기업의 복리후생 클레임 처리 자동화, Amazon Bedrock Data Automation으로 가속화하기
조직이 복리후생을 제공할 때, 그 혜택이 효과적으로 전달되도록 보장하는 핵심 절차 중 하나가 '클레임 처리'입니다. 하지만 이 프로세스는 종종 오래된 시스템에 의존하거나 수동 업무가 많아 비효율적이며, 오류율이 높고 운영비용도 컸습니다. 이번 글에서는 AWS의 Amazon Bedrock Data Automation을 활용한 지능형 자동화를 통해 이 복리후생 클레임 처리 업무를 어떻게 개선할 수 있는지를 알아보겠습니다. 실제 활용 사례와 함께 클레임 처리 자동화 방식, 시스템 아키텍처, 자동화 활용 방법 등을 단계별로 정리해 설명합니다.
Amazon Bedrock Data Automation이 해결하는 과제
전통적인 복리후생 클레임 프로세스는 다음과 같은 문제에 직면합니다.
- 수작업 중심의 시스템으로 인한 낮은 처리 속도와 높은 오류율
- 데이터 불일치와 누락으로 인한 재처리 발생
- 규제 준수(HIPAA, ERISA) 확보의 어려움
- 시스템 통합 부족으로 인한 확장성 문제
- 사기 및 낭비 탐지 한계
