올바른 LLM 선택, 감으로 하지 말고 데이터 기반으로: 360-Eval을 활용한 모델 평가 가이드
최근 생성형 AI와 대형 언어 모델(LLM)의 발전으로 인해 기업들은 다양한 모델 중에서 자신들의 업무에 최적화된 모델을 선택해야 하는 상황에 빠르게 직면하고 있습니다. 하지만 대부분은 단순히 화제성 모델 몇 가지를 테스트해 보는 방식으로 의사결정을 내리곤 하며, 이는 시간과 자원의 낭비로 이어질 수 있습니다. 감(“vibes”)에 의존한 선택은 단기적으로 유용해 보일 수 있지만, 장기적으로는 예측불가능성과 불안정성을 초래합니다. 이 글에서는 AWS에서 제안하는 360도 평가 프레임워크인 360-Eval을 통해 체계적이고 자동화된 LLM 비교 분석과 활용 가이드, 배포 시 고려사항, 평가기준, 사례를 소개합니다.
정량과 정성, 다차원적 평가가 필요한 이유
LLM 선택 시 단순 정확도 외에도 응답 속도(지연 시간), 비용, 완전성, 명확도, 지시 이행 수준 등 다양한 요소를 종합적으로 고려해야 합니다. 기존에는 일부 정답 예시를 통한 정제되지 않은 테스트로 모델을 비교했다면, 이제는 정량-정성 통합 메트릭 기반으로 평가 체계를 구축해야 합니다.
감에 의존한 모델 평가의 문제점은 다음과 같습니다.
- 주관적 판단: 응답의 품질보다는 말투, 단어 선택 등 감성적 요소에 의존.
- 한계 입력만 테스트: 실제 사례를 반영하지 못한 일부 프롬프트로만 평가.
- 일관성 부족: 평가자 간 해석 기준 불일치, 비즈니스 목표와 괴리 우려.
- 추적 지표 부재: 성능 변화 감지 불가능, 최적화에 대한 피드백 불가.
