아마존 SageMaker HyperPod 레시피를 활용한 GPT-OSS 모델 파인튜닝 및 배포 가이드
소개
대규모 언어모델(LLM)의 활용이 점점 보편화되면서, 기업과 개발자들은 자신만의 목적에 맞게 맞춤형 AI 모델을 구축하고자 하는 수요가 계속해서 증가하고 있습니다. 하지만 이러한 LLM을 파인튜닝하고 배포하기 위해서는 고성능 하드웨어 자원과 복잡한 분산 학습 환경 설정이 필요하기 때문에 진입장벽이 높았습니다. 이에 AWS에서는 SageMaker HyperPod 레시피를 통해 오픈소스 GPT-OSS 모델을 손쉽게 파인튜닝하고 실시간으로 배포까지 할 수 있는 자동화된 프로세스를 소개하였습니다.
이 블로그 글에서는 SageMaker HyperPod 환경에서 GPT-OSS 120B 모델을 다국어 체인 오브 싱킹(CoT) 데이터셋으로 파인튜닝하고, 최종적으로 실시간 추론이 가능한 엔드포인트에 배포하는 전체 과정을 소개합니다. 이 과정은 SageMaker 훈련 잡 또는 HyperPod 클러스터에 따라 자동화 수준에 차이가 있으며, 사용자는 요구사항에 맞는 방식으로 선택할 수 있습니다.
본론
SageMaker HyperPod 레시피 개요
Amazon SageMaker HyperPod는 Slurm 또는 Amazon EKS 기반의 분산 딥러닝 클러스터로, 고성능 GPU 인스턴스를 사용해 대규모 AI 모델 파인튜닝에 적합합니다. HyperPod 레시피는 미리 구성된 실습용 YAML 설정 및 실행 스크립트를 포함하며, Meta의 Llama, Mistral, DeepSeek 등의 공개 LLM 파인튜닝을 몇 분 안에 시작할 수 있도록 도와줍니다.
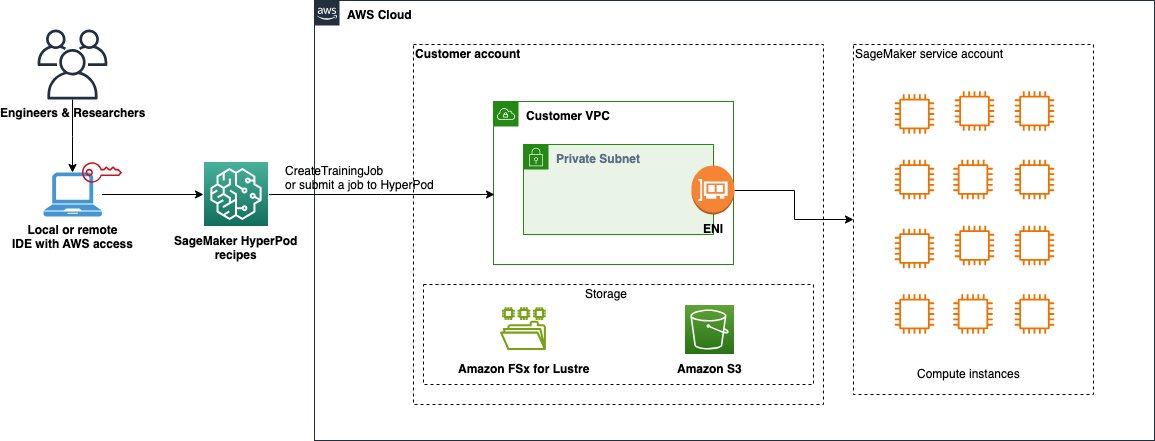
데이터 준비 및 전처리
본 실습에서는 HuggingFace의 "Multilingual-Thinking" 데이터셋을 기준으로, 다양한 언어에 대응하는 논리적 질문과 응답 예제를 활용하여 GPT-OSS 120B를 파인튜닝합니다. 다음 코드를 통해 데이터셋을 로드하고 적절히 토크나이징한 뒤 FSx Lustre 또는 S3로 저장합니다.