Amazon Bedrock Data Automation은 이러한 문제를 해결하기 위해 자연어 처리(NLP), 지능형 문서 인식, 대규모 언어 모델(LLM)을 조합하여 운영 프로세스를 자동화하고, 불필요한 반복 작업을 줄이며, 복잡한 비즈니스 규정을 정형화해 사람의 개입 없이 준수할 수 있도록 돕습니다.
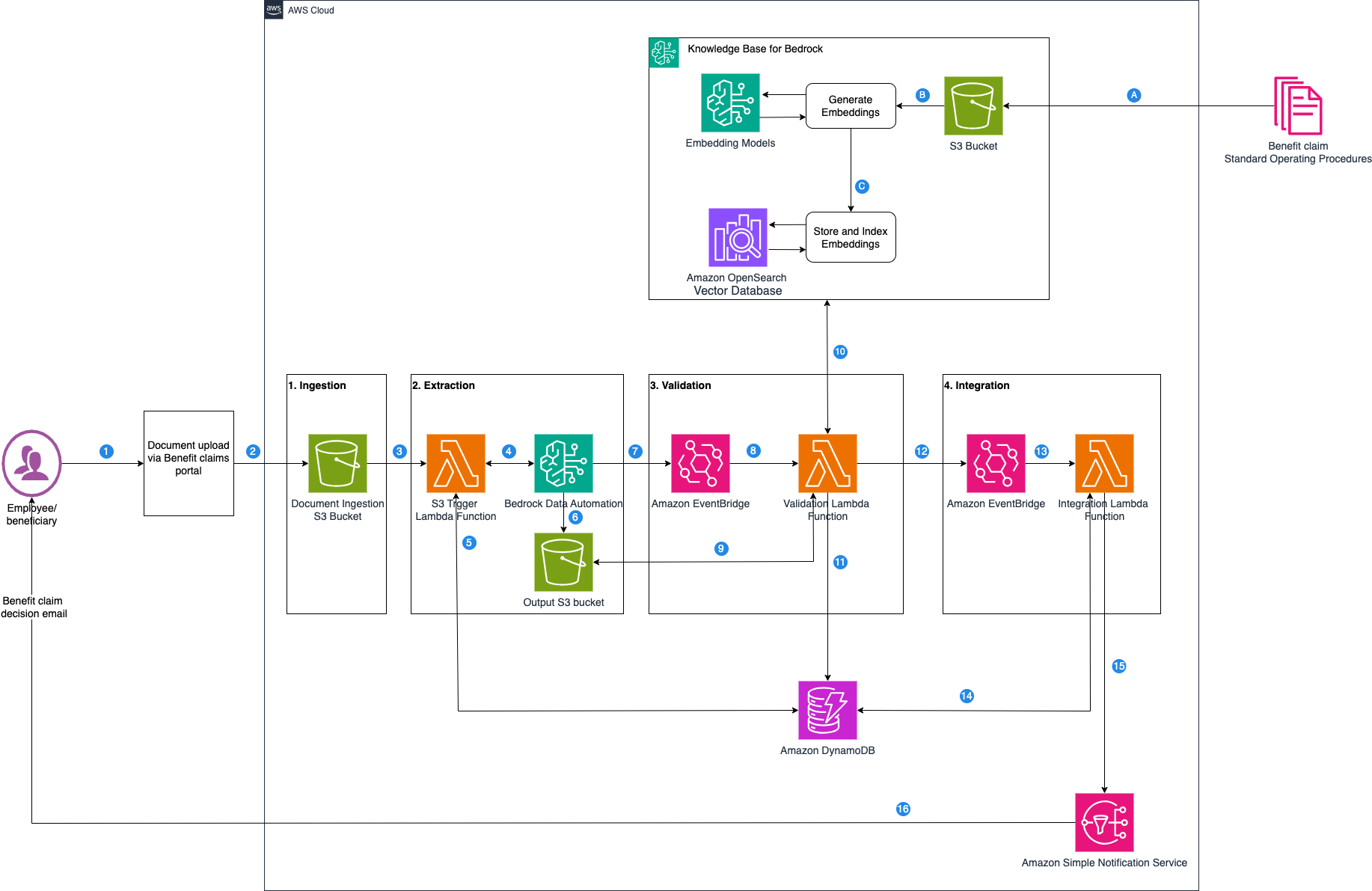
자동화 적용 사례: 복리후생 클레임 처리 흐름
Amazon Bedrock Data Automation을 기반으로 한 클레임 자동화 솔루션은 총 4단계로 구성됩니다: 데이터 수집 → 정보 추출 → 검증 및 판단 → 통합.
데이터 수집(INGESTION)
사용자가 클레임을 제출할 때 처방전과 약국 영수증, 수표 이미지를 복리후생 포털에 업로드하면 Amazon S3에 저장되며, 이로써 자동 처리 파이프라인이 시작됩니다.
정보 추출(EXTRACTION)
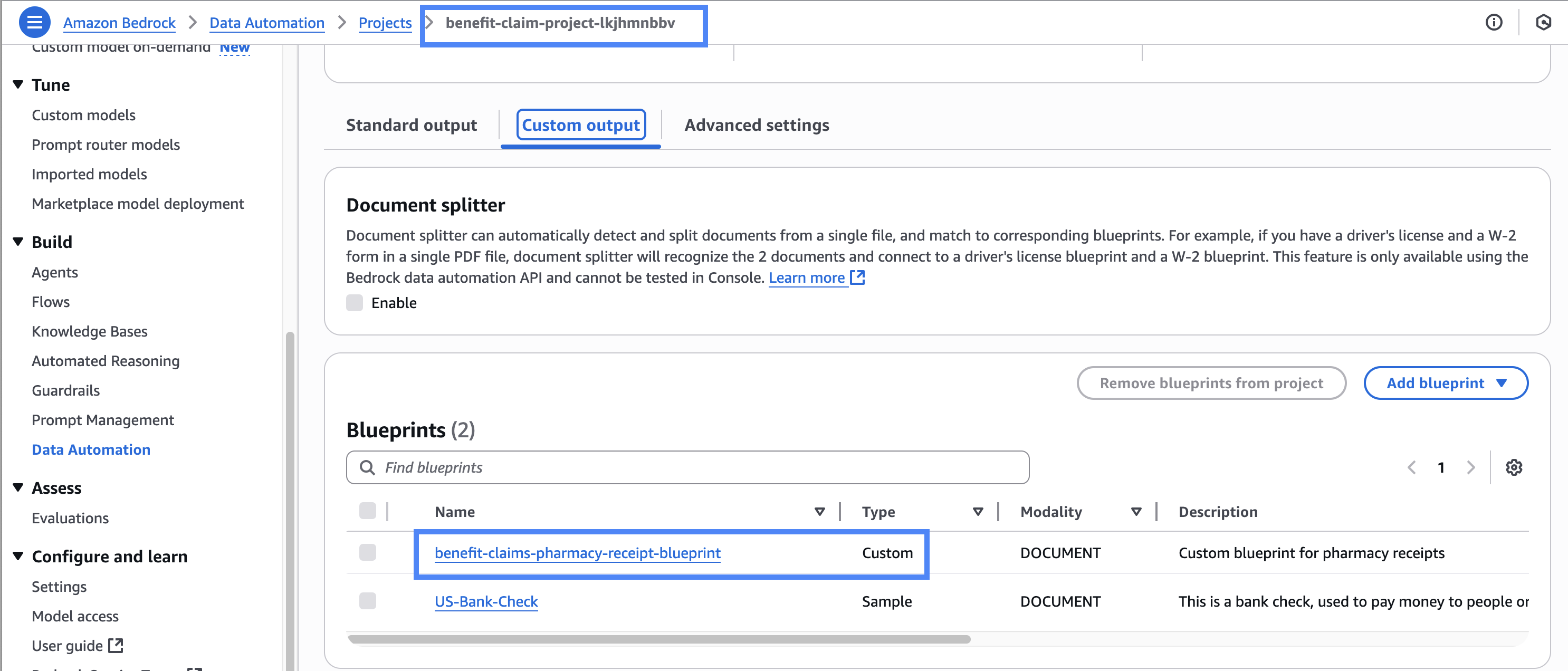
S3에 문서가 저장되면 AWS Lambda가 Amazon Bedrock Data Automation 프로젝트를 호출합니다. 