아마존 Bedrock에서의 반복적 파인튜닝(iterative fine-tuning) 사용 가이드
소개
생성형 AI 모델을 실무에 적용할 때 단발성 파인튜닝(single-shot fine-tuning)은 종종 비효율적이고 위험 부담이 큽니다. 한 번의 훈련으로 모든 성능을 개선하려는 이 방식은 결과가 기대에 미치지 못할 경우 전체 프로세스를 처음부터 다시 시작해야 하는 한계가 있습니다. 아마존은 Amazon Bedrock에서 반복 가능한 파인튜닝 기능을 추가하여 이러한 문제를 해결할 수 있게 하였습니다. 이 글에서는 반복적 파인튜닝의 활용 방법과 장점, 실제 적용 사례 및 배포 옵션까지 자세히 다뤄보겠습니다.
본문
반복적 파인튜닝의 주요 특징
반복적 파인튜닝은 이미 커스터마이즈된 모델을 기반으로 소규모 데이터를 이용하여 점진적이고 전략적으로 모델을 개선할 수 있도록 설계되었습니다. 다음과 같은 이점을 제공합니다.
- 리스크 감소: 한번에 큰 변경을 하지 않고 점진적으로 실험과 개선을 반복할 수 있습니다.
- 실시간 사용자 피드백을 반영: 지속해서 들어오는 사용자 데이터를 반영하여 모델을 최신 상태로 유지할 수 있습니다.
- 다양한 활용 사례에 유연한 대응: 초기 훈련 시 고려하지 못한 상황에 대응할 수 있습니다.
어떻게 반복적 파인튜닝을 구현하는가
