Amazon Bedrock Knowledge Base를 Terraform으로 손쉽게 구축하는 방법
기업들이 생성형 AI 애플리케이션을 개발할 때 가장 효과적인 접근 방식 중 하나는 바로 RAG(Retrieval-Augmented Generation) 전략입니다. 이 방식은 OpenAI 또는 Titan과 같은 기초 모델(Foundation Model)이 사전에 준비된 정제된 데이터를 외부로부터 검색하고 응답 생성을 보완하는 작업을 포함하며, 훈련이나 파인튜닝 없이도 정확도와 신뢰성을 높일 수 있습니다. 본 포스팅에서는 Terraform 기반으로 Amazon Bedrock Knowledge Base를 자동 배포하고, 추후 운영 가능하도록 설정하는 가이드와 실전 활용 예시를 다루고자 합니다.
Terraform을 통한 자동화 구성 및 주요 구성 요소
이 가이드는 Amazon Bedrock Knowledge Base, OpenSearch Serverless, IAM 권한 구성을 포함하여 AWS의 인프라를 코드 형태로 정의하고 자동으로 배포할 수 있는 Terraform 템플릿을 제공합니다. 이로써 반복 가능한 배포가 가능해지고 수동 설정을 최소화할 수 있습니다.
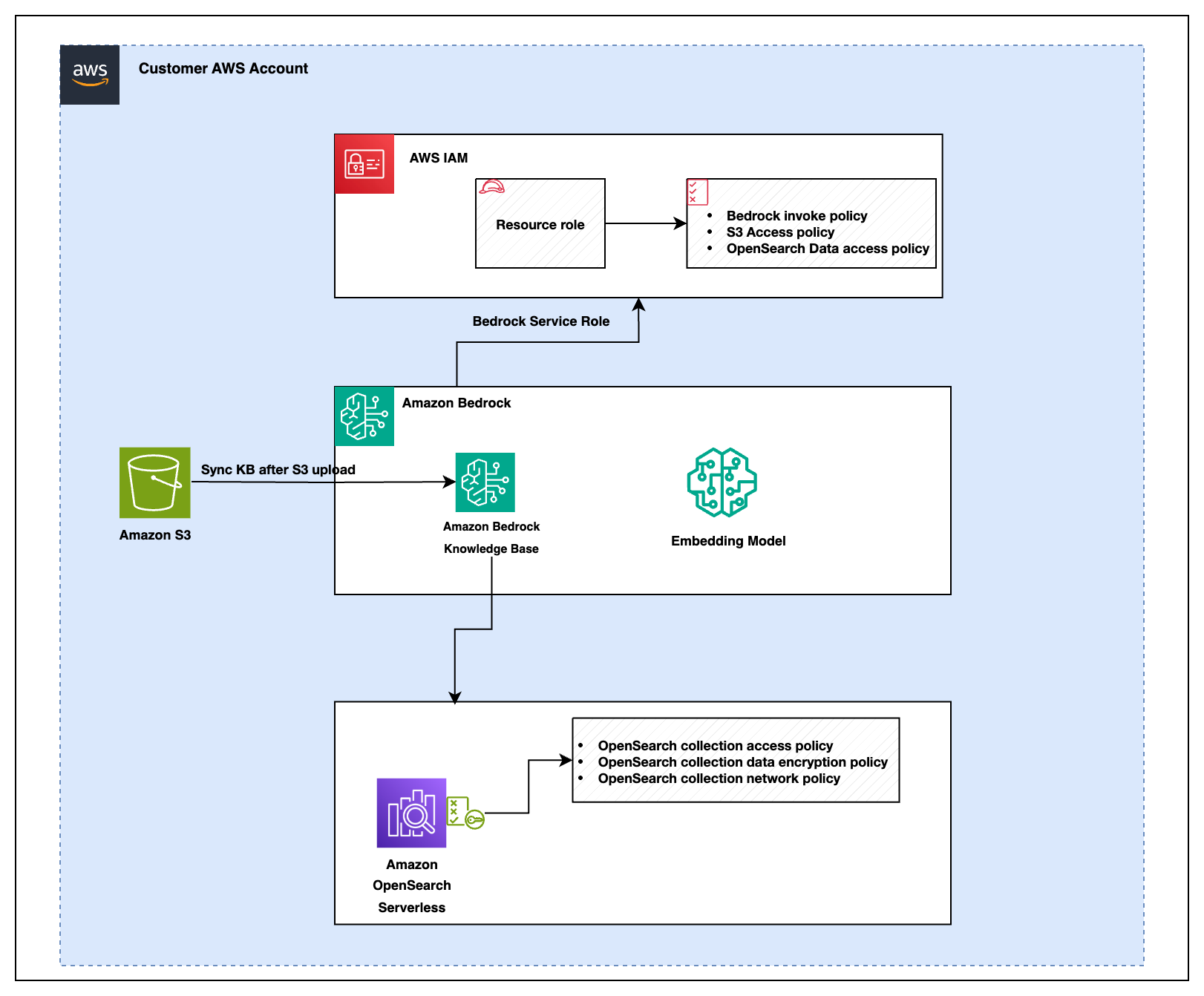
구성 요소 설명:
- IAM Role: Amazon Bedrock, S3, OpenSearch 간의 접근 권한을 제어해 안전하게 리소스를 연결합니다.
