대규모 언어 모델을 위한 분산 학습 환경, Amazon EKS와 Deep Learning Containers로 완성하기
인공지능 기술이 발전하며 대규모 언어 모델(LLM)의 학습 수요가 폭발적으로 증가하고 있습니다. 최근 Meta의 Llama 3 학습에는 16,000개의 NVIDIA H100 GPU와 3천만 시간 이상의 GPU 사용이 필요했다고 합니다. 이러한 초대형 분산 학습을 위한 인프라로, AWS의 Amazon EKS와 Deep Learning Containers(DLCs)는 매우 강력한 선택지로 각광받고 있습니다. 본 포스팅에서는 수천억 개 이상의 파라미터를 포함한 모델 학습을 위한 Amazon EKS 기반 분산 학습 환경 구성법과 활용 방법, 배포 가이드를 상세히 설명합니다.
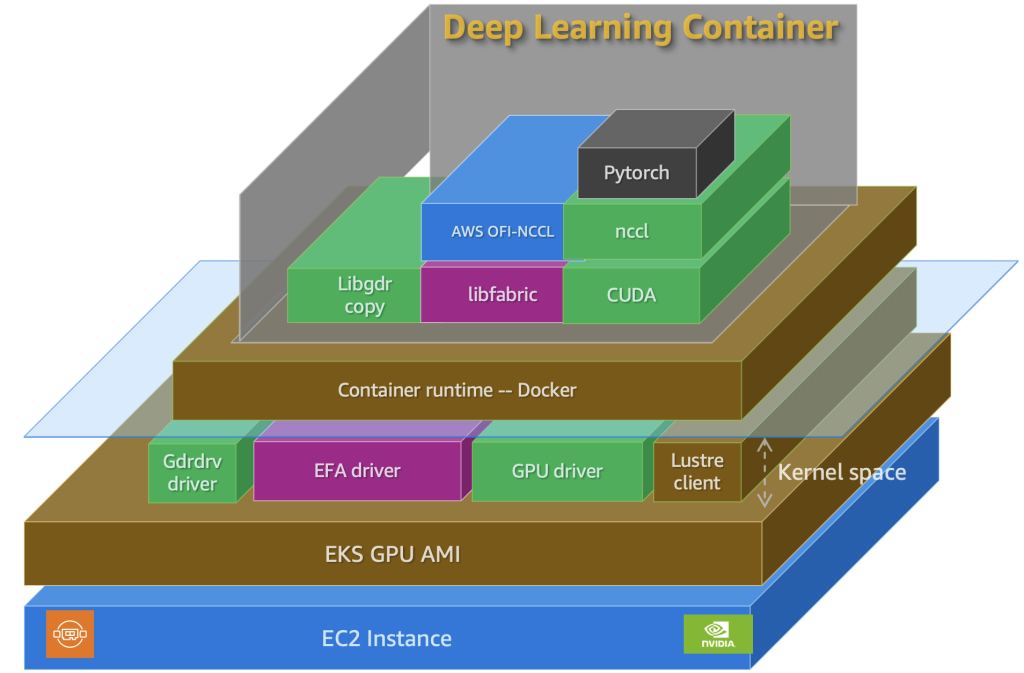
Amazon EKS는 완전관리형 쿠버네티스 서비스로, GPU 인스턴스를 통한 대규모 워크로드의 배포 및 확장을 용이하게 합니다. 여기에 Deep Learning Containers를 더하면, PyTorch와 같은 프레임워크의 최적화된 실행 환경을 손쉽게 준비할 수 있어 학습 자동화와 환경 오류 최소화에 큰 도움을 줍니다.
GPU 인스턴스 선택과 구성 – 성능과 비용의 균형 맞추기
분산 학습 환경에서 가장 중요한 요소 중 하나는 GPU 인스턴스의 선택과 구성입니다. Amazon EC2의 G 계열(G6 등)은 합리적인 비용으로 추론 및 경량 학습에 적합하며, P 계열(P5, P6)은 대규모 모델 학습을 위한 고성능 네트워크 및 메모리 대역폭을 제공합니다. 특히 P5 인스턴스는 8개의 H100 GPU와 640GB의 HBM3 메모리, 3,200Gbps의 EFA 네트워킹을 제공하여 학습 성능을 극대화할 수 있습니다. 그러나 고성능만큼 네트워크 및 저장소와의 세밀한 설정이 필요하므로 자동화된 배포 가이드에 따라 구성을 권장합니다.
