서버리스 Amazon Bedrock 배치 작업 흐름 구축 가이드: AWS Step Functions로 자동화된 AI 처리 실현하기
기업들이 인공지능 및 머신러닝 기술을 본격적으로 도입함에 따라, 초대규모 데이터를 처리하는 추론(inference) 작업의 효율적인 운영과 자동화는 필수가 되었습니다. 특히 생성형 AI와 같은 구축형 모델(Foundation Model, 이하 FM)의 확산으로 인해, 대규모 배치 추론(batch inference)은 다양한 데이터 활용 및 모델 훈련 등의 활용 사례에서 주요 컴퓨팅 과제로 부상하고 있습니다.
이러한 상황에서 Amazon Bedrock은 실시간 추론과 함께 대용량 비동기 추론(batch inference) 기능을 지원하며, 이는 대용량 데이터를 지연을 감수하면서 처리할 수 있는 시나리오에 적합한 프레임워크입니다. 특히, 비용 효율적인 운영이 가능하며, 온디맨드 방식 대비 최대 50%까지 비용을 절감할 수 있습니다.
이번 글에서는 AWS Step Functions를 활용하여 Amazon Bedrock 기반의 추론 파이프라인을 전자동화하는 방법과 이를 통해 데이터 임베딩(embedding), 평가(eval), 완성(completion)과 같은 대규모 AI 프로세스를 실행하는 배치 오케스트레이션 자동화 흐름을 상세히 소개합니다.
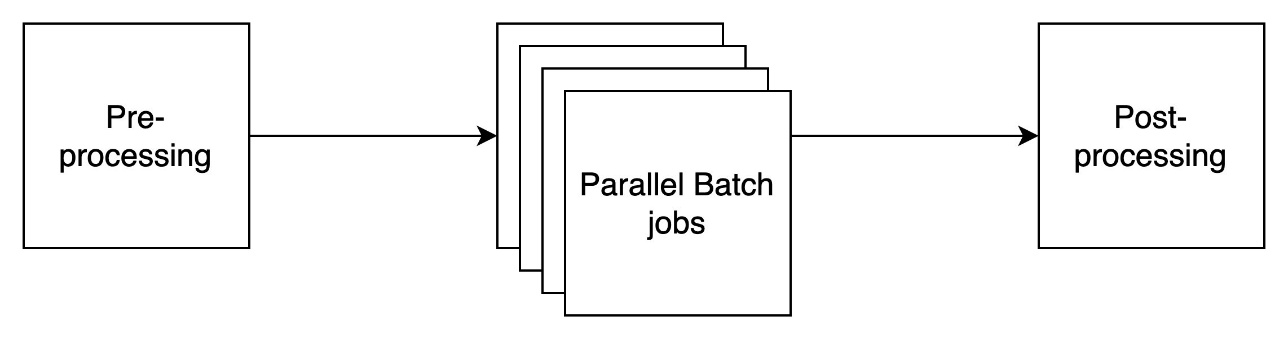
자동화된 배치 추론 파이프라인의 구조
이 배치 처리 자동화 솔루션은 다음의 세 단계를 기반으로 구성됩니다.
- 입력 데이터 전처리: 프롬프트 템플릿에 맞춘 JSONL 포맷화 작업
- 병렬 배치 추론 작업 실행: AWS Bedrock 모델을 통한 텍스트 생성 또는 임베딩
- 후처리: 결과 파싱 및 원본 데이터 대응
Amazon Bedrock 배치 작업은 AWS CDK 스택 위에서 Step Functions 상태 머신을 통해 이루어지며, AWS Lambda, Amazon S3, DynamoDB 등을 조합하여 완전히 서버리스 구성으로 구축됩니다.