이 프로젝트 내에서는 미리 정의된 블루프린트(예: US-Bank-Check), 혹은 사용자 지정 블루프린트(benefit-claims-pharmacy-receipt-blueprint)를 통해 문서에서 정보를 추출합니다.
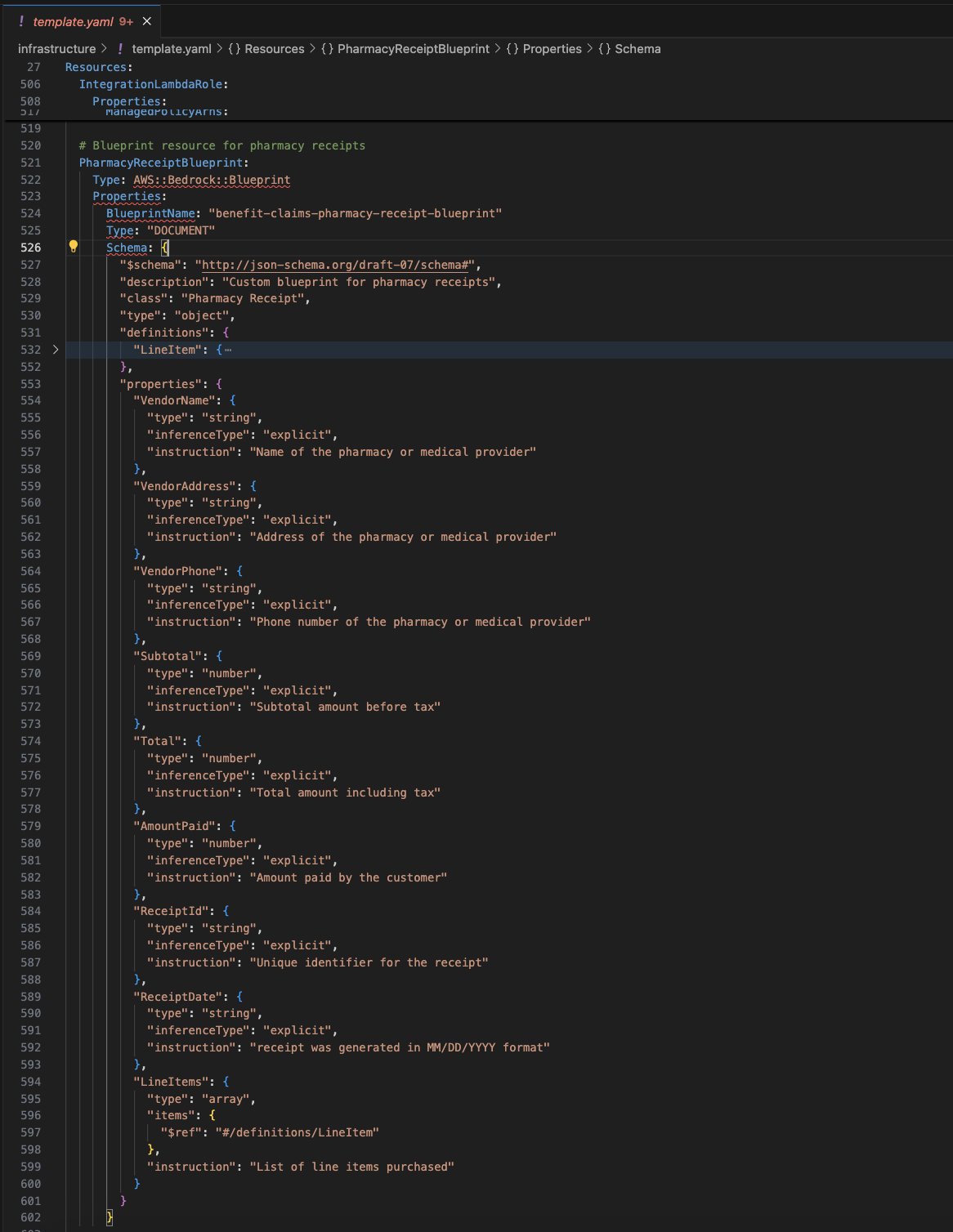
문서 유형에 따라 추출 대상 필드(예: VendorName, 금액 등)와 형식(string, number 등), 자연어 규칙이 정의되며, 자동 분류 및 데이터 추출이 이루어집니다.
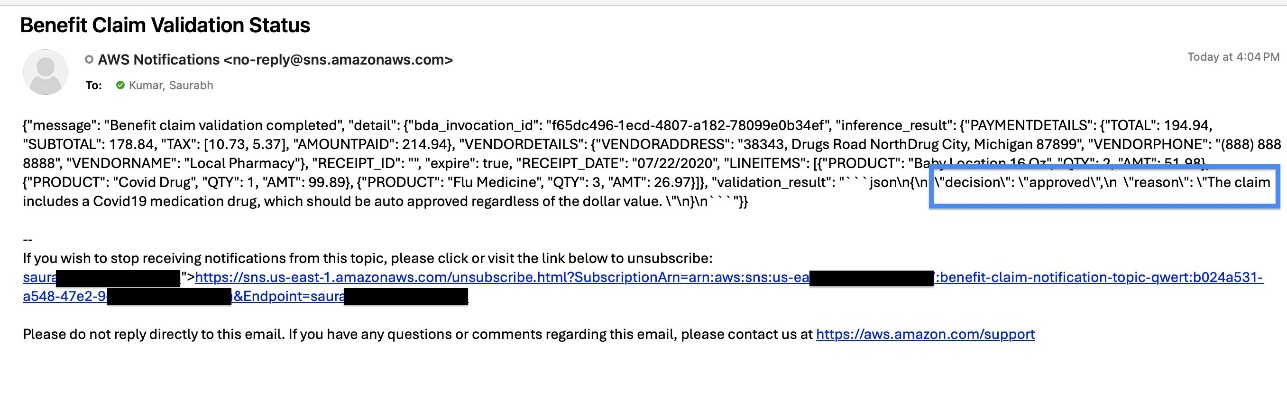
검증 및 자동 판단(VALIDATION)
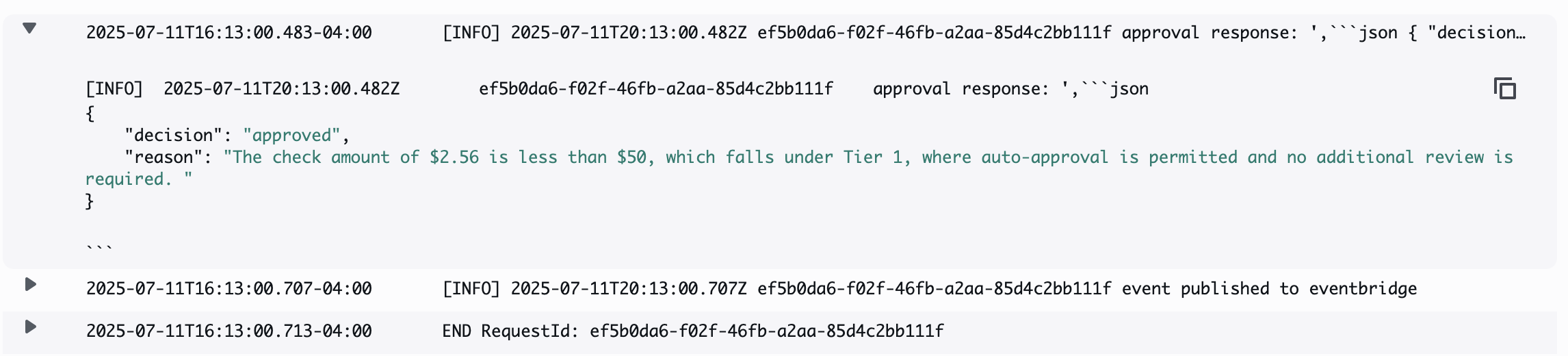
추출된 데이터는 문서 유형에 따라 해당하는 기업의 표준운영지침(SOP)이 저장된 Amazon S3를 활용하여 Amazon Bedrock Knowledge Base로 구성된 지식 기반에서 규칙을 가져옵니다. 이후 Amazon Nova Lite LLM이 이를 바탕으로 승인 여부를 자동으로 판단합니다.

통합(INTEGRATION)
