아마존 검색팀은 GPU 활용률을 어떻게 2배로 높였을까?
Amazon Search 팀은 수백 개의 GPU 가속 인스턴스를 사용해 다양한 기계 학습(ML) 모델을 훈련하고 있습니다. 이 모델들은 고객에게 가장 적절한 제품을 추천하기 위해 사용되며, 동시에 여러 모델을 훈련시키는 경우가 많습니다. 이러한 과정에서, 리소스 낭비나 우선순위 관리의 어려움 등 다양한 비효율이 발생하고 있었습니다.
이에 Amazon Search 팀은 Amazon SageMaker의 훈련 작업을 AWS Batch와 통합하여 GPU 자원 활용률을 개선하였습니다. 이 글에서는 그 활용 사례와 함께, AWS Batch를 통해 어떻게 GPU 인프라 자원 자동화 및 스케줄링 최적화를 이루어냈는지 상세히 소개드립니다.
AWS Batch와 SageMaker 통합 구조
Amazon Search 팀은 학습 작업을 다음과 같은 아키텍처로 재편성하였습니다.
- Service Environment: 인스턴스 유형별로 GPU 용량 한계를 설정
- Share Identifier: 작업별 리소스 할당 비율 정의 및 우선순위 지정
- Amazon CloudWatch: 모니터링 및 자동 경고 설정으로 가용성 유지
AWS Batch의 공정 분배 스케줄링(Fair-share scheduling)을 이용해, 특정 작업에는 예약 GPU를 할당하고, 여유 자원을 동적으로 다른 작업에 재할당할 수 있도록 구성했습니다. 이로써 인스턴스 활용률을 40%에서 80% 이상으로 끌어올렸습니다.