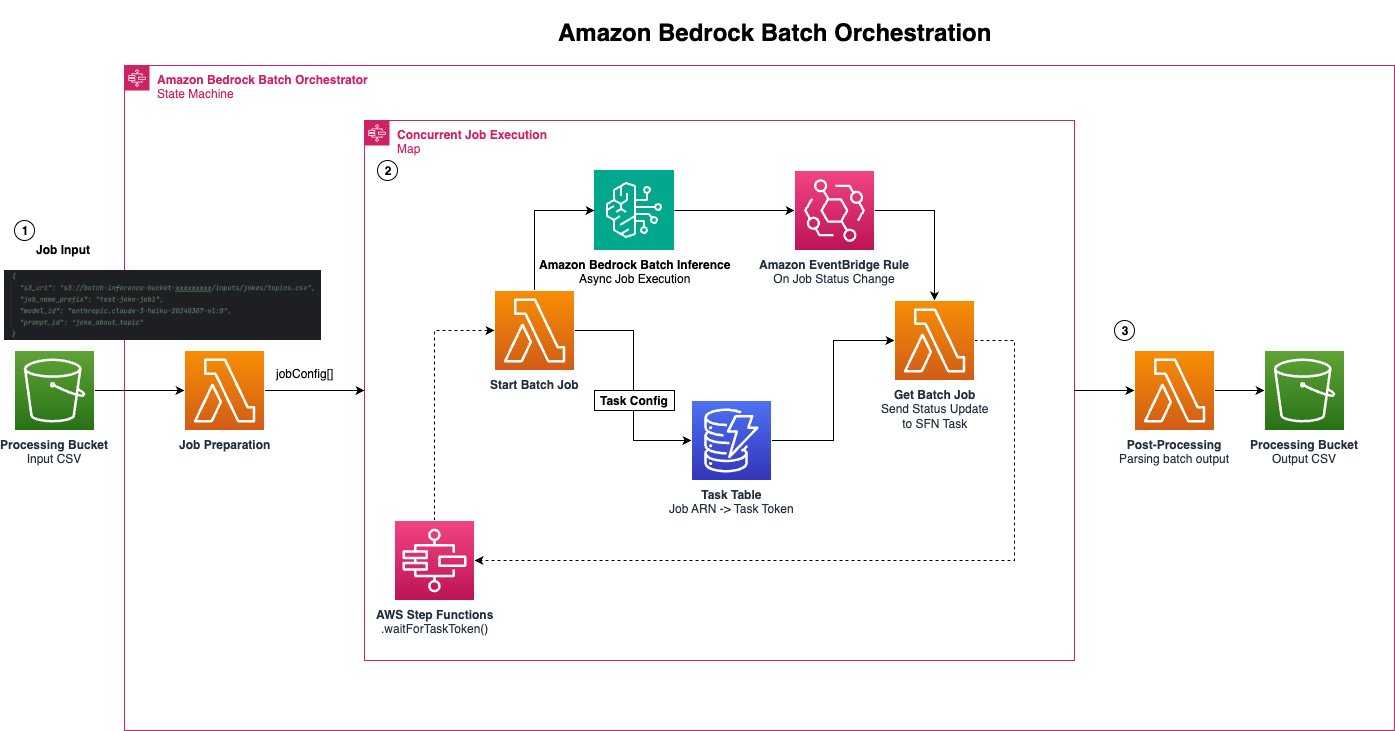
배치 추론을 위한 모델 구성과 활용 사례
이 프레임워크는 Hugging Face의 공개 데이터셋(SimpleCoT)을 사용한 220만 건 이상의 데이터 처리를 포함한 대규모 테스트를 기반으로 하며, 다음과 같은 다양한 활용이 가능합니다.
- 텍스트 임베딩 생성 (예: Titan-Embed Text v2 모델)
- 체인 오브 싱킹 기반 Q&A 자동화
- 논리/수학 기반 문제 해결
- 디스틸(교사-학생 모델 훈련용) 데이터 생성
Amazon S3에 저장된 CSV 또는 Parquet 파일, 혹은 Hugging Face Hub의 데이터셋 ID를 입력 데이터로 사용할 수 있으며, 모델 타입에 따라 프롬프트 템플릿을 적용하거나 생략 가능합니다.
예시: Hugging Face 데이터셋 기반 추론 입력 구조
{
"job_name_prefix": "full-cot-job",
"model_id": "us.anthropic.claude-3-5-haiku-20241022-v1:0",
"prompt_id": "question_answering",
"dataset_id": "w601sxs/simpleCoT",
"split": "train",
"max_records_per_job": 50000
}
입력 데이터 구조 자동 대응 및 병렬 처리
Step Functions에서는 Map 상태를 사용하여 최대 20여 개 작업을 동시에 병렬화하며, 병렬 처리 종료 시 Lambda 기반의 후처리 작업을 실행합니다. 결과는 다시 Amazon S3에 Parquet 포맷으로 저장되며, input 컬럼에 대비되는 response 또는 embedding 컬럼으로 출력됩니다.