- Amazon OpenSearch Serverless: 대규모 데이터셋 검색 및 필터링을 위한 벡터 인덱스 제공.
- Amazon Bedrock Knowledge Base: 생성형 AI 모델에 기반 지식을 공급해 문맥 이해 및 응답의 정확도 증가.
배포 전 사전 준비 사항
Terraform을 사용한 배포를 위해 다음의 사전 조건이 필요합니다:
- 활성화된 AWS 계정과 적절한 IAM 권한
- 설치된 Terraform 및 AWS CLI
- 문서 저장용 S3 버킷 (PDF, TXT, DOCX 등 형식 지원)
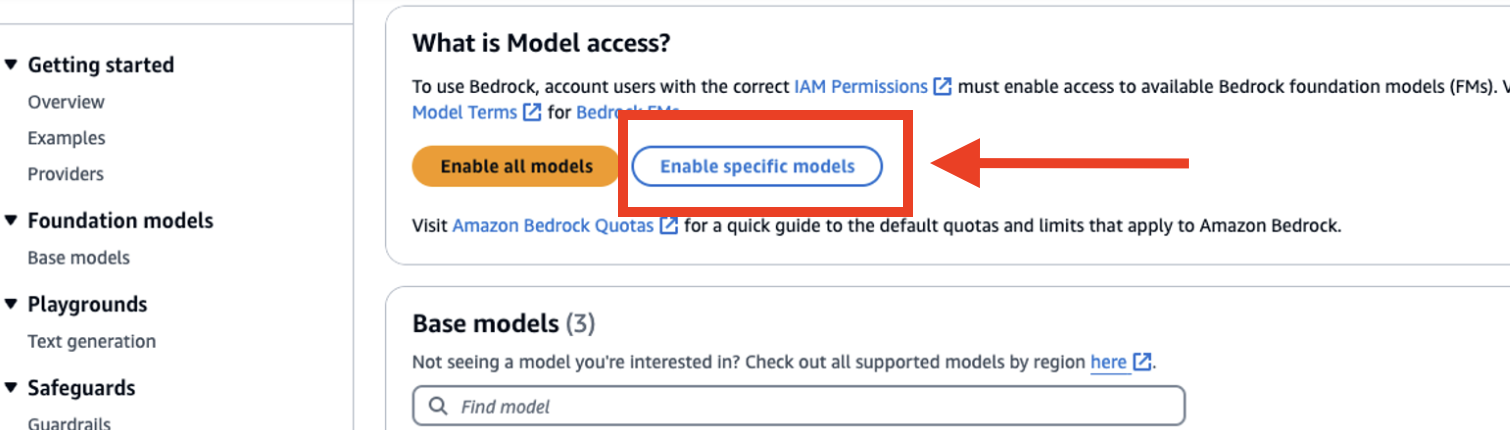
- Titan Text Embeddings V2 모델 사용 권한 등록 (Amazon Bedrock 콘솔에서 활성화 필요)
Terraform 활용 배포 절차
-
GitHub 저장소 클론:
git clone https://github.com/aws-samples/sample-bedrock-knowledge-base-terraform -
위치 이동:
cd sample-bedrock-knowledge-base-terraform -
AWS 리전 설정:
main.tf 파일에서 provider 항목 내 region 값 수정 -