이러한 문제를 해결하기 위해서는 다양한 메트릭을 한 번에 수집 및 분석하는 평가 프레임워크가 필요합니다.
360-Eval: 다차원 LLM 평가 자동화 도구
AWS는 오픈소스로 제공되는 360-Eval 프레임워크를 통해 Amazon Bedrock 또는 SageMaker를 포함한 다양한 LLM들을 비교 평가할 수 있도록 지원합니다. 이는 단일 워크플로우로 여러 모델을 동일 조건에 두고 테스트할 수 있게 도와주는 툴이며, 특히 다음과 같은 기능을 구현합니다.
- 평가 입력 데이터셋 구성 (CSV, JSONL 등)
- 자동 API 호출을 통한 추론 결과 수집
- 정량 평가(속도, 비용), 정성 평가(정답률, 지시 수행률 등)
- LLM-as-a-judge를 통한 품질 판정 자동화
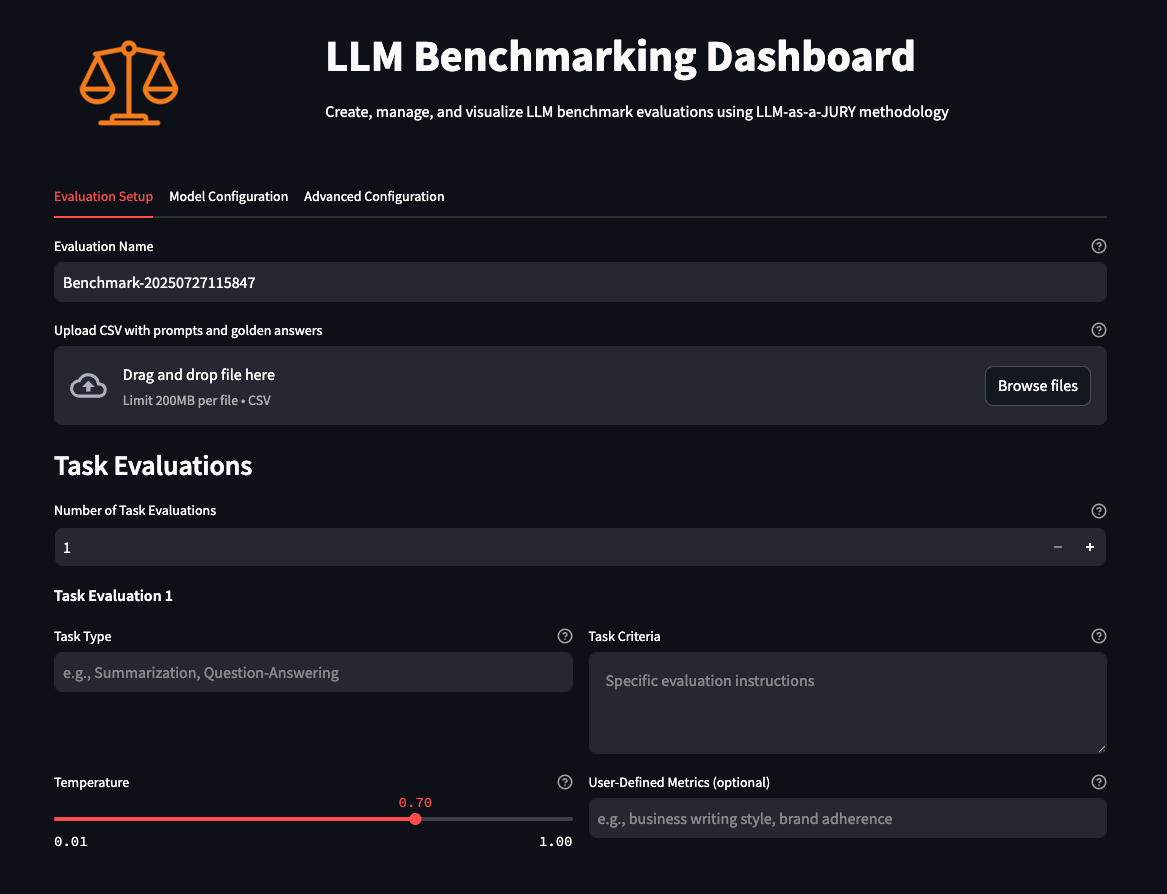
이러한 프로세스를 통해 모델 평가의 반복성과 일관성을 확보할 수 있으며, 팀 내 다양한 LLM 비교 결과를 시각적으로 리포팅할 수 있습니다.
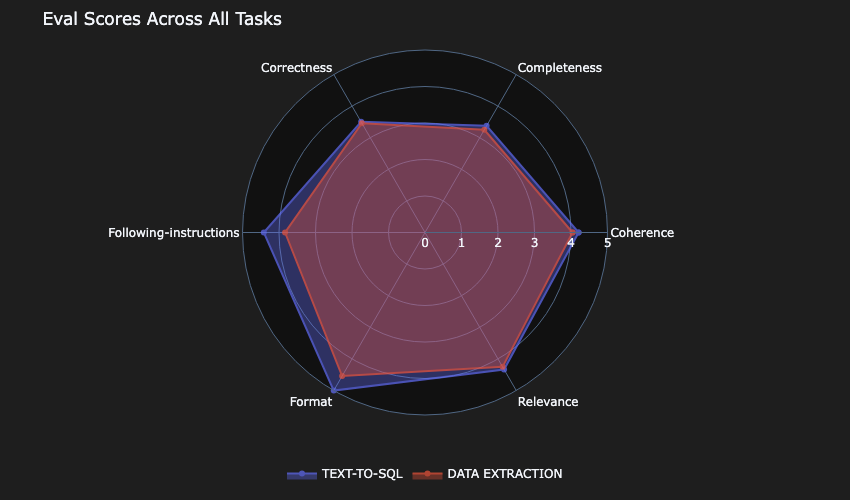
LLM 평가 예시: 데이터 추출과 Text-to-SQL 생성
실제 기업 활용 사례로, AnyCompany는 자연어로 사용자의 요구사항을 입력받아 PostgreSQL 기반 데이터 모델을 자동 생성하는 SaaS 솔루션을 개발 중입니다. 아래 프롬프트는 해당 플랫폼에 입력된 예시입니다.
프롬프트 예:
"전 세계 제조 회사가 재고를 50개 지점에서 추적하며, 200개 이상의 공급업체와의 관계를 관리하고 자재 수요를 예측하여 임계치 도달 시 구매를 자동화하는 웹 기반 SCM 시스템을 사용 중입니다."
