대규모 AI 모델 훈련의 새로운 패러다임, Amazon SageMaker HyperPod Training Operator
최근 수많은 기업이 생성형 AI, 대규모 언어 모델(LLM) 등의 고도화된 인공지능 기술 활용을 위해 GPT 또는 LLaMA와 같은 대형 모델의 학습을 필수 과제로 삼고 있습니다. 그러나 GPU 수백 개 이상의 클러스터에서 AI 모델을 분산 훈련하는 것은 수많은 오류 복구, 모니터링, 성능 저하 탐지 등의 운영 상의 도전 과제를 수반합니다. 이러한 장애를 해결하기 위한 새로운 솔루션으로 Amazon SageMaker HyperPod Training Operator가 주목받고 있습니다.
Amazon SageMaker HyperPod Training Operator란?
Amazon SageMaker HyperPod는 AWS가 제공하는 대규모 분산 AI 훈련을 위한 고성능 인프라입니다. 이 중에서도 HyperPod Training Operator는 Kubernetes 기반의 학습 환경에서 Pod 장애 복구, 학습 상태 모니터링, 효율적인 Rank 배정을 통해 복잡한 AI 훈련 워크로드를 안정적으로 운영할 수 있도록 지원하는 툴입니다. Amazon EKS 클러스터에 Add-on 형태로 설치 가능하며, SageMaker 기반의 GPU 클러스터에서 수백 개 이상의 훈련 작업을 모니터링 및 자동화할 수 있습니다.
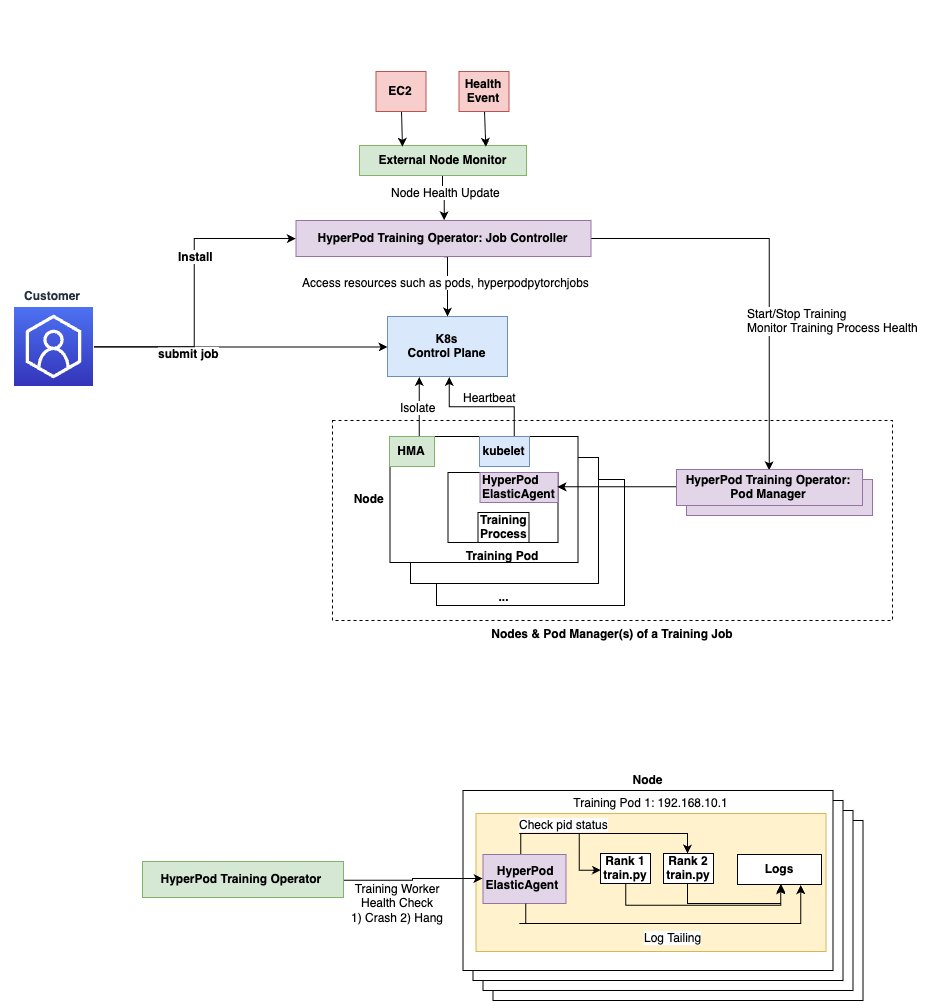
주요 구성 요소 및 아키텍처 설명
- Custom Resource Definition (CRD): 사용자가 훈련 작업을 정의할 수 있는 커스텀 리소스로, Job 사양(노드 수, 이미지 등)을 정의합니다.