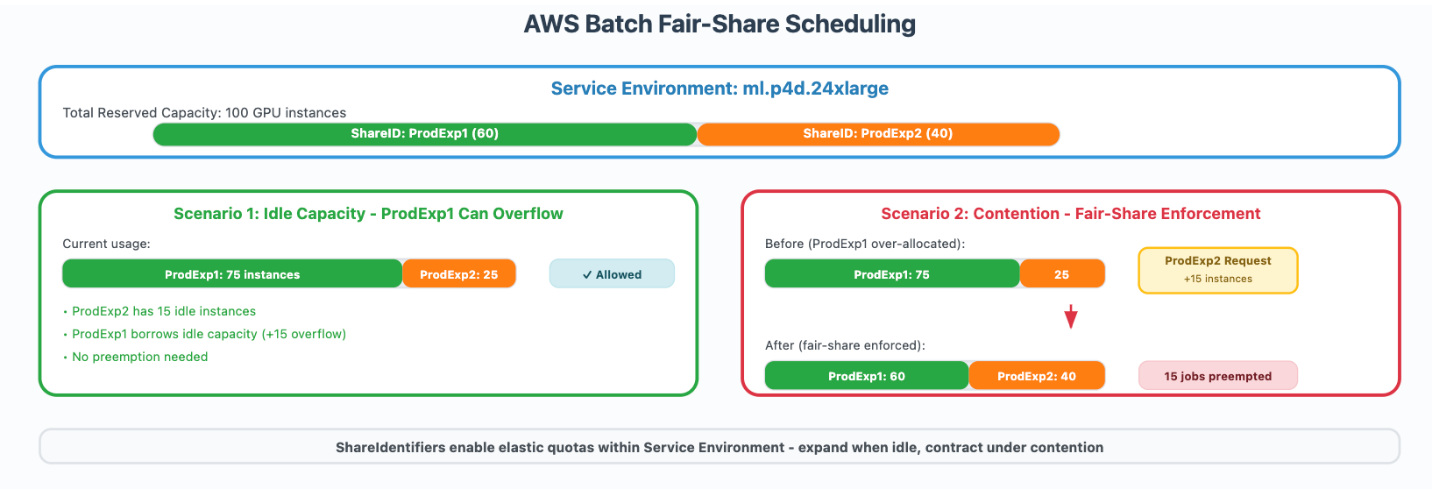
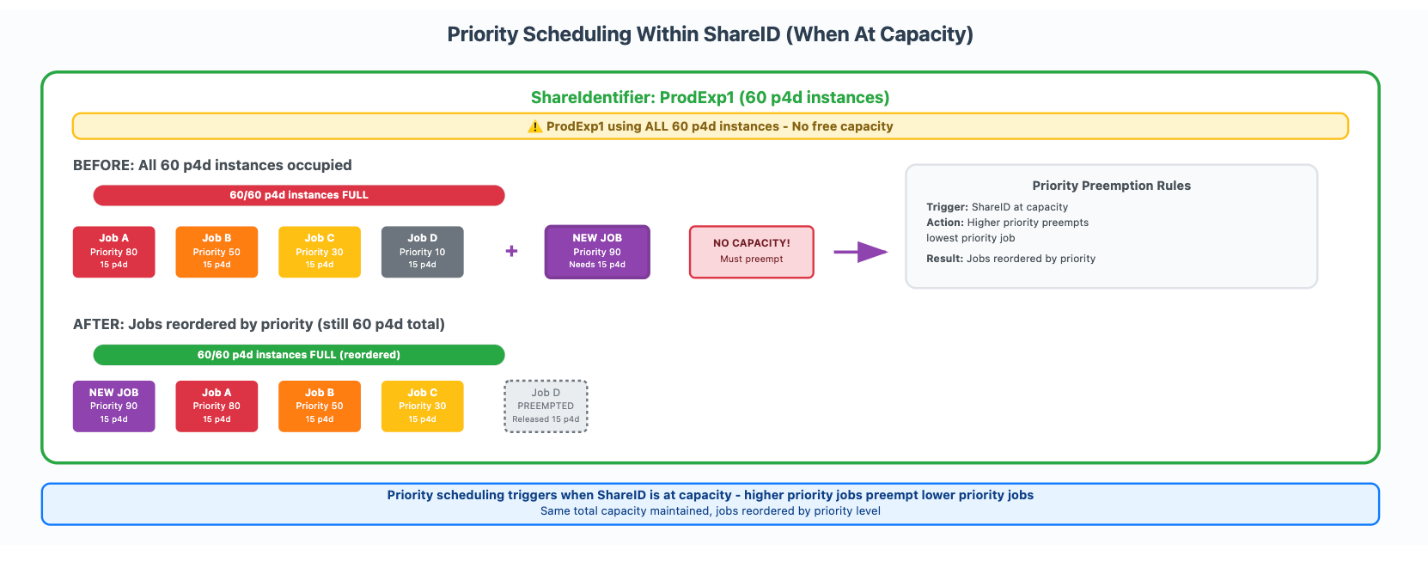
서비스 환경과 우선순위 기반 스케줄링 활용
Service Environment는 각 GPU 인스턴스군의 최대 가용 용량을 정의합니다. 예를 들어, P4 인스턴스를 100개 관리하는 환경에서는 ProdExp1에 60개, ProdExp2에 40개 할당하고, 자원이 유휴 상태가 되면 양쪽 작업 간에 자원을 유연하게 배분할 수 있습니다.
또한 Share Identifier를 활용해 작업별 리소스를 태깅하고, 내부에서 우선순위를 부여하여 실행할 작업을 효율적으로 조절합니다. 하드 제한이 아닌 소프트 쿼터 방식이기 때문에 유휴 자원을 최대한 활용할 수 있다는 장점이 있습니다.
클라우드 모니터링 자동화
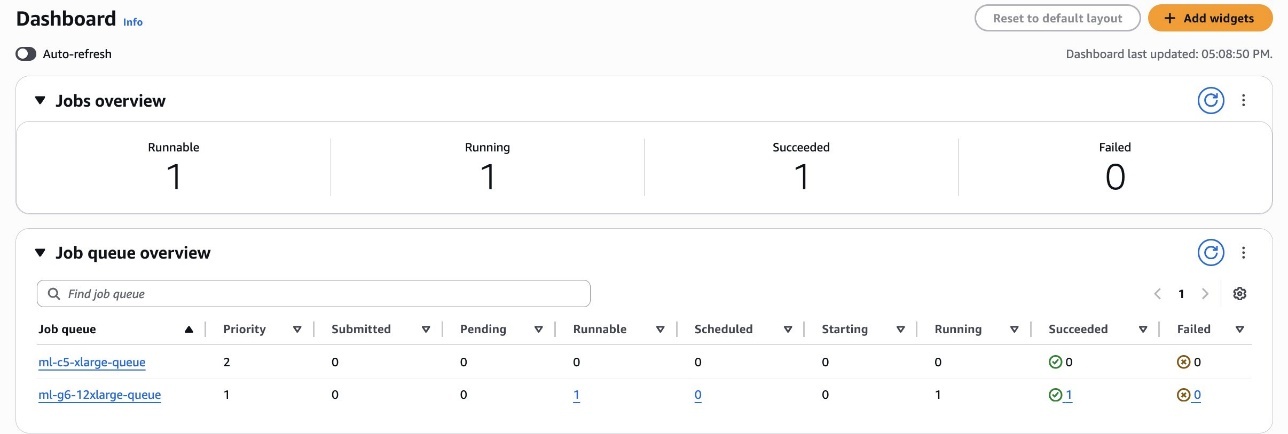
SageMaker와 AWS Batch는 Amazon CloudWatch와 연동되어 모든 작업 상태(SUBMITTED, PENDING, RUNNABLE 등)를 기록하며, 각 작업의 리소스 사용량을 실시간으로 추적합니다. 이러한 정보는 대시보드화되어 시각적으로 분석할 수 있고, 특정 이벤트에 대한 경고도 설정할 수 있어 운영 효율성을 크게 향상시킵니다.
