세일즈포스가 Amazon Bedrock Custom Model Import를 활용하여 LLM 배포를 혁신한 방법
도입
대규모 언어 모델(LLM)을 운영 환경에 안정적으로 배포하는 것은 많은 기업에게 기술적 도전과제를 안겨줍니다. 특히, 여러 모델을 병렬로 운영하고, 빈번한 업데이트를 반영하며, GPU 자원을 최적화하여 사용할 필요가 있는 조직에게는 큰 부담이 됩니다. 이번에 소개할 세일즈포스(Salesforce)의 사례는 Amazon Bedrock의 Custom Model Import 기능을 활용하여 이러한 문제를 효과적으로 해결한 방법을 보여줍니다. 본 글에서는 실제 활용 사례, 자동화된 MLOps 연동, 배포 가이드, 성능 벤치마크, 비용 최적화 전략 등을 통해 어떻게 이들이 AI 플랫폼의 유연성과 효율성을 극대화했는지 알아보겠습니다.
본문
기존의 LLM 배포는 인스턴스 패밀리 선택, 서빙 엔진 구성, 인프라 튜닝 등의 복잡한 과정을 동반했으며, GPU 자원을 사전 예약해야 하는 구조로 인한 비용 발생도 만만치 않았습니다. 세일즈포스는 지속적인 모델 배포 지연과 운영 부하 문제를 해결하기 위해 Amazon Bedrock의 Custom Model Import 기능을 도입하였습니다. 이 기능은 Llama, QWEN, Mistral 등 다양한 모델을 직관적으로 API를 통해 등록하고, 서버리스 기반으로 배포 및 추론할 수 있게 해 줍니다.
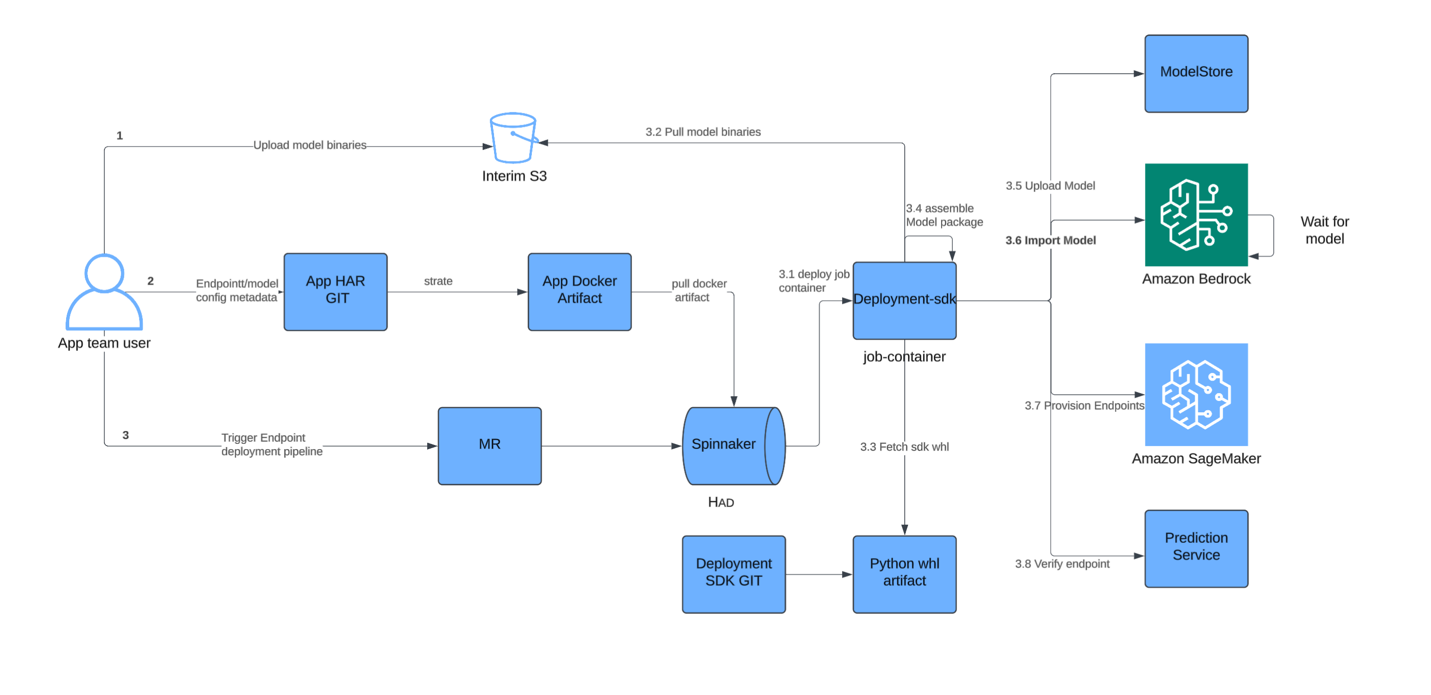
MLOps 워크플로우 통합 방식
세일즈포스는 기존 Amazon SageMaker 기반의 MLOps 파이프라인을 유지하면서, Amazon Bedrock으로 서서히 이전하는 전략을 선택했습니다. 기존 모델 CI/CD 파이프라인에서 Amazon S3에 모델을 저장하고, 이후 Amazon Bedrock Custom Model Import API를 호출하여 모델을 등록합니다. 이 전체 프로세스는 기존 배포 시간(약 1시간) 내에서 완료되며, 모델 등록에 소요되는 추가 시간은 단 5~7분 수준입니다.
