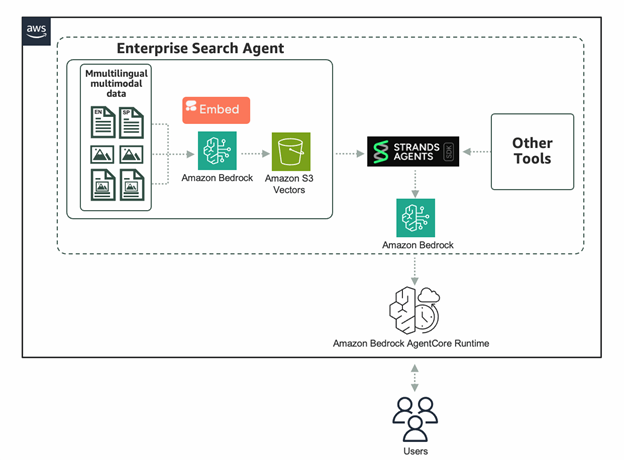
실사용 사례: 금융업계의 문서 검색 자동화
금융 분야에서는 실적 보고서, 분석 리포트, 규제 공시 등 수많은 문서들이 비정형 포맷으로 축적됩니다. Embed 4는 이 데이터를 임베딩한 후 Amazon S3 Vectors에 저장하고, 이후 질의 기반으로 벡터 유사도 검색을 수행하여 관련 문서를 정확히 반환합니다. 이와 함께 Strands Agent 프레임워크를 통해 AI 에이전트를 구성하고, Bedrock AgentCore에 배포하여 서버리스 방식으로 자동화된 RAG(Retrieval-Augmented Generation) 시스템을 구축할 수 있습니다.
예시 코드에서는 Cohere Embed 4로 질의를 임베딩한 후 S3 Vector Index에서 벡터 기반 검색을 수행합니다.
result = search("Compare earnings growth rates mentioned in the documents")
응답 결과는 다음과 같이 다국어로 작성된 다양한 기업의 실적 문서를 의미 유사도 기반으로 정렬하여 제공합니다. 에이전트가 이 결과를 추론에 활용하면, 각 기업의 성장률을 비교한 분석 보고서까지 자동 생성할 수 있습니다.
Embed 4와 RAG 워크플로우 최적화 전략
대규모 문서의 처리에서는 의미 단위의 문장 경계를 기준으로 청킹(Chunking)하고, 생성된 청크들을 기반으로 재정렬(Reranking)하는 전략을 통해 성능을 극대화할 수 있습니다. 검색 정확도를 개선하고, 더 정밀한 검색 자동화 시스템을 설정할 수 있습니다. 또한 AgentCore를 통해 해당 에이전트를 서버리스로 실행하면 인프라 관리 없이 엔터프라이즈 스케일에서 안정적으로 운영할 수 있습니다.
효율적인 배포 자동화: AgentCore Starter Toolkit
Bedrock AgentCore는 에이전트를 손쉽게 AWS 환경에 배포할 수 있는 툴킷을 제공합니다. requirements.txt와 entrypoint만 정의하면 필요한 IAM Role, ECR Repository까지 자동 생성하며, invoke 함수로 실시간 질의 응답도 가능합니다.
agentcore_runtime = Runtime()
response = agentcore_runtime.configure(
entrypoint="example.py",
auto_create_ecr=True,
agent_name="search_agent"
)
라이브 시스템에서 에이전트를 활용한 질의 호출:
invoke_response = agentcore_runtime.invoke({"prompt": "Compare earnings growth rates mentioned in the documents"})
비용 최적화 및 리소스 클린업
임베딩 저장에 사용한 S3 Vector Bucket 및 Index는 사용 후 반드시 삭제하여 비용을 방지합니다. 인퍼런스를 위한 임시 AgentCore 런타임과 ECR 리소스도 정리해야 합니다.
결론
Cohere Embed 4를 Amazon Bedrock에서 사용하는 것은 기업이 보유한 방대한 데이터의 검색, 이해, 추론을 자동화하여 비즈니스 인사이트를 강화하는 강력한 전략입니다. 다국어 지원, 최대 128K 토큰 처리, 벡터 저장 최적화 등의 기능은 실사용 환경에 적합하며, Strands Agent 및 AgentCore와의 통합을 통해 완전한 자동화 검색 워크플로우를 구축할 수 있습니다. 향후 Embed 4의 배포 지역 확대나 모델 변형 등에서 지속적인 업데이트가 예정되어 있어, 최신 정보를 주기적으로 확인하는 것을 권장합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
