세일즈포스 AI 모델 엔드포인트를 위한 Amazon SageMaker AI Inference Components 활용 가이드
오늘날 기업들은 강력한 인공지능 모델을 효율적으로 배포하고 서비스하기 위해 GPU 활용 최적화는 물론, 인프라 비용 효율화라는 과제를 안고 있습니다. 이러한 맥락에서 Salesforce는 Amazon SageMaker AI Inference Components를 활용하여 고유 모델 운영의 효율성과 성능을 대폭 개선하고 있습니다. SageMaker Inference Components는 특히 대형 언어 모델(LLM)과 같은 고부하 모델 운영을 위한 GPU 자원 최적화 도구로, AI 인프라 구축과 운영에 있어 새로운 전환점을 제공합니다.
도입 배경: AI 모델 배포의 현실적인 과제
Salesforce AI Platform 팀은 다양한 크기의 자체 개발 모델을 운영 중이며, 대표적으로 CodeGen, XGen 등이 있습니다. 이들 모델은 수 GB에서 30 GB까지 다양하며, 소비 트래픽과 성능 요구사항도 매우 이질적입니다. 예를 들어, 20~30GB에 이르는 대형 모델은 낮은 트래픽으로 인해 고성능 GPU 리소스가 과도하게 남는 반면, 15GB 내외의 중형 모델은 높은 트래픽을 처리하기 위해 과도한 오버 프로비저닝 상태로 운영되고 있었습니다.
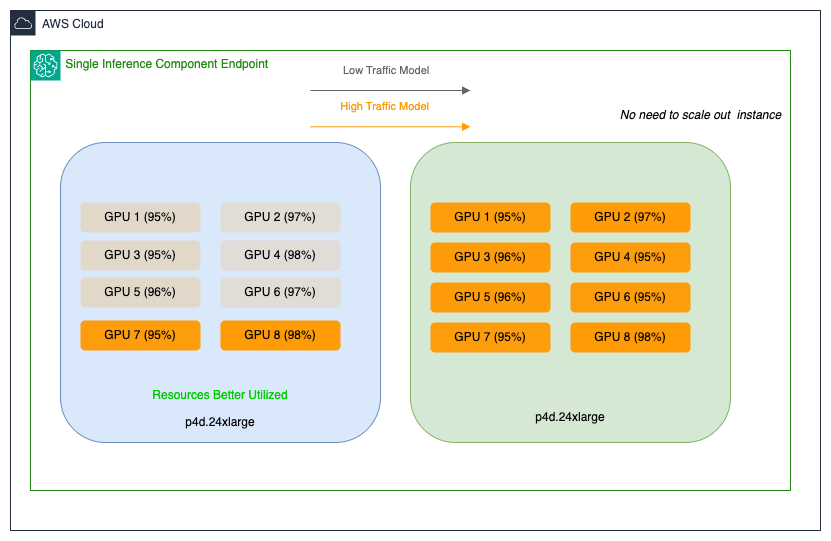
이러한 인프라 자원의 비효율적인 구성은 운영 비용 증가와 리소스 낭비로 이어졌으며, 이를 해결하기 위해 Salesforce는 SageMaker Inference Components를 도입했습니다.
해결 방안: SageMaker Inference Components의 활용 및 구성 방법
Amazon SageMaker AI Inference Components를 통해, 여러 개의 프라이빗 모델(FM)을 단일 엔드포인트에 배포하고 각 모델에 대해 필요한 GPU, 메모리, 컨테이너 이미지를 세밀하게 설정할 수 있습니다. 이를 통해 모델별 자원 할당 및 스케일링 정책을 유연하게 적용할 수 있으며, 트래픽 증감에 따라 엔드포인트가 동적으로 스케일됩니다.
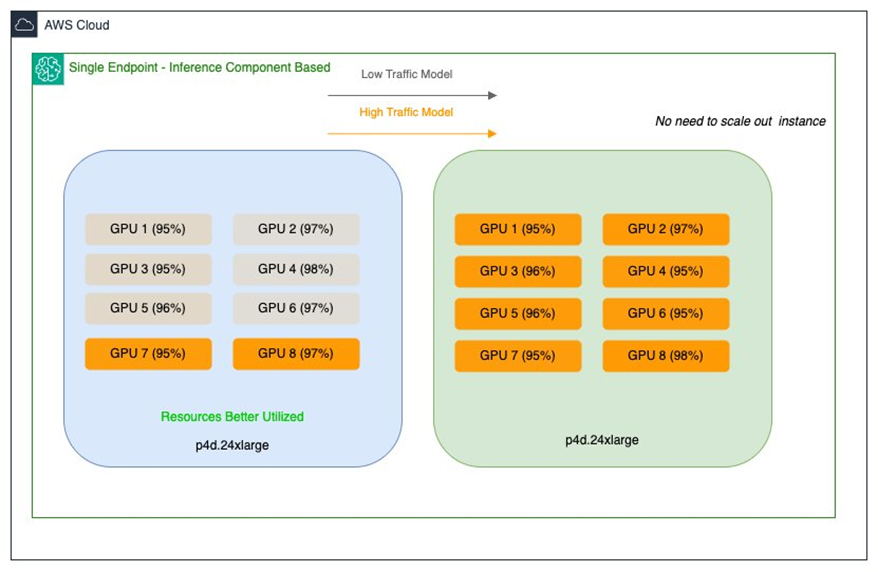
Salesforce는 이 기능을 통해 기존의 단일 모델 엔드포인트(SME)를 보완하는 하이브리드 설계를 구성했습니다. 중요 업무에 대해서는 SME를 유지하고, 가변적이거나 비중요한 모델에 대해서는 Inference Components를 활용하는 방식입니다.
