아마존 노바(Amazon Nova)를 활용한 문서 AI 최적화 가이드: 파인튜닝과 온디맨드 추론 적용 방법
머신러닝 기술이 발전함에 따라 문서 AI(Document AI)는 단순한 문자 인식을 넘어서 시각적 정보와 텍스트를 동시에 이해해 구조화된 데이터를 추출하고 자동화된 처리 흐름에 활용되는 방향으로 나아가고 있습니다. 특히, 시각 언어 모델(Vision Language Models, Vision LLMs)의 등장으로 인해 인보이스, 세금 양식, 계약서 등 다양한 문서에서 필요한 정보를 정확하게 추출하는 게 가능해졌습니다. Amazon이 제공하는 Nova 모델과 Bedrock 플랫폼을 기반으로 문서 처리 성능을 향상시키는 방법을 살펴보겠습니다.
문서 AI에서 해결해야 하는 주요 과제
다양한 문서의 복잡한 레이아웃이나 품질, 언어 장벽 등은 정확한 데이터 추출을 어렵게 만듭니다. 세금 양식, 인보이스, 대출 양식 같은 전문 양식의 경우, 일반 LLM 기반 자동화 방식은 출력 형식의 일관성이 부족하거나 처리 오류가 잦습니다. 이 때문에 Amazon Nova와 같은 비전 기반 모델을 고도화해 문서별로 모델을 최적화하는 방식이 각광받고 있습니다.
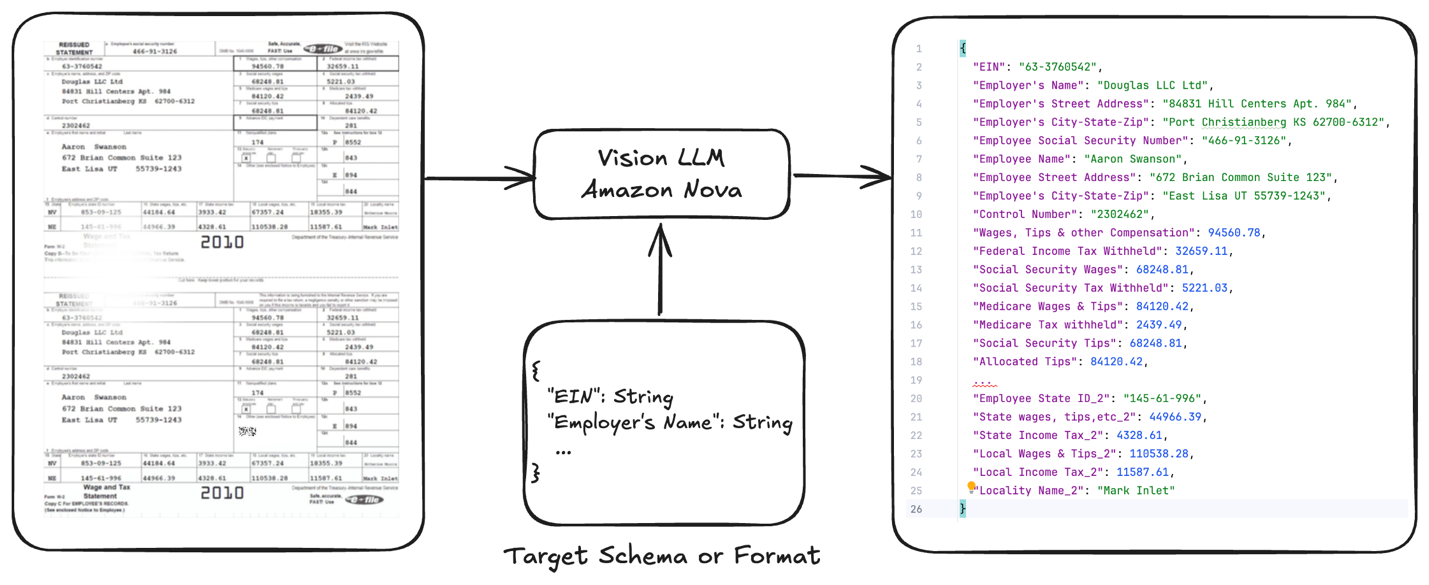
이런 상황에서 Amazon Nova 모델을 특정 문서 유형에 맞게 파인튜닝하고, Amazon Bedrock에서 제공하는 온디맨드 추론(On-Demand Inference) 기능을 활용하면 높은 정확도와 효율적인 비용 관리가 가능합니다.
파인튜닝: Nova 모델을 내 데이터에 맞게 최적화하는 방법
-
데이터 준비: 모델 커스터마이징의 성패는 데이터 품질에 달려 있습니다. Amazon은 오픈 소스 GitHub 코드 샘플을 통해 JSONL 형식으로 학습, 검증, 테스트 데이터를 준비하는 방식과 주의할 점들을 안내하고 있습니다. 예제에서는 W2 세금 양식 데이터셋을 활용하여 모델 성능을 비교 테스트했습니다.