Amazon Bedrock에서는 콘솔과 SDK를 통해 반복적 파인튜닝을 진행할 수 있습니다.
사전 조건
- 사전에 수행한 파인튜닝 또는 디스틸레이션을 통해 생성된 커스텀 모델 필요
- IAM 권한 설정
- 특정 문제나 기능 개선을 목표로 한 소규모 반복 학습 데이터
- Amazon S3 저장소
콘솔을 통한 구현 방법
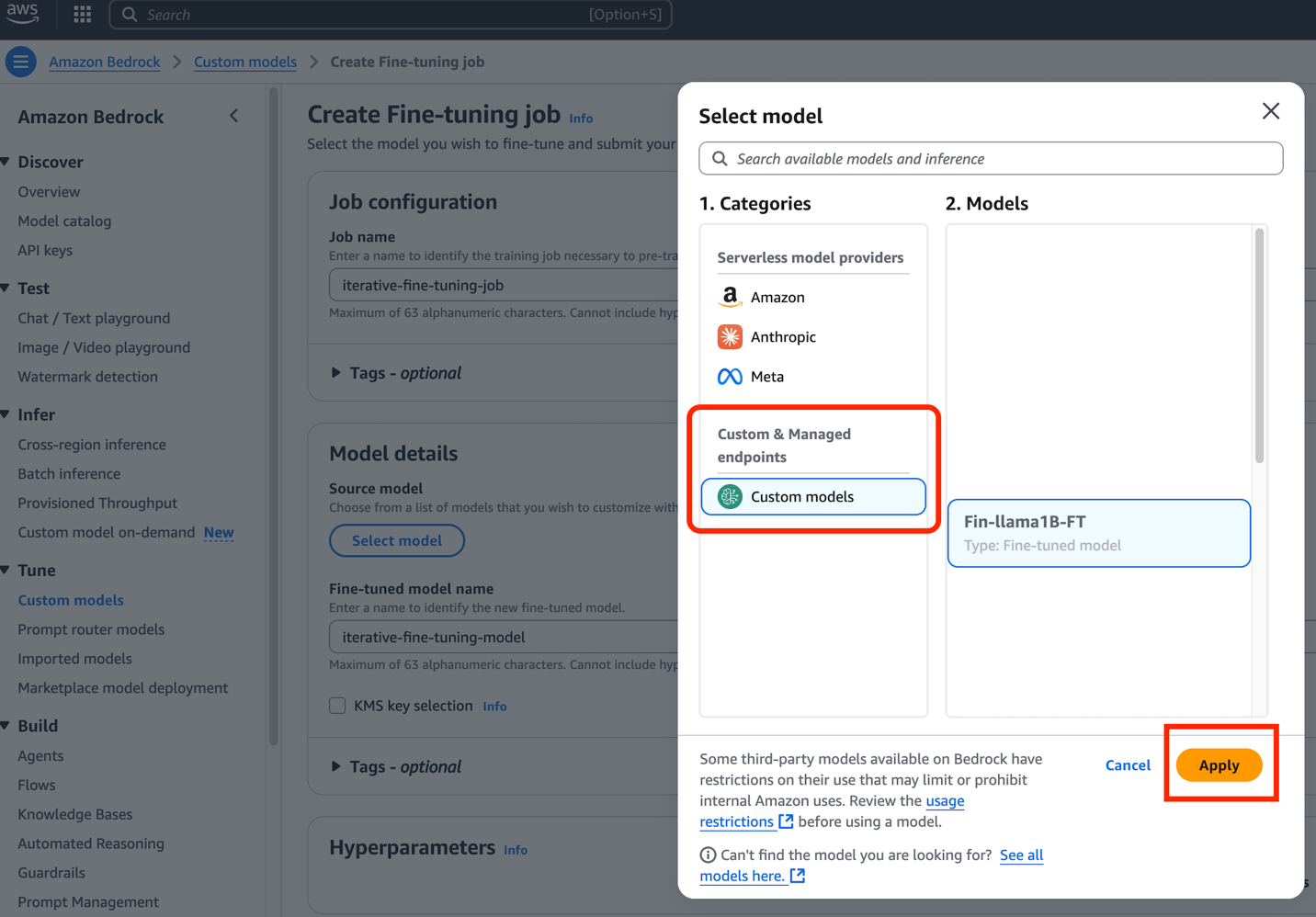
콘솔에서 Custom Models로 이동한 후 "Create fine-tuning job"을 선택합니다. 이때 기존의 커스텀 모델을 기반 모델(Base Model)로 선택하는 것이 핵심입니다.
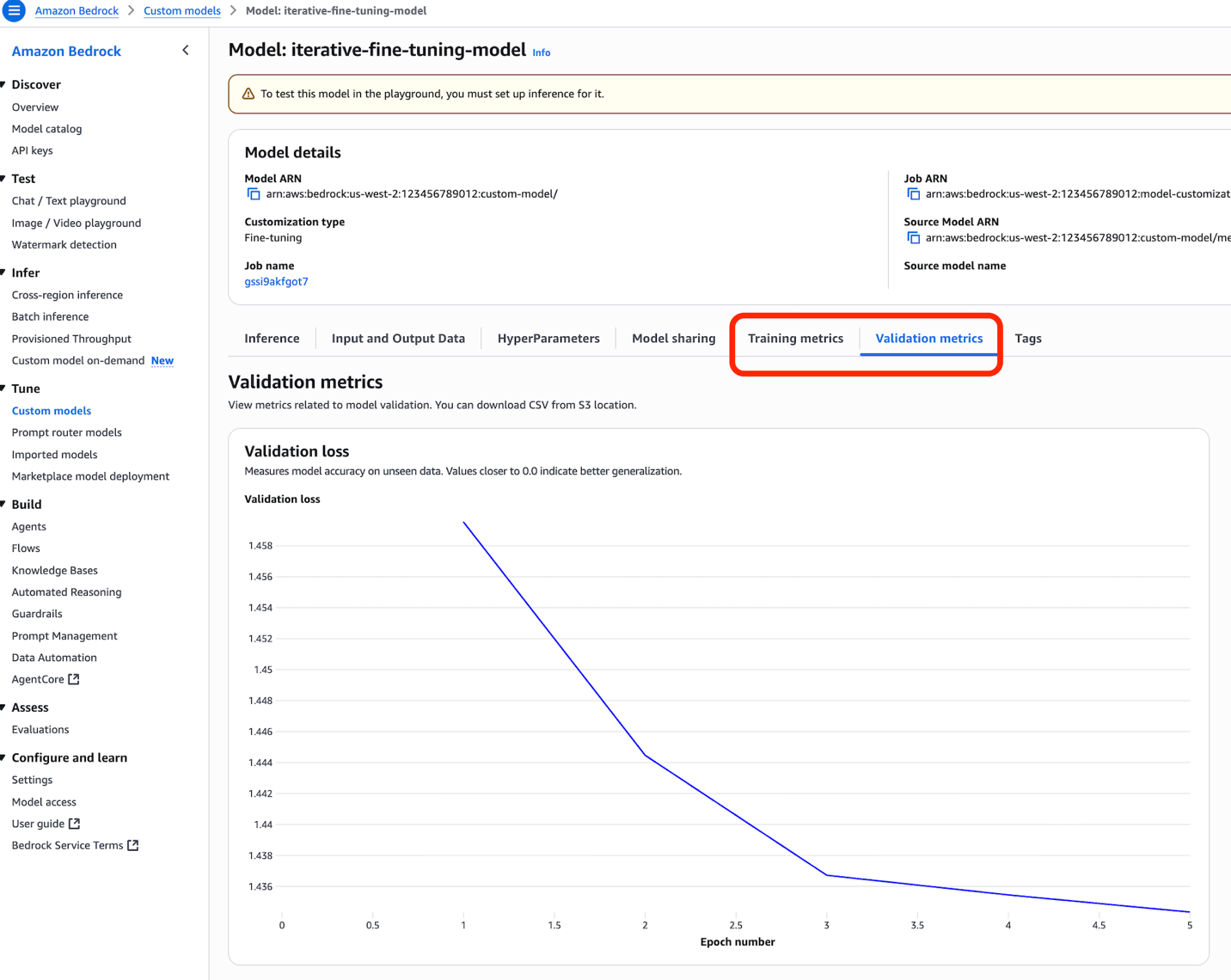
학습이 완료되면 콘솔에서 Training metrics와 Validation metrics 탭을 통해 성능을 모니터링할 수 있습니다.
SDK를 통한 구현 예시
Python의 Boto3 SDK를 이용한 반복적 파인튜닝 설정 코드 예시는 다음과 같습니다.
핵심은 baseModelIdentifier에 이전에 커스터마이즈된 모델의 ARN을 사용하는 것입니다.
이 접근방식을 통해 개발자는 자동화 및 통합된 워크플로우 내에서 손쉽게 학습 작업을 반복할 수 있습니다.
추론 배포 방식
반복적 파인튜닝으로 개선된 모델을 실 서비스에 배포하는 단계에서는 다음 두 가지 방식을 선택할 수 있습니다.