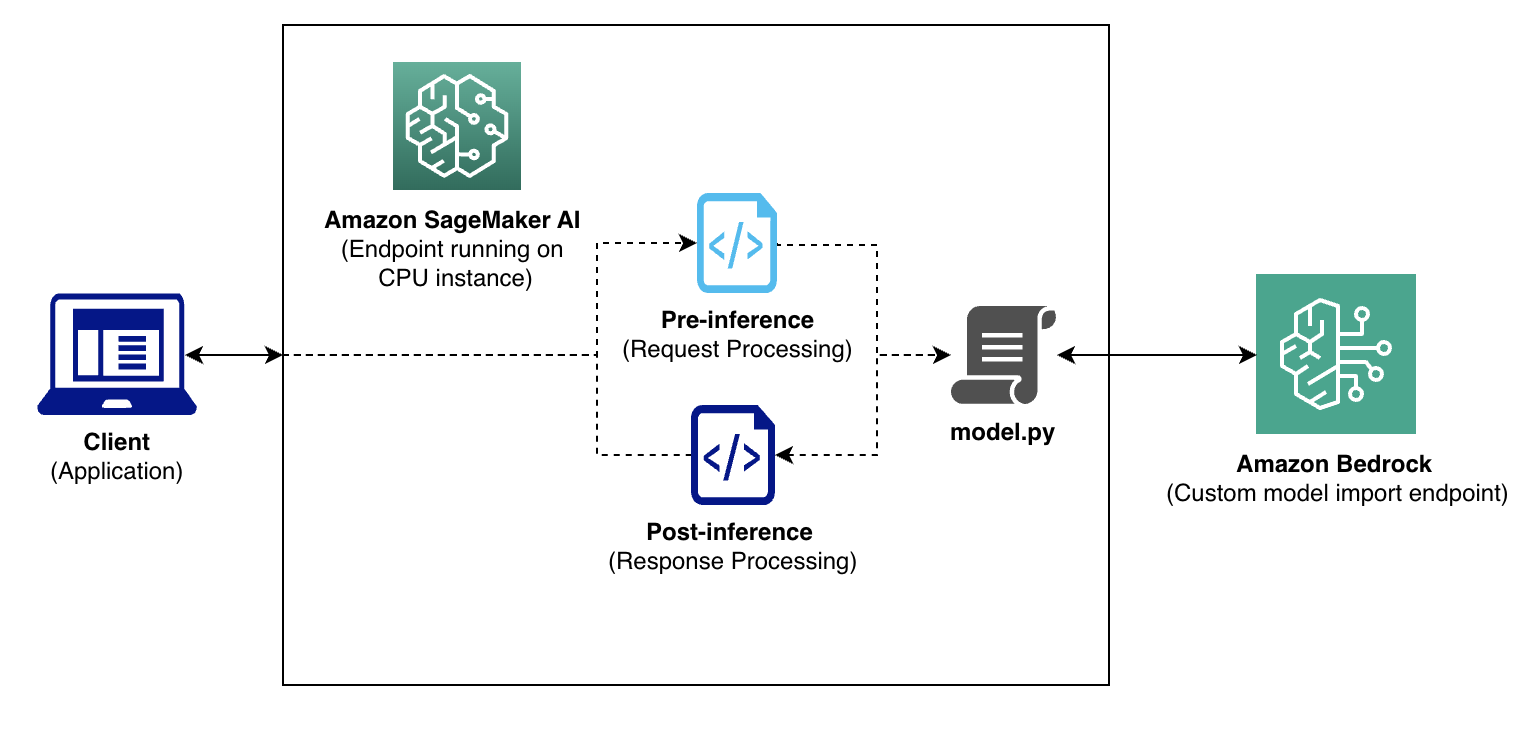
특히 기존 SageMaker 인프라와의 호환성을 최대한 높이기 위해, 추론 요청은 SageMaker의 CPU 컨테이너를 통해 전처리 및 후처리를 거쳐 Amazon Bedrock으로 전달됩니다. 이는 기존 애플리케이션 인터페이스의 변경 없이도 새로운 인프라의 이점을 누릴 수 있게 하며, SageMaker의 로깅 및 모니터링 기능도 계속 활용할 수 있는 장점이 있습니다.