-
파인튜닝 기법:
- 권장되는 방법은 감독 학습 기반의 파인튜닝(Supervised Fine-Tuning)입니다.
- PEFT(Parameter-Efficient Fine-Tuning): 적은 양의 데이터로 빠르게 적용 가능.
- 전체 파라미터 기반 전체 파인튜닝: 충분한 라벨 데이터를 가진 경우 추천.
- 라벨링 방식:
- ERP와 같은 기존 시스템에서 입력·출력 값 추출하여 자동 라벨링
- 수작업으로 노출 빈도가 높은 문서를 중심으로 JSON 형태 라벨링
- 고성능 모델(Nova Premier 등)을 teacher 모델로 활용한 knowledge distillation 방식
- 프롬프트 최적화: 파인튜닝 이전에 System Prompt(작업 정의 및 포맷 지정)와 User Prompt(미디어 파일과 텍스트 조합)를 구성하여 기반 Nova 모델의 성능을 검증하고 정렬된 출력을 도출해야 합니다.
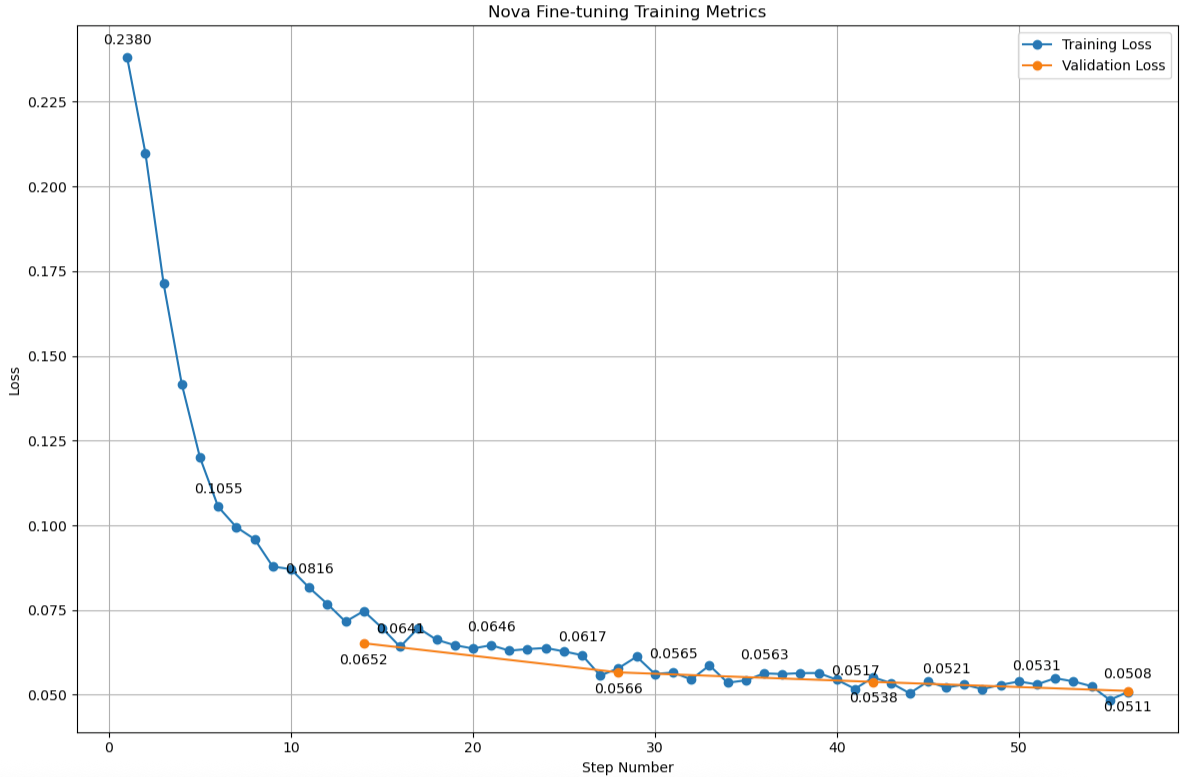
추론 배포 방식: 온디맨드 vs Provisioned 방식 비교
Amazon Bedrock에서는 두 가지 추론 배포 방식을 지원합니다.
-
On-Demand Inference (ODI): 트래픽 예측이 어려운 경우 유용한 방식으로, 처리된 토큰 수 기준으로 과금되어 비용 측면에서 매우 유연하게 활용할 수 있습니다. 자동 확장 기능도 제공되어 사용자가 인프라를 직접 관리할 필요가 없습니다.