- Job Controller: 훈련 작업 요청을 감지하고 Pod와 관련 자원을 자동으로 생성합니다.
- Pod Manager: 각 Pod의 훈련 프로세스를 실시간으로 모니터링합니다.
- HyperPod Elastic Agent: PyTorch ElasticAgent의 확장 버전으로, 실패 감지, 상태 동기화 등의 역할을 수행하며, 훈련 컨테이너 내부에서 실행됩니다.
활용 사례: PyTorch 기반 LLaMA 모델 훈련 실습
블로그에서는 PyTorch와 FSDP 전략을 활용해 LLaMA 3.1 8B 모델을 EKS 기반 클러스터에서 자동으로 배포하고 훈련하는 가이드를 제공합니다. 이 예제에서는 다음과 같은 자동화 요소가 포함되어 있습니다.
- ECR에 훈련 이미지 업로드
- HuggingFace Dataset(C4)를 Stream 방식으로 바로 불러오기
- Kubernetes manifest 생성을 위해 envsubst 유틸리티 사용
- 로그 기반 모니터링 구성으로 자동 오류 감지 및 작업 재시작

활용상의 이점
- 자동화된 오류 복구: 일부 노드에서 문제가 발생했을 때 전체 작업을 재시작하는 것이 아닌, 실패한 프로세스만 부분적으로 재실행하여 시간과 리소스를 절약합니다.
- 초기화 시간 최소화: 자체 rendezvous backend를 통해 worker 간 동기화 없이 rank를 효율적으로 배정합니다.
- 중단 탐지 및 성능 저하 대응: 로그 모니터링을 통해 Loss가 일정 기간 출력되지 않거나 checkpoint가 지연되는 경우 즉각 대응합니다.
- 모니터링 통합: Grafana 및 Prometheus와 연동 가능한 HyperPod Observability Add-on으로 시각화된 대시보드 제공.
- Kubernetes 친화적 구성: 기존 DevOps 기술력으로 손쉽게 EKS 환경에 연동 가능하여 CI/CD에도 연계 가능.
배포 가이드 요약
HyperPod Training Operator를 활용하기 위해서는 아래와 같은 자원과 권한이 필요합니다.
- AWS CLI, Docker, kubectl 등 설치
- Amazon EKS 1.28+ 버전 클러스터 구성
- 예제에서는 Cert-Manager 및 Pod Identity Agent 설치
- IAM 권한: AmazonSageMakerHyperPodTrainingOperatorAccess 정책 등
- SageMaker 콘솔을 통한 Add-on 한 번 클릭 설치
설치 후에는 YAML 기반 훈련 작업 정의 파일을 kubectl apply 명령어로 실행하고, log 모니터링을 통해 훈련 상태를 지속적으로 추적 관리할 수 있습니다.
자동화된 로그 모니터링 설정 예시:
- Loss 지연: 4분 이상 Loss 미표시 시 종료
- Checkpoint 지연: 10분 이상 업로드 중단 시 재시도
- 훈련 정지 감지: batch 미출력 지속 시 Job 중단
결론
Amazon SageMaker HyperPod Training Operator는 거대한 클러스터에서 안전하고 효율적으로 대규모 AI 모델을 훈련하기 위한 최고의 솔루션입니다. 특히, 장애 복구 자동화, 편리한 배포 가이드, 로그 기반 모니터링, HyperPod 옵저버빌리티 통합을 통해 수작업 모니터링 및 스크립트 없이도 안정적인 학습 환경을 제공합니다. AI 기술의 활용과 비교 분석, 복잡한 훈련 파이프라인의 자동화를 고민하는 기업에게 SageMaker HyperPod는 좋은 대안이 될 수 있습니다.
직접 실습을 진행하고 싶다면 본 블로그에서 소개한 배포 가이드를 참고해 EKS 기반 훈련 클러스터를 구성한 뒤, PyTorch 기반 예제부터 실험해보시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