실제 활용 사례: Salesforce에서의 모델 배포와 자동 스케일링
Salesforce의 CodeGen 모델군은 Inline, BlockGen, FlowGPT로 구성되며, ApexGuru 도구 내에서 사용됩니다. 코드 자동완성과 코드블록 생성 기능을 위해 높은 처리 속도와 GPU 효율이 중요했습니다.
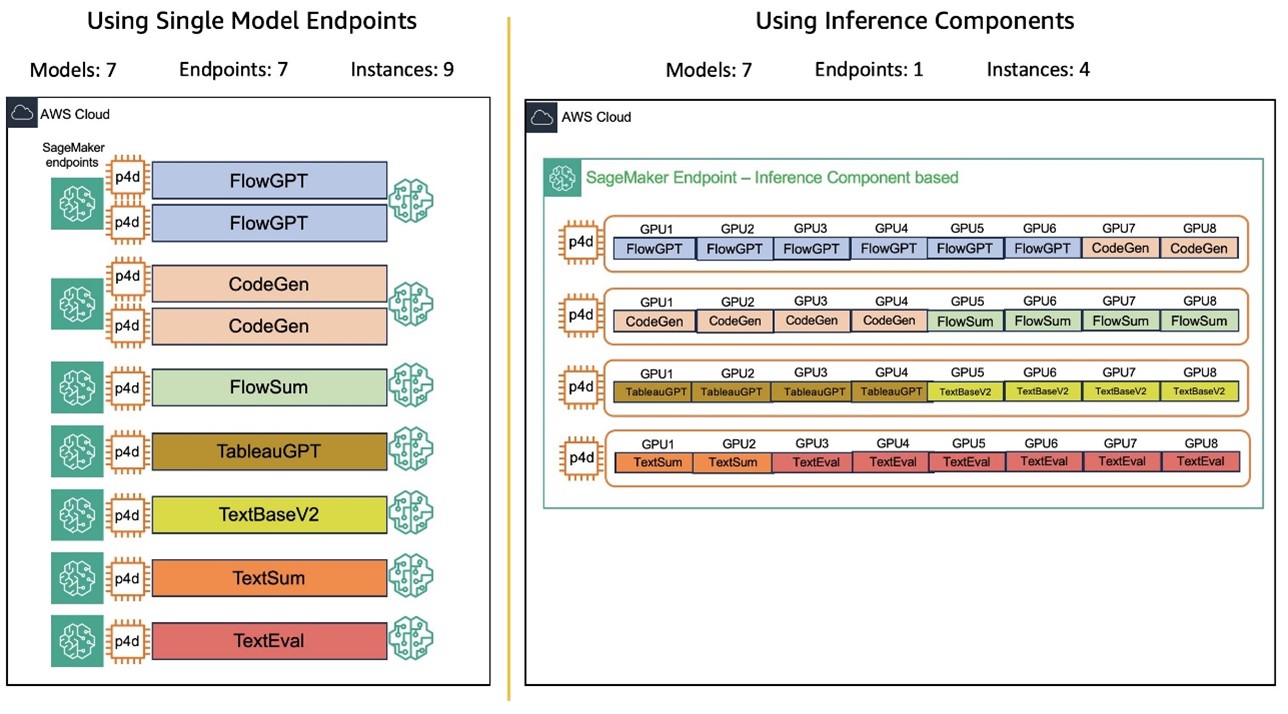
Inference Components는 이러한 각각의 모델에 맞추어 특정 GPU 수, 메모리 크기, 모델 복제 수, 컨테이너 이미지 등을 지정하여 배포할 수 있도록 합니다. 특히 Traffic 기반 Auto Scaling 설정을 통해, 트래픽이 많은 시간에는 GPU 자원을 자동으로 증설하고, 비활성화된 모델은 자원을 회수하여 효율적으로 운영할 수 있습니다. 나아가, 가장 중요한 모델은 항상 메모리에 상주하도록 설정해 안정적인 성능을 유지할 수 있습니다.
활용의 장점 요약
- 활용도 최적화 – 여러 모델을 단일 인프라에서 정밀하게 배치 및 공유함으로써 GPU 당 최대 활용 가능
- 비용 절감 – 고성능 인스턴스 사용에도 불구하고, 비가동 리소스 최소화로 인프라 운영비 대폭 절감
- 성능 향상 – 중소형 모델 또한 고성능 GPU에서 저지연, 고처리량의 인퍼런스 가능
- 자동화와 유연성 – 모델별 별도 스케일링 정책 적용 가능하며, 인스턴스 자동 증감 및 롤링 업데이트 지원
결론
Salesforce는 Amazon SageMaker AI Inference Components를 통해, 운영의 자동화, 멀티 모델 구성 및 리소스 활용 최적화를 성공적으로 이뤄냄으로써 최대 8배의 AI 운영비 절감이라는 인상적인 성과를 거두었습니다. 이 기술적 선택은 단순한 비용 절감을 넘어서, 앞으로의 AI 확장성과 안정적인 고성능 인프라 기반 구축에 있어 핵심적인 전략이 되었습니다.
추후 Salesforce는 Amazon SageMaker의 롤링 업데이트 기능을 도입해, 트래픽 영향 없이 모델 배포를 더 유연하게 전환할 수 있을 예정이며, 이는 엔터프라이즈 AI 도입 및 자동화된 딥러닝 모델 배포 전환에 있어 모범 사례가 될 것으로 기대됩니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