-
Provisioned Throughput: 일정 트래픽이 지속되는 서비스에는 고정 처리량 기반의 추론 환경을 배포하면 예측 가능한 성능과 단가를 제공합니다.
아래 예시는 ODI 방식을 통해 파인튜닝된 모델을 어떻게 배포할 수 있는지 보여주는 대표 코드입니다.
def create_model_deployment(custom_model_arn):
deployment_name = f"nova-ocr-deployment-{time.strftime('%Y%m%d-%H%M%S')}"
response = bedrock.create_custom_model_deployment(
modelArn=custom_model_arn,
modelDeploymentName=deployment_name,
description=f"on-demand inferencing deployment for model: {custom_model_arn}",
)
return response.get('customModelDeploymentArn')
성능 비교 평가: 얼마나 정확도가 높아졌는가?
세금 양식(W2 형태)의 구조화 필드 기준으로 베이스 모델과 파인튜닝된 Nova 모델을 비교한 결과, 모든 항목에서 15~39%까지 정밀도가 향상되었으며 주요 필드에서는 100% 리콜(Recall) 값을 유지했습니다.
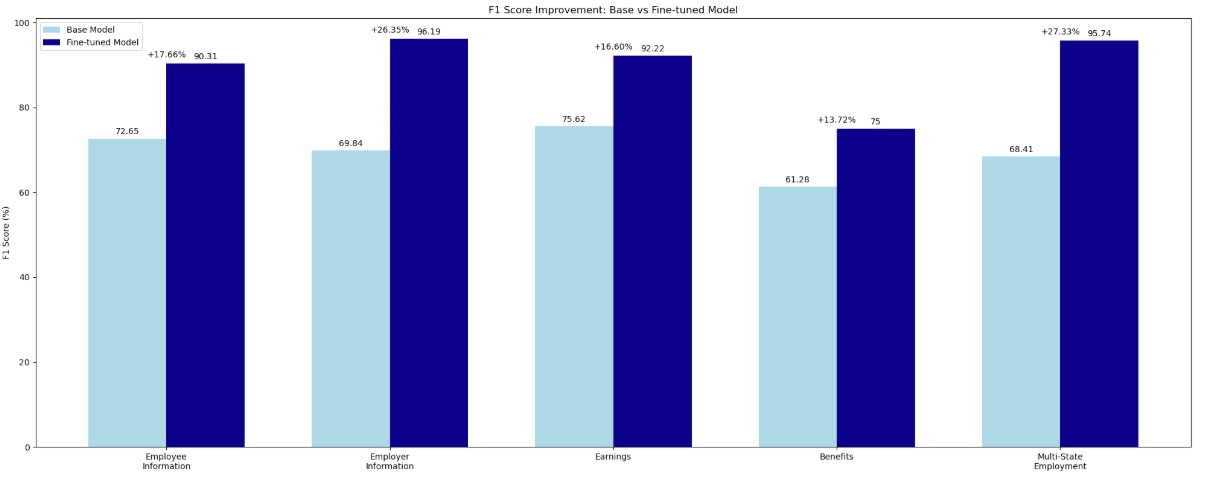
이로 인해 다음과 같은 다양한 활용 가능성을 기대할 수 있습니다.
- 회계 시스템(ERP) 데이터 자동 추출 자동화
- 금융 서류 자동 분류 및 필드 값 채우기
- 복잡한 JSON 출력 구조 대응 가능한 고객지원 시스템 구축
효율적 비용 관리와 클린업 가이드
파인튜닝과 ODI 추론 방식은 구조상 고정 인프라 없이 필요한 만큼만 과금되므로 소규모 예산에도 적용이 가능합니다.
- 파인튜닝 요금: 1K 토큰 단위 × epoch
- 저장 비용: 월 $1.95 / 모델
- 예시 문서 추론: $0.00021 / 페이지
주의할 점은 사용하지 않는 모델은 반드시 배포 종료 및 삭제하여 불필요한 요금이 발생하지 않도록 해야합니다.
결론
Amazon Bedrock과 Nova 모델을 활용한 문서 AI 자동화는 다양한 형태의 실전 업무 환경에 유연하게 대응이 가능한 기술입니다. 특히 세금 양식, 인보이스처럼 필드별 정확도가 중요한 경우, 파인튜닝은 성능을 비약적으로 끌어올릴 수 있는 최적화 전략입니다. 온디맨드 추론 방식은 유연성과 비용 효율성을 제공하며, 실제 비즈니스 워크플로우에 부담 없이 도입 가능한 장점을 겸비하고 있습니다.
정밀도와 재현율을 모두 확보한 모델, 맞춤형 프롬프트 설계, 구조화된 데이터 추출 자동화. 이 세 가지 요소를 통합하여 문서 기반 업무를 본격적으로 AI로 전환해보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
