Amazon SageMaker HyperPod Task Governance를 활용한 세밀한 리소스 할당 가이드
머리말
AI 도입이 가속화되고 있는 산업 현장에서 GPU, CPU, 메모리 등의 클러스터 자원을 효과적으로 할당하는 방법은 매우 중요한 과제가 되었습니다. 특히 다수의 팀이 협업하고 있는 MLOps 환경에서는 리소스를 공정하게 분배하면서도 클러스터 활용률을 최대화하는 전략이 필수입니다.
Amazon SageMaker HyperPod는 이런 과제를 해결하기 위한 강력한 솔루션으로, 이번에 발표된 Task Governance의 세밀한 리소스 할당 기능은 다양한 팀과 프로젝트의 요구사항에 맞춰 정교한 자원 분배와 자동화를 실현할 수 있도록 지원합니다.
본 포스트에서는 HyperPod Task Governance의 주요 기능, 활용 사례, CLI 및 콘솔 환경에서의 배포 안내, 할당 비교 포인트 등 실무 적용에 필요한 정보를 단계별로 안내합니다.
주요 기능 및 사례
HyperPod Task Governance의 핵심은 세밀한(GPU, vCPU, 메모리 단위) 자원 할당 기능입니다. 관리자는 GPU 개수는 물론, 인스턴스 타입에 따른 vCPU 및 메모리 할당까지 조정 가능하며, 팀 단위 우선 순위와 비율까지 설정할 수 있습니다.
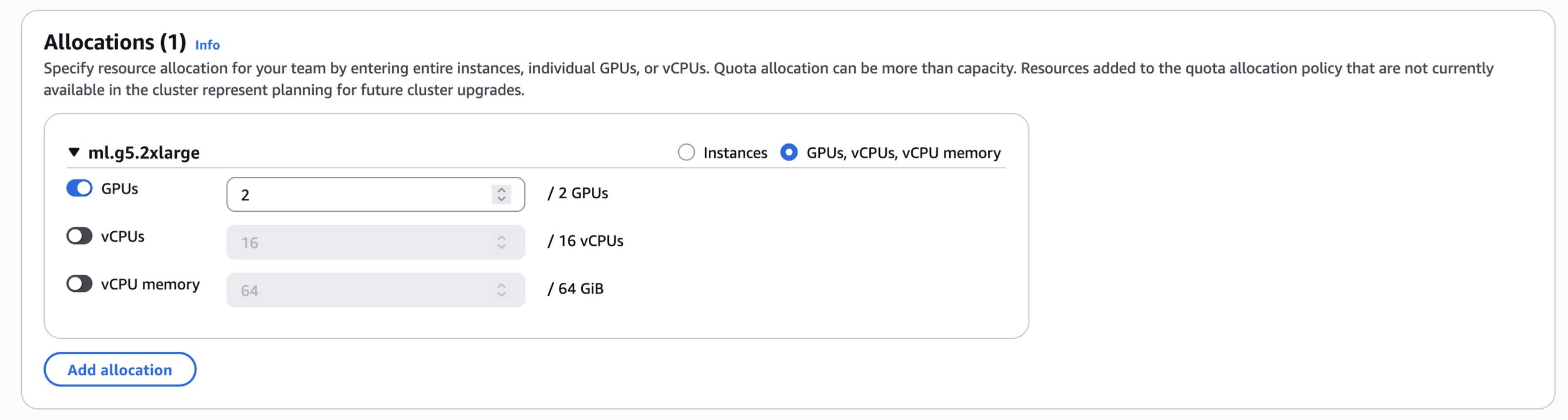
예를 들어 p5.48xlarge 인스턴스 1개당 8개의 H100 GPU, 192 vCPU, 2TiB 메모리를 포함하고 있는 경우, 이 중 2개의 GPU만 할당하면 HyperPod는 자동으로 48 vCPU와 512 GiB 메모리를 기본값으로 계산하여 적용합니다.