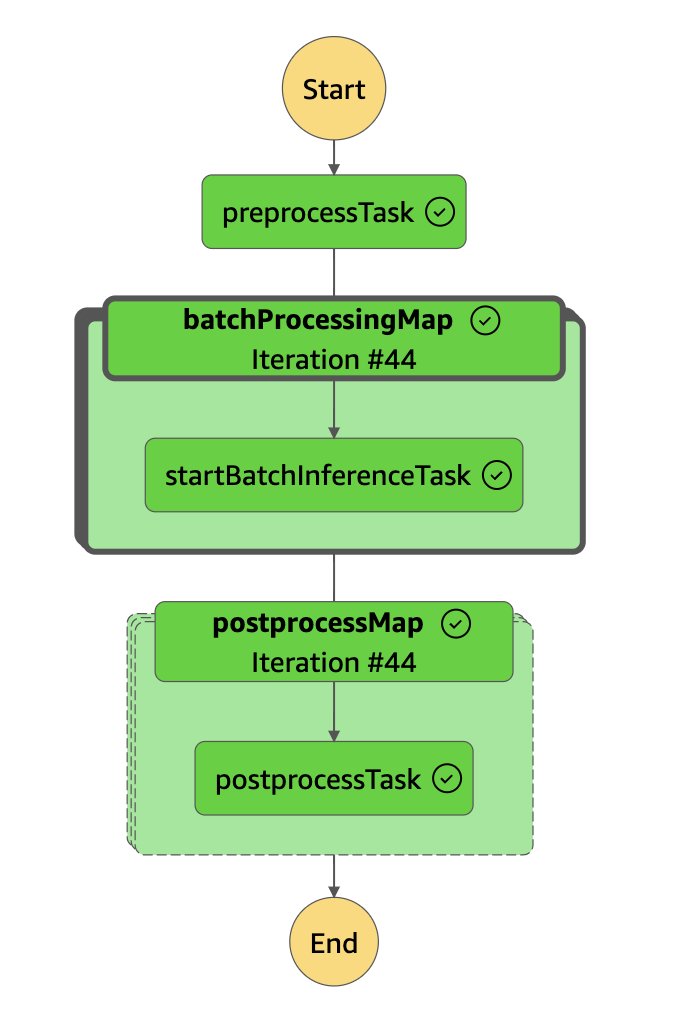

CDK 배포 가이드: 자동화된 순차 배포 지원
해당 파이프라인은 GitHub의 AWS Sample Repo에서 제공되고 있으며, CDK 기반으로 다음과 같이 배포됩니다.
- Node.js 및 AWS CDK 설치
- GitHub Repository 클론
- 필요한 패키지 및 템플릿 구성
npm run cdk deploy명령 실행
배포 완료 후, S3 버킷 이름과 Step Functions 작업 이름이 출력되며 이후 입력 데이터 및 설정값만 수정하면 반복적인 일괄 추론 수행이 가능합니다.
정리 및 활용 팁
이 솔루션은 서버 인프라 없이도 대규모 데이터를 효과적으로 추론 처리할 수 있는 AWS 기반의 유연하고 확장 가능한 자동 배치 오케스트레이션 시스템입니다. 자동화, 활용도, 배포 가이드 면에서도 매우 높은 완성도를 갖추고 있으며, 다음과 같은 분야에 적용할 수 있습니다.
- 생성형 AI 기반 태스크 자동화
- 교육용 모델 디스틸용 데이터셋 생성
- 검색 기반 시스템의 대규모 임베딩 구축 자동화
AWS Bedrock과 Step Functions의 조합을 통해, AI 추론 파이프라인이 더 이상 복잡한 백엔드 작업이 아닌, 구성 가능한 서버리스 워크플로우로 격상되었습니다. 이제 AI 개발자와 데이터 과학자는 모델 개발보다 의미 있는 데이터 처리와 품질 향상에 더욱 집중할 수 있게 되었습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