최종 판단 후 Amazon EventBridge를 통해 후속 이벤트가 발생하며, 이 이벤트는 Lambda를 호출해 AWS DynamoDB에 결과를 저장하고 Amazon SNS를 활용해 이메일로 결과를 전송합니다.
유연한 아키텍처를 통해 기존 HR 시스템이나 클레임 시스템, 이메일 시스템과 API 또는 이벤트 기반으로 쉽게 통합이 가능합니다.
비즈니스 규칙의 자동화된 지식 기반 관리
특히 주목할 부분은 SOP 파일을 기반으로 한 Amazon Bedrock Knowledge Base 구축입니다. 별도의 코딩 없이 비즈니스 룰이 자동으로 반영되며, 규정이 변경되더라도 지식 기반만 업데이트하면 되어 정기적인 시스템 재개발 필요없이 빠르게 시장에 대응할 수 있습니다.
배포 및 활용 방법(Deployment Guide)
이 솔루션은 AWS CloudFormation 템플릿으로 손쉽게 배포할 수 있으며, 배포 전 필요 구성 요소는 다음과 같습니다.
- AWS 계정
- Amazon Bedrock 및 사용 가능한 Foundation Model(Nova, Titan)
- AWS SAM CLI 및 Python 설치
- 샘플 코드 GitHub 저장소 클론: https://github.com/aws-samples/sample-accelerate-benefits-claims-processing-with-amazon-bedrock-data-automation
간단한 배포 명령 실행만으로 서버리스 아키텍처 기반의 클레임 자동화 시스템을 구축할 수 있으며, Boto3 기반의 Python 스크립트를 활용해 워크플로 확장도 용이합니다.
결론
Amazon Bedrock Data Automation 기반의 복리후생 클레임 자동화 프로세스는 높은 정확도와 규정 준수를 확보하면서도 수작업 부담을 줄이고 처리 속도를 획기적으로 높일 수 있습니다. 특히 다음의 주요 활용 및 비교 포인트가 돋보입니다.
- 자동 분류·추출 기능으로 기존 수기 입력 업무 대체 및 오류 감소
- 지식 기반 중심 자동 판단 구조로 규제 변경에 대한 신속한 대응
- 사기 탐지 및 통합 분석을 통한 비용 제어
- 기존 HR 시스템 및 클레임 플랫폼과 유연한 연결
- 클라우드 기반 확장 구조로 높은 유연성과 자동화 수준 확보
향후 AWS의 생성형 AI 및 자동화 기술을 적용하고자 하는 기업이라면, 이 가이드는 매우 유익한 베이스라인을 제공합니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