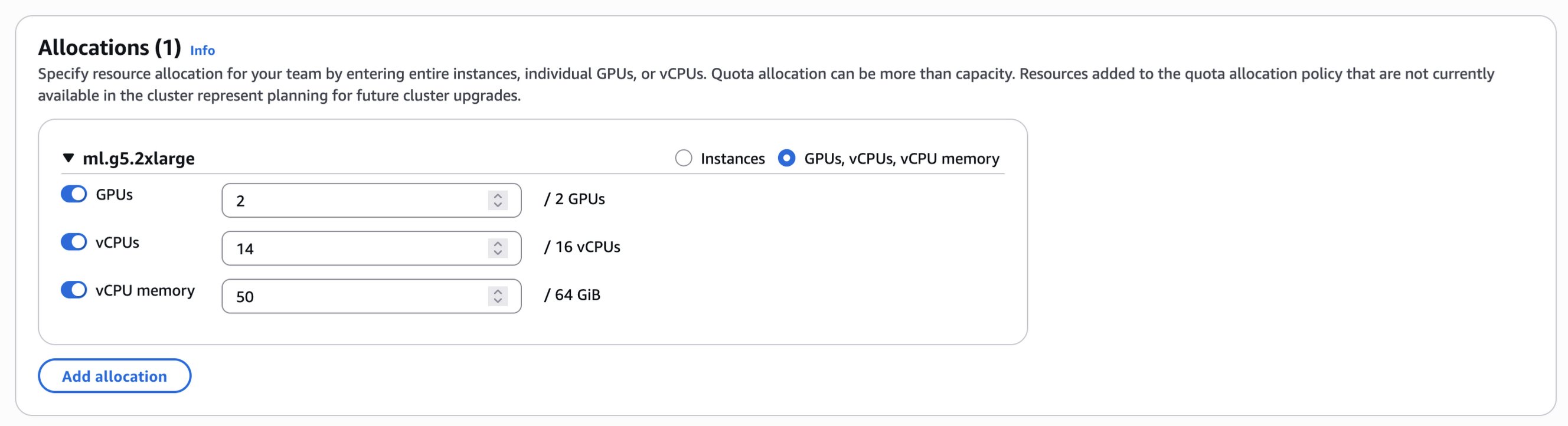
할당값은 필요에 따라 수동으로 조정할 수도 있어 특정 프로젝트의 요구사항이나 예산 계획에 따른 유연한 배포가 가능합니다.
또한 각 할당에는 Fair Share Weight를 부여해 공정한 클러스터 자원 활용이 가능하며, Task 우선 순위에 따라 idle 상태 자원을 자동 분배하거나 저우선 순위 태스크를 선점(preempt)할 수 있는 정책을 지정할 수 있습니다.
활용 시나리오
세밀한 자원 할당은 소규모 LLM(Small Language Model), Inference 엔드포인트, 개발 IDE(JupyterLab 등) 운영에 적합합니다. 한 명의 데이터 사이언티스트가 많은 GPU를 독점하지 않고, 1~2개의 GPU만으로도 실험을 수행할 수 있기 때문에 남는 GPU가 클러스터 내 다른 팀에게 양도되어 전체 GPU 활용률을 끌어올릴 수 있습니다.
- 모델 훈련: ml.p5.48xlarge 인스턴스의 1/4 GPU 리소스를 단일 프로젝트에 할당
- 추론 워크로드: 다수의 팀이 단일 GPU만 필요한 추론 작업을 개별 인스턴스 단위로 병렬로 실행
- IDE 환경: CPU 기반 인스턴스를 적절히 분할해 JupyterLab 같은 개발 환경 컨테이너 운영
배포 방식 및 자동화
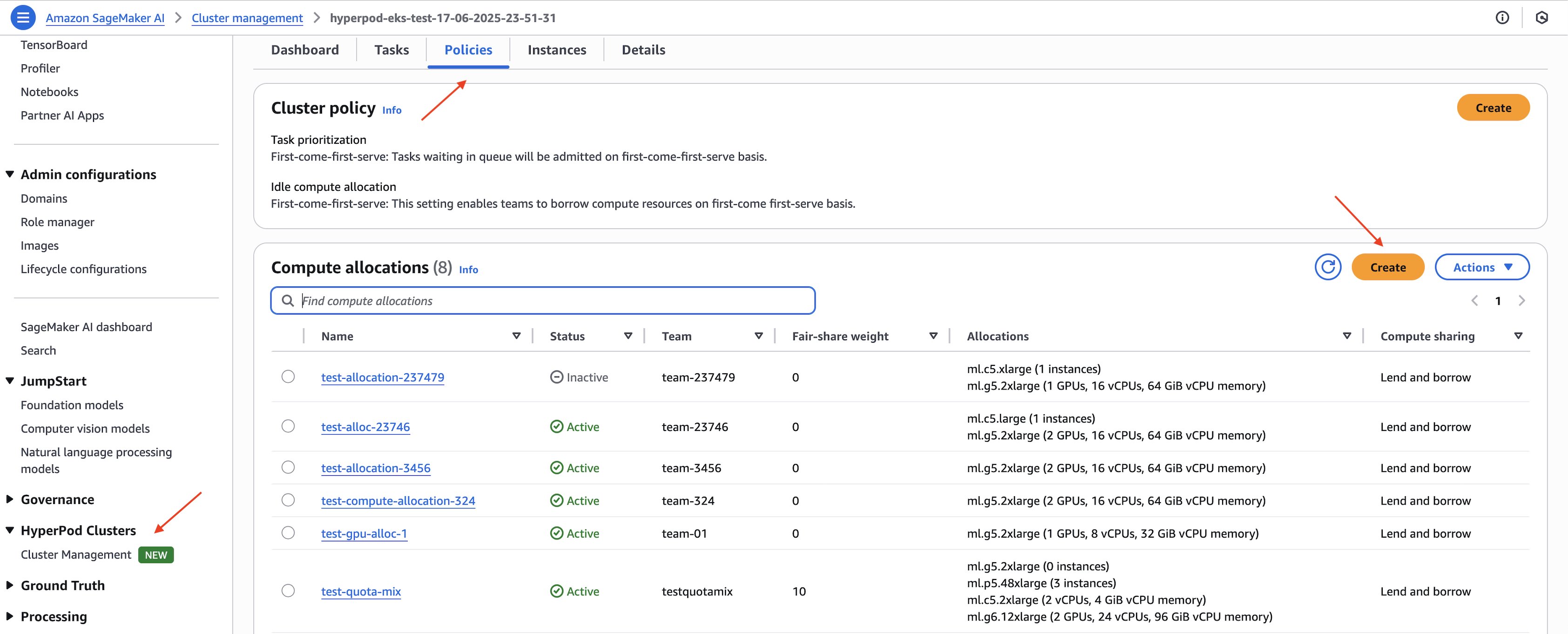