배포 가이드: AWS Batch 환경 설정 및 LLM 학습 자동화
배포 코드를 사용하여 GPU 기반 모델 학습을 위한 SageMaker Queue 환경을 아래와 같이 손쉽게 구성할 수 있습니다.
- 사전 준비
GitHub 저장소 클론 후 스크립트 디렉토리로 이동합니다.
git clone https://github.com/aws/amazon-sagemaker-examples/
cd build_and_train_models/sm-training-queues-pytorch/
- Queue 리소스 자동 생성
AWS CLI 환경에서 다음과 같이 실행하여 필요한 구성 요소 자동 생성:
cd smtj_batch_utils
python create_resources.py
이 명령을 통해 FIFO형 CPU용 대기열과 공정 분배형 GPU용 대기열이 각각 생성되며, 정책에 따라 HIGHPRI, MIDPRI, LOWPRI 등의 세부 우선순위로 분배가 가능하게 됩니다.
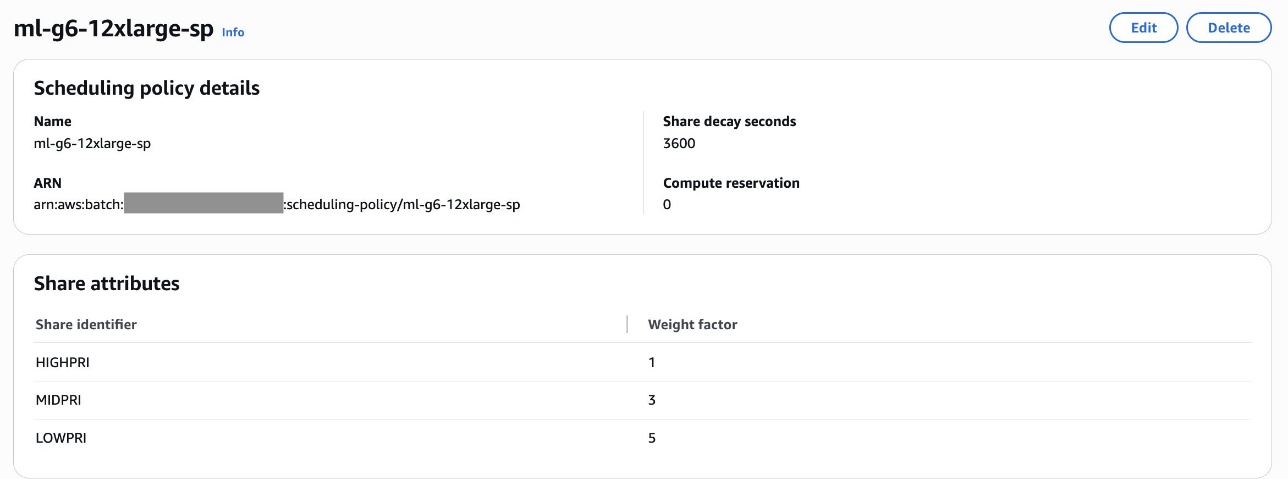
LLM 트레이닝 자동화 실행
ModelTrainer 클래스를 활용하면 PyTorch 기반 LLM 모델을 GPU 클러스터에 효율적으로 배포할 수 있습니다.
- 학습 환경 정의 (인스턴스, Container 이미지, 체크포인트 경로)
- 모델 학습 스크립트 및 하이퍼파라미터 구성
- InputData 경로(S3 버킷) 설정
- 우선순위 설정 후 학습 작업 큐에 등록 및 모니터링
예시로 LOWPRI, MIDPRI로 학습 작업 2건을 먼저 제출한 후, 나중에 HIGHPRI 작업을 추가로 제출하면, 정책에 따라 HIGHPRI가 우선 실행됩니다.
효율적인 클린업 방법까지 제공되어 실험 후 불필요한 리소스를 제거함으로써 비용 낭비를 방지할 수 있습니다.
결론
Amazon Search의 활용 사례는 AWS Batch와 SageMaker를 통합하여 기계 학습 모델 학습 작업의 우선순위, 스케줄링, 자원 배분을 완전히 자동화하고 최적화한 훌륭한 예시입니다. Fair-share 스케줄링 등 AWS의 내장 기능을 적극 활용함으로써 GPU 활용률을 2배 이상 향상시킨 점은 특히 주목할 만합니다.
AI/ML 환경에서 복수의 병렬 모델 훈련 작업을 자동화하고자 한다면, AWS Batch 연동이 필수적인 선택이 될 것이며, 특히 리소스 우선순위 조절 기능은 운영 유연성을 극대화합니다.
이를 직접 구현해보고 싶다면, GitHub에서 관련 예제와 코드, 배포 가이드를 확인해보시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