자동 확장 및 성능 벤치마크
배포 가이드의 일환으로 세일즈포스는 Amazon Bedrock의 자동 확장 기능에 대한 부하 테스트를 수행하였습니다. 다양한 동시 요청 수 시나리오를 기반으로 테스트한 결과, Amazon Bedrock은 낮은 부하에서는 GPU 인프라보다 44% 낮은 지연시간을 보였고, 높은 부하에서도 응답 시간이 10ms 이내로 유지되며 안정적인 처리량을 확보했습니다.
예시는 다음과 같습니다:
- 동시 요청 1건 시, P95 지연시간: 7.2초, 처리량: 11회/분
- 동시 요청 32건 시, 지연시간: 10.4초, 처리량: 232회/분
이는 Amazon Bedrock이 LLM 자동 확장 환경에서도 생산 환경에 적합한 성능을 유지할 수 있음을 보여줍니다.
운영 효율성과 비용 절감
베드록 기반 구조 도입 효과는 뚜렷했습니다. 전체 모델 배포 및 반복 실험 시간이 약 30% 단축되었으며, 예약 GPU 인스턴스의 필요성을 제거하고, 유휴 인프라 비용을 줄임으로써 최대 40%의 비용 절감을 실현했습니다. 특히, 테스트 및 개발 환경에서 GPU를 상시 할당하지 않아도 된다는 점은 페이퍼 유즈 기반 아키텍처의 핵심 장점으로 평가되었습니다.
비교 및 자동화 가이드
Amazon SageMaker 대비 Bedrock의 가장 큰 이점은 자동화된 서버리스 추론 환경과 빠른 모델 등록 프로세스였습니다. 다만, 일부 고도화된 GPU 최적화 및 커스텀 연산이 필요한 경우에는 여전히 SageMaker의 사용이 권장됩니다. 활용 시 유의할 점으로는 대형 모델 초기 로딩 시 Cold Start가 수 분까지 발생할 수 있으므로, 주기적인 Health Check 호출로 엔드포인트를 Warm 상태로 유지 관리할 필요가 있습니다.
결론
Salesforce의 사례는 자동화, 비교 적용, 서버리스 기반 AI 배포, 기존 인프라와의 하이브리드 통합 등 다양한 활용 방법을 통해 Amazon Bedrock Custom Model Import의 효율성과 확장성을 입증한 대표적 사례입니다. 특히, 엔드포인트 재설정이나 애플리케이션 수정 없이 LLM을 유연하게 통합하고, 지속적으로 변화하는 AI 환경에 빠르게 대응할 수 있는 탄탄한 기반을 마련한 점이 인상적입니다.
모델 아키텍처 호환성 확인, Cold Start 대비 전략, 운영 도구와의 연동 유지 등 몇 가지 체크포인트를 사전에 검토하면, 여러분의 조직도 서버리스 기반 AI 배포의 이점을 누릴 수 있습니다. Amazon Bedrock의 Custom Model Import는 복잡한 AI 인프라 관리를 줄이고, 빠른 활용 및 배포를 실현하는 실용적인 대안입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