이 시나리오에서 모델은 다음 두 작업을 수행해야 합니다.
- 주요 엔티티 + 속성 추출 (예: inventory_id, supplier_id 등)
- PostgreSQL CREATE TABLE 문 생성 (예: TEXT-TO-SQL)
360-Eval은 각 모델의 응답을 정확성, 완전성, 관련성 등 매트릭으로 비교합니다.
360-Eval UI 구성
360-Eval은 CLI 기반뿐만 아니라 UI도 제공하여 사용성을 강화합니다. 주요 화면은 Setup → Monitor → Evaluations → Reports 네 단계로 구성됩니다.
- Setup: 모델 선택, 평가 기준 입력, 동시 실행 설정 등
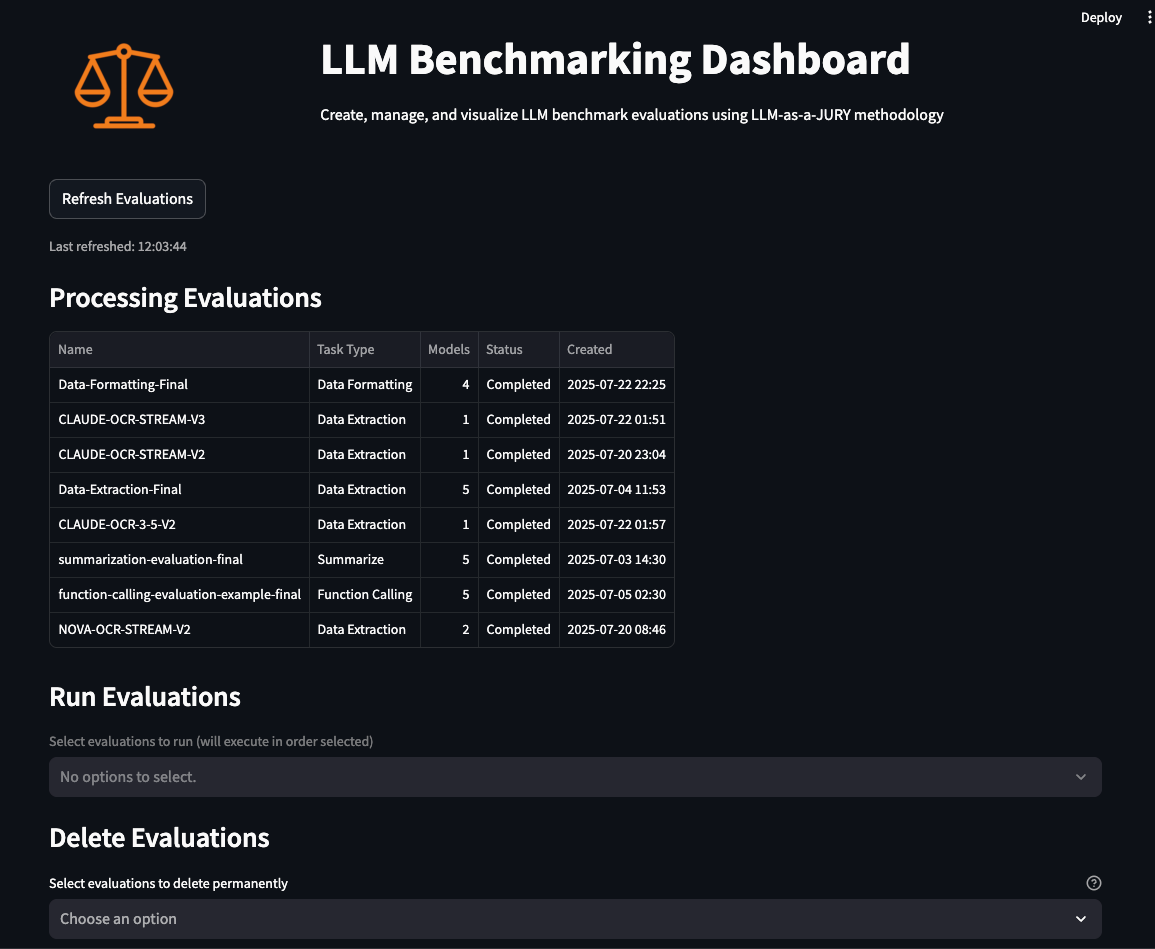
- Monitor: 현재 진행 중인 평가 모니터링
- Evaluations: 상세 메트릭 분석 제공
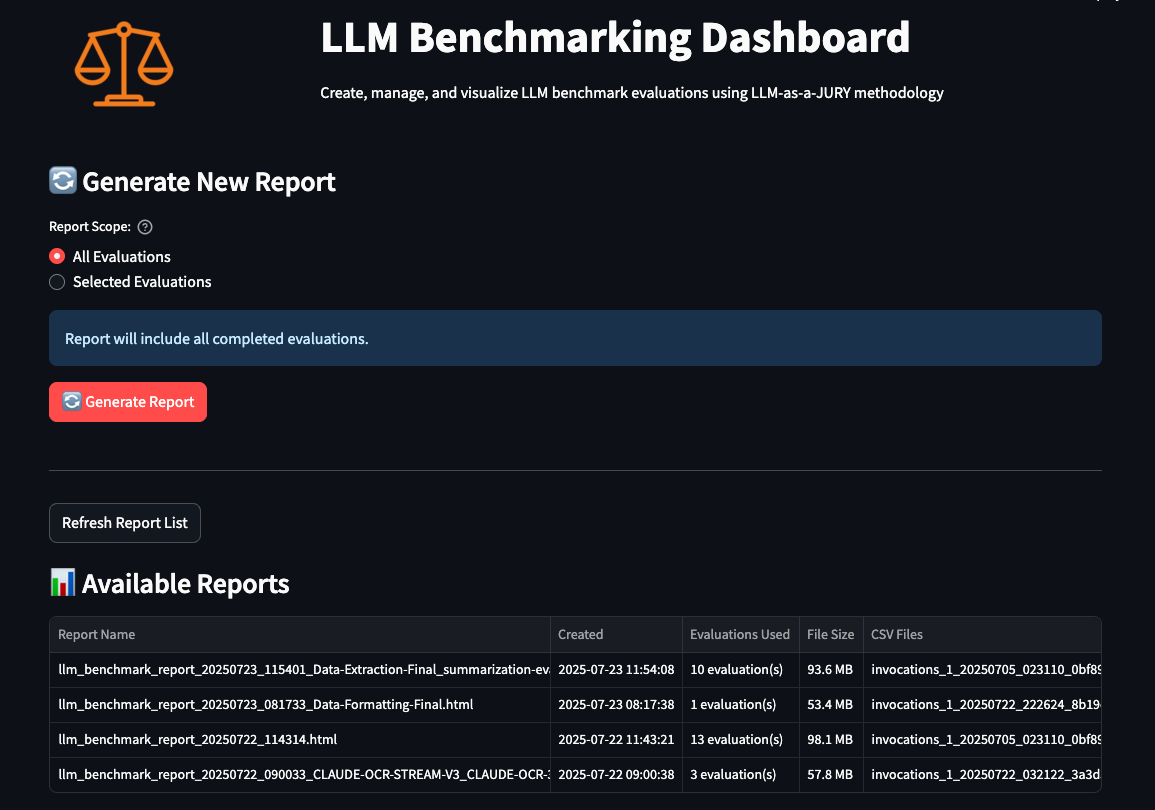
- Reports: 자동 리포트 생성
AnyCompany 사례: 모델 선택 기준
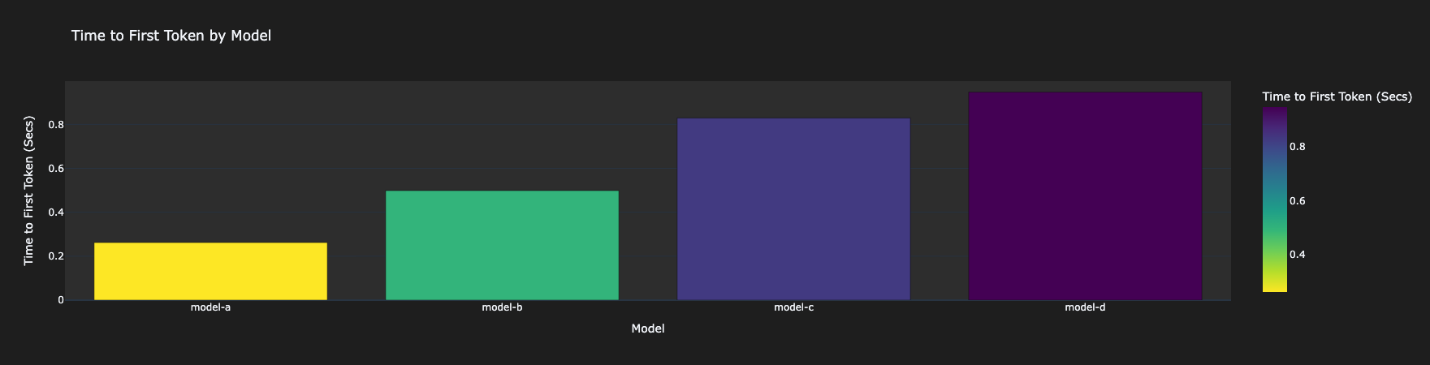
사례 기업은 Amazon Bedrock 내 네 개 LLM(Model-A~D)을 평가한 결과, 다음과 같은 차이를 보였습니다.