토크나이징 후 저장 경로:
- FSx: /fsx/multilingual_4096
- S3: s3://your-bucket/datasets/multilingual_4096/
HyperPod 환경 학습 가이드
HyperPod 기반의 학습을 위해 다음 환경이 요구됩니다:
- Python 3.9 이상
- ml.p5.48xlarge 인스턴스 1개 이상 (8x NVIDIA H100 GPU)
- EKS 클러스터 구성 + FSx Lustre 파일시스템
- SageMaker HyperPod 레시피 클론 및 의존성 패키지 설치
이후 레시피 실행 스크립트를 수정하여 클러스터 유형 및 데이터 경로를 정의하고 실제 학습을 시작합니다.
학습 시작 명령:
chmod +x launcher_scripts/gpt_oss/run_hf_gpt_oss_120b_seq4k_gpu_lora.sh
bash launcher_scripts/gpt_oss/run_hf_gpt_oss_120b_seq4k_gpu_lora.sh
학습이 진행됨에 따라 체크포인트 및 로그는 /fsx/experiment/checkpoints 경로에 저장되며, 학습 완료 후 병합된 최종 모델이 생성됩니다.
SageMaker 훈련 잡을 활용한 대체 접근
HyperPod 클러스터 설정 대신, 단기간의 훈련이 필요한 경우 SageMaker Training Job을 사용할 수 있습니다. 이 방법은 불필요한 인스턴스 낭비 없이 온디맨드 방식으로 처리되었습니다.
SageMaker Python SDK를 활용하여 훈련 잡 생성:
- PyTorch Estimator 클래스 사용
- 훈련 레시피, 학습 데이터, 결과 위치 등 지정 가능
- S3에서 학습 데이터 및 출력 모델 관리
최종 모델은 자동으로 S3에 저장되며, 추가적인 리소스 클린업 없이 깔끔하게 종료됩니다.
실시간 추론을 위한 vLLM 배포
vLLM은 OpenAI GPT API 인터페이스를 그대로 사용할 수 있도록 해주는 고성능 추론 프레임워크입니다. SageMaker 엔드포인트에서 바로 사용 가능하도록 최적화된 컨테이너 이미지를 Docker를 활용해 직접 빌드 및 Amazon ECR에 푸시합니다.
배포 환경에서 요구되는 핵심 환경변수:
- OPTION_MODEL: /opt/ml/model
- OPTION_TENSOR_PARALLEL_SIZE: GPU 수
- OPTION_DTYPE: bfloat16
- OPTION_QUANTIZATION: mxfp4
모델 배포 후, sagemaker.Predictor 클래스를 사용하여 OpenAI 형식의 메시지 입력을 통해 실제 추론을 수행합니다.
실제 추론 예:
payload = {
"messages": [{"role": "user", "content": "안녕하세요, 누구세요?"}],
"parameters": {"max_new_tokens": 64, "temperature": 0.2}
}
output = predictor.predict(payload)
정리
Amazon SageMaker HyperPod 레시피는 대규모 오픈소스 LLM 모델의 파인튜닝 및 실시간 배포를 단순화하면서도 강력한 자동화를 제공합니다. 복잡한 분산 학습 설정을 사전 구성된 레시피 기반으로 빠르게 구축할 수 있으며, 학습 후 vLLM 최적화 컨테이너를 통해 실시간 성능까지 보장합니다.
GPT-OSS 모델을 커스터마이즈하고자 하는 기업이나 연구개발 조직에 SageMaker HyperPod는 시간과 비용 절감 측면에서 매우 효율적인 대안이 될 수 있습니다. 특히 고성능 추론이 필요한 AI 응용 서비스에서는 이와 같은 배포 자동화 워크플로우가 큰 경쟁력을 제공합니다.
GPT-OSS, HyperPod, vLLM 구성 요소 간의 연계 방식을 이해하고자 한다면 본 게시글의 워크플로우를 따라해 보시길 추천드립니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