S3 버킷 명 등록:
knowledge_base 모듈 내 kb_s3_bucket_name_prefix 값 설정 -
선택적 환경 설정:
- embedding 모델 ID 지정 (예: amazon.titan-embed-text-v2)
- knowledge base 명칭 설정
- chunking 전략 선택 (FIXED_SIZE, SEMANTIC 등)
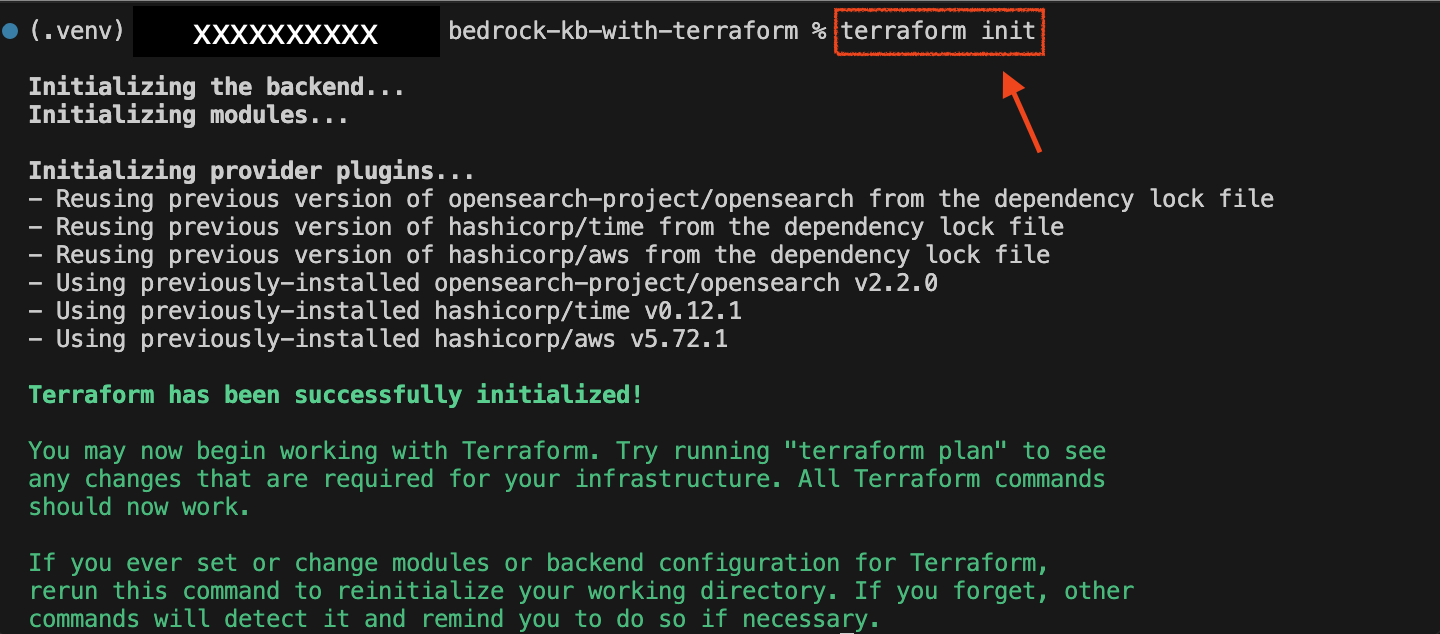
- 인프라 초기화 및 플랜 검토:
terraform init → terraform plan
- 인프라 생성 실행:
terraform apply (적용 승인 후 배포 시작)
고급 설정: Chunking 전략과 벡터 설정
사용 주제에 따라 chunking 전략(FIXED_SIZE, HIERARCHICAL, SEMANTIC)을 선택해 문서 분할 방식과 효율을 조절할 수 있습니다. 예를 들어, FIXED_SIZE는 고정된 길이의 토큰 조각으로 대상을 나누며, SEMANTIC은 의미 기반의 범위를 형성해 더 정교한 검색 환경을 제공합니다.
또한, OpenSearch 벡터 치수를 설정해 검색 일치율을 개선할 수 있습니다. 기본값은 1024이며, 모델 출력 특성과 성능 요구에 따라 사용자가 조정할 수 있습니다.