- 제어된 처리량(Provisioned Throughput): 예측 가능한 트래픽에 대해 안정적인 성능 보장
- 온디맨드 추론(On-demand Inference): 변동성 높은 워크로드 및 파일럿 테스트에 적합
활용 사례에 따라 선택이 가능하며, 비용 효율성과 성능의 균형을 맞추는 것이 중요합니다.
반복적 파인튜닝의 모범 사례
- 품질 중심의 데이터 구성: 무작정 데이터를 늘리기보다는 명확한 성능 개선 목표에 맞춘 데이터 구성이 효과적입니다.
- 평가 지표의 일관성 유지: 반복할수록 성능 비교가 중요하므로 동일한 지표 체계를 사용해야 비교가 가능합니다.
- 반복 중지 시점 판단: 성능 개선의 한계점에서도 불필요한 리소스 낭비를 방지하기 위해 반복을 중지하는 판단이 필요합니다.
결론
Amazon Bedrock의 반복적 파인튜닝 기능은 생성형 AI 모델을 체계적으로 발전시킬 수 있는 강력한 도구입니다. 불필요한 재학습 없이 기존 커스텀 모델을 기반으로 한 지속적인 성능 개선이 가능하다는 점에서, 다양한 산업의 AI 모델 운영에 실질적인 기여를 할 수 있습니다. 지금 바로 Amazon Bedrock 콘솔에 접속해 반복적 파인튜닝을 시작해 보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