AWS 콘솔에서 컴퓨트 할당을 설정하려면 HyperPod 클러스터 관리 > 정책(Configuration) 탭 > Compute Allocations에서 ‘Create’를 선택하여 할당 수를 정의합니다.
CLI 기반 자동화도 가능합니다. 예를 들어, GPU만 할당하는 CLI 명령은 다음과 같습니다.
aws sagemaker create-compute-quota
–name "only-gpu-quota"
…
–compute-quota-config "ComputeQuotaResources=[{InstanceType=ml.g6.12xlarge,Accelerators=2}]"
또는 다양한 자원 타입을 혼합(mixed types) 할당하는 경우:
aws sagemaker create-compute-quota
–name "mix-quota-type"
…
–compute-quota-config "ComputeQuotaResources=[{Accelerators=2}, {VCpu=2}]" …
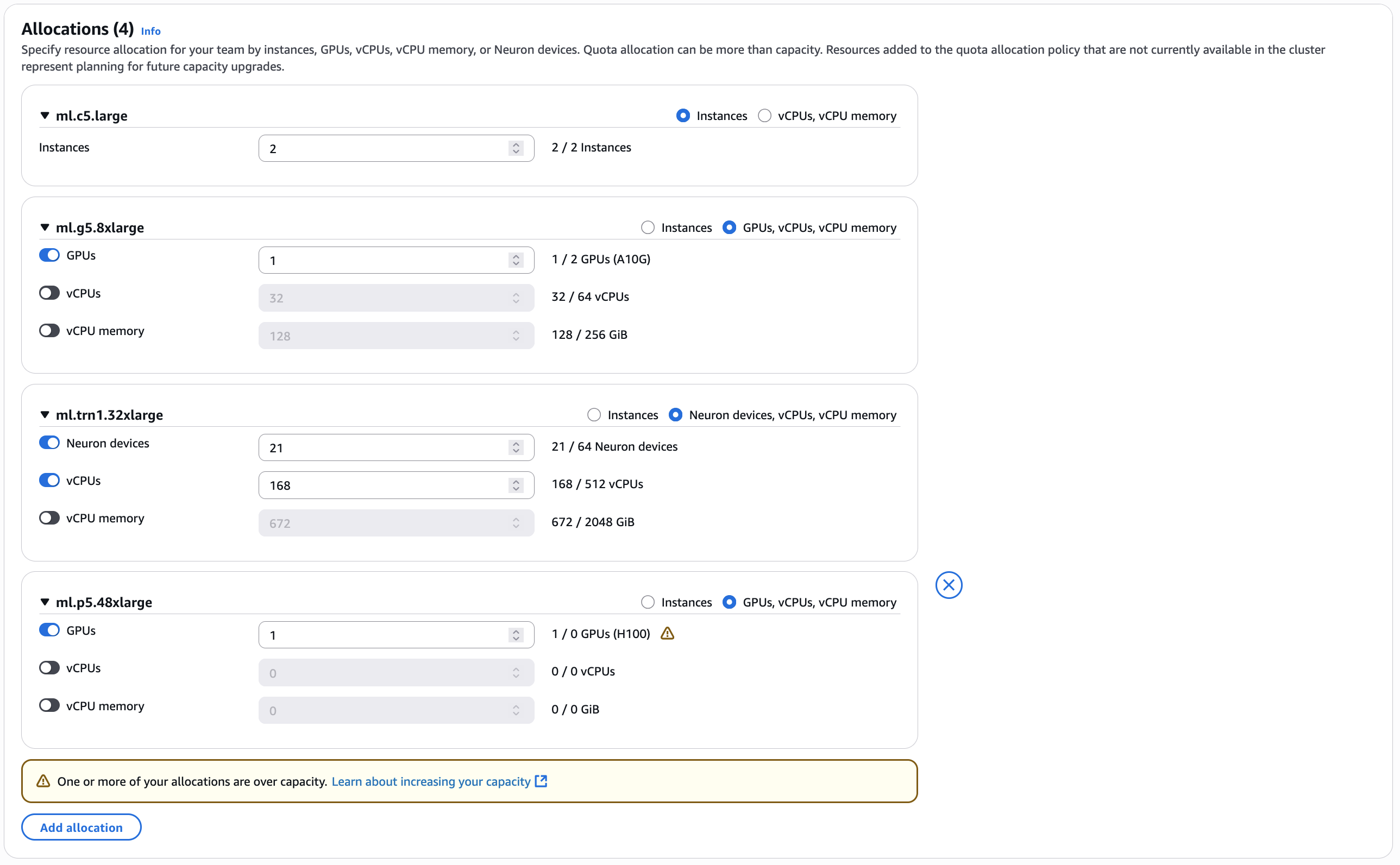
자세한 자동화 명령어는 SageMaker HyperPod CLI와 kubectl 커맨드를 병행 활용할 수 있으며, 작업 제출 시 팀 네임스페이스, 로컬 큐, 우선 순위 클래스, GPU 개수, vCPU, 메모리 사용량 등을 명시하여 워크로드를 정밀하게 컨트롤 할 수 있습니다.