Knowledge Base 테스트
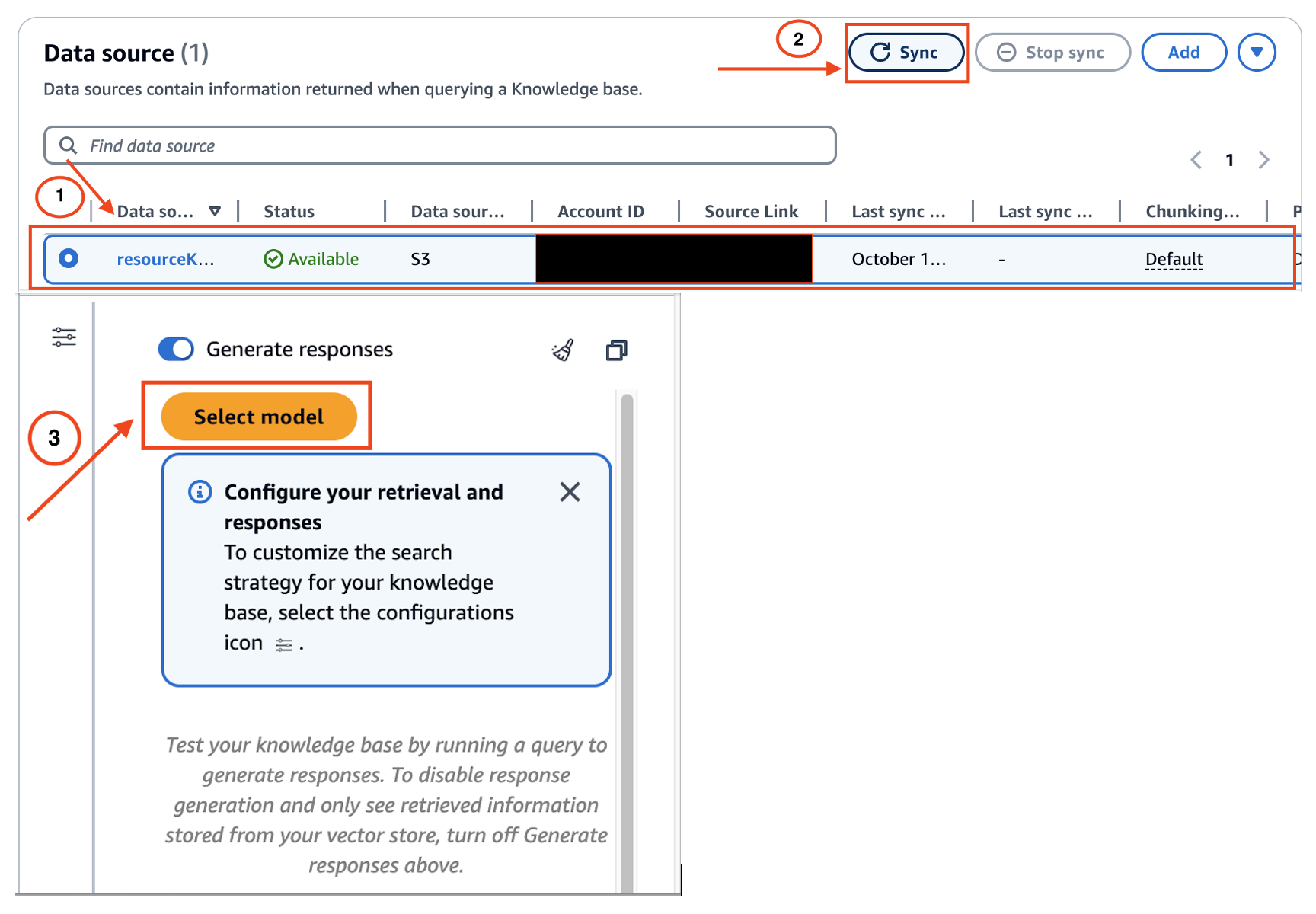
- Bedrock 콘솔 접속 후 Knowledge Bases 탭 선택
- 배포한 knowledge base 선택 및 동기화(Sync)
- 모델 선택 → FM 선택 → Q/A 테스트 진행
테스트가 완료된 후에는 terraform destroy 명령어를 실행해 리소스를 제거하고, S3 버킷 내 데이터도 수동 삭제하여 불필요한 비용 발생을 방지합니다.
활용 및 배포 가이드를 통한 기업 내 도입 추진
이 글에서 다룬 Terraform 배포 가이드는 단순한 테스트 환경을 넘어 기업용 생성형 AI 애플리케이션 구축에 있어 자동화, 유지보수성, 보안성을 동시에 확보할 수 있다는 점에서 매우 유용합니다. Amazon Bedrock Knowledge Base를 통한 RAG 구현은 문맥 기반 검색, 답변 정확도 향상, 클라우드 기반 자동화 인프라 구축에 이상적이며, 향후 다양한 산업군에 걸쳐 활용이 가능할 것입니다.
활용 사례나 실제 적용 경험이 있다면 함께 공유하고, 추가적인 기술적 문의는 아래 연락처를 통해 문의하시기 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