- Model-A: 빠르고 비용 저렴하지만 완전성이 부족함
- Model-B: 가장 비용 효율적이나 정확도와 완성도 낮음
- Model-C: 중간 성능, 균형 잡힌 결과
- Model-D: 가장 정확/완전하나 느리고 비용 큼
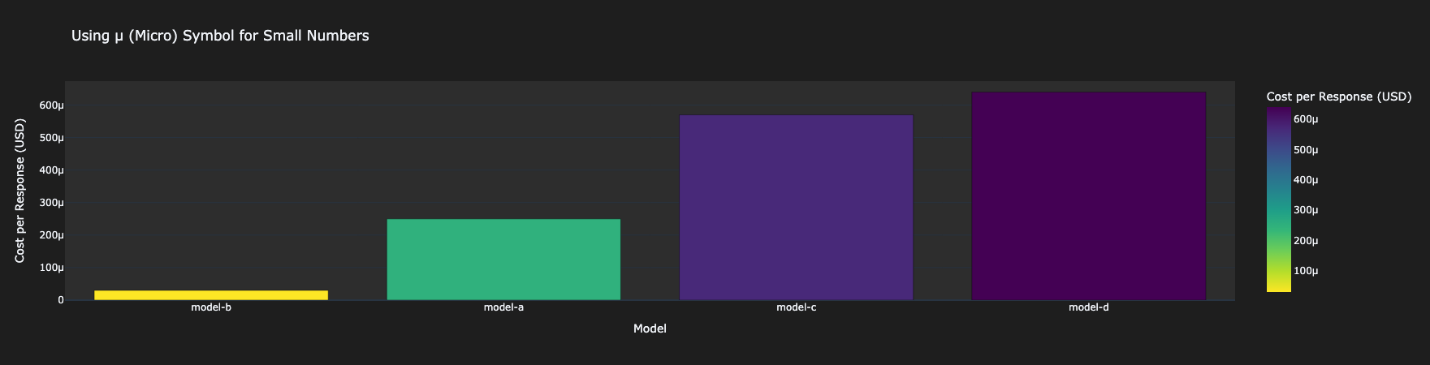
이를 통해 AnyCompany는 과금 모델에 따라 모델을 다르게 채택하는 하이브리드 전략을 수립했습니다.
- Premium Tier: Model-D 사용 (정확도 최우선)
- Basic Tier: Model-A (속도 우선 및 적당한 완성도)
- Free Tier: Model-B (비용 최소화)
결론
LLM의 비교는 단순 응답의 ‘느낌’이 아닌, 명확한 메트릭과 종합적인 자동화 평가 체계를 통해 수행되어야 합니다. 여러분이 LLM 도입을 준비 중이거나 다양한 모델을 평가하는 단계에 있다면, 데이터 기반 선택을 가능케 하는 360-Eval 프레임워크의 도입을 고려해보시기 바랍니다.
이를 통해 조직의 요구사항에 최대한 맞는 모델을 신속하고 효율적으로 선택하고, 배포 및 운영 시 발생할 수 있는 리스크를 최소화하며 자동화 기반의 AI 성능 최적화를 실현할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