자원 스케줄링 아키텍처
HyperPod Task Governance는 쿠버네티스 기본 스케줄러(kube-scheduler)와 상호 보완적으로 작동하는 Kueue를 기반으로 설계되어, 요청된 자원의 할당 상태와 정책 기반으로 워크로드를 승인(Admission)하고 클러스터 내 최적 위치에 스케줄링합니다.
워크로드가 요청된 자원 요건에 맞으면 ClusterQueue에서 ResourceFlavor를 기준으로 적합한 노드 라벨을 PodSpec에 주입하여 자동 배포합니다.
결론
Amazon SageMaker HyperPod의 세밀한 리소스 할당 기능은 다양한 AI 프로젝트의 니즈를 충족시킬 수 있는 유연하면서도 강력한 솔루션입니다. 단일 GPU 또는 vCPU 수준까지 할당이 가능하고, 정책에 따라 자동 분배되도록 설정할 수 있어 고비용 GPU 자원을 보다 효율적으로 운용할 수 있습니다.
MLOps 자동화 환경 구축, AI 모델 실험, inference workload 운영, IDE 개발환경 배포 등 수많은 AI 시나리오에 적합하게 활용 가능하여 GPU 인프라 예산을 효율화하고 팀 간 자원 공유를 원활하게 만들 수 있습니다.
활용 가이드, 상세한 CLI 사용법, 아키텍처 작동 원리는 다음 원문을 참고해보세요.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