커스텀 DLC 이미지 빌드하기 – 종속성 문제를 예방하는 핵심
DLC는 CUDA, cuDNN, NCCL 등을 사전 설치하여 성능 최적화된 컨테이너 이미지를 제공합니다. 하지만 대부분의 분산 학습에는 추가적인 파이썬 라이브러리와 실행 유틸리티가 필요하며, 기본 DLC만으로는 부족할 수 있습니다. 따라서 PyTorch 2.7.1 기반 DLC에 커스텀 종속성을 추가하여 아래와 같이 이미지 빌드합니다.
- Deep Learning AMI 기반 EC2 인스턴스를 시작하여 Docker 환경 설정
- GitHub 저장소 클론 및 build.sh 스크립트로 커스텀 이미지 생성
- 생성된 이미지를 개인 Amazon Elastic Container Registry에 업로드
EKS 클러스터 구성 및 배포 자동화 – YAML 기반 선언적 인프라 관리
분산 학습을 위한 EKS 클러스터는 두 개의 노드 그룹(시스템용 c5, 학습용 p4d)으로 구성됩니다. 해당 YAML 파일에는 자동 확장, 로그 수집, EBS 및 FSx 저장소 연동 등 다양한 플러그인이 포함되어 있어 전체 클러스터 인프라가 완전히 코드로 정의됩니다.
eksctl 명령으로 클러스터를 생성 후, kubectl로 모든 노드 및 플러그인 상태를 다음과 같이 검증할 수 있습니다.
kubectl get nodes
kubectl get pods -A
추가 플러그인 설치 – 학습 수행 전 환경 자동화 마무리
대규모 학습 실행 전 NVIDIA GPU 플러그인, EFA 고속 네트워크, etcd, Kubeflow Training Operator, FSx 및 EBS 저장소 플러그인 등 다양한 요소가 필요합니다.
- NVIDIA GPU 플러그인 자동 포함 또는 수동 설치
- EFA 디바이스 플러그인 설치로 멀티 노드 간 고속 통신 지원
- etcd와 Kubeflow Training Operator로 분산 학습 오케스트레이션 구현
- FSx for Lustre 및 EBS CSI 드라이버 설치로 고성능 저장소 마운트 구성
학습 환경 검증 – 실환경 배포 전 필수 체크리스트
해당 클러스터에 학습을 실행하기 전, 다음 요소들을 반드시 점검해야 합니다:
- GPU 드라이버 버전과 CUDA 호환 여부 (nvidia-smi)
- NCCL 통신 테스트로 AllReduce 등 연산 성능 확인
- PyTorch 기반 샘플 학습 작업 실행을 통해 전체 워크로드 유효성 검증
kubectl apply -f ./fsdp.yaml
완료 후 아래 명령으로 상태 확인
kubectl get pods | grep fsdp
이후 로그 확인을 통한 학습 정상 실행 여부 점검이 중요합니다.
환경 정리 – 비용 최적화를 위한 마무리
실습이 끝난 후에는 다음 명령어를 통해 클러스터를 삭제하여 불필요한 비용을 방지할 수 있습니다.
eksctl delete cluster -f ./eks-p4d-odcr.yaml
결론
Amazon EKS와 Deep Learning Containers를 기반으로 하는 분산 학습 환경은 대규모 LLM 모델 학습을 위한 핵심 인프라로 자리잡고 있습니다. GPU 노드, 고속 네트워크, 강력한 스토리지, 학습 오케스트레이션 기능이 통합된 이 접근법은 학습 리소스 배포부터 모니터링까지의 전 과정을 자동화하며 신뢰성과 확장성을 모두 충족합니다. 저장소와 통신 최적화, 다양한 자동 배포 도구와 비교 리소스를 결합함으로써 개발자는 인프라 대신 모델 성능 향상과 AI 서비스 개선에 집중할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
