아마존 SageMaker HyperPod와 P6e-GB200 UltraServer: 초거대 AI 모델을 위한 새로운 기준
서론
현대 인공지능 시대에서는 초거대 AI 모델의 훈련과 배포가 핵심 화두로 떠오르고 있습니다. 특히 수조 개의 파라미터를 갖는 생성형 언어 모델은 막대한 컴퓨팅 파워와 안정적인 네트워크, 고성능 스토리지를 필요로 하며, 이를 위한 통합적인 플랫폼이 절실한 시점입니다.
이러한 요구를 충족하기 위해 AWS는 Amazon SageMaker HyperPod에 P6e-GB200 UltraServer를 지원함으로써 AI 모델 학습과 배포의 자동화, 유연한 활용, 그리고 획기적인 성능 향상을 동시에 이루는 플랫폼을 공개했습니다. 이 글에서는 UltraServer의 구조, 주요 장점, 활용 사례, 배포 가이드 및 비교 포인트까지 상세하게 설명드립니다.
본론
- P6e-GB200 UltraServer와 SageMaker HyperPod 개요
HyperPod는 대규모 분산 학습을 위한 자동화된 플랫폼이며, 이번에 새롭게 통합된 P6e-GB200 UltraServer는 72개의 NVIDIA Blackwell GPU와 Grace CPU를 한 곳에 연결한 고성능 클러스터입니다. 새로운 인프라 구성은 최대 360 PFLOPs의 FP8 성능과 1.4 ExaFLOPs의 FP4 연산 능력을 통해 수조 파라미터 모델 훈련을 실현합니다.
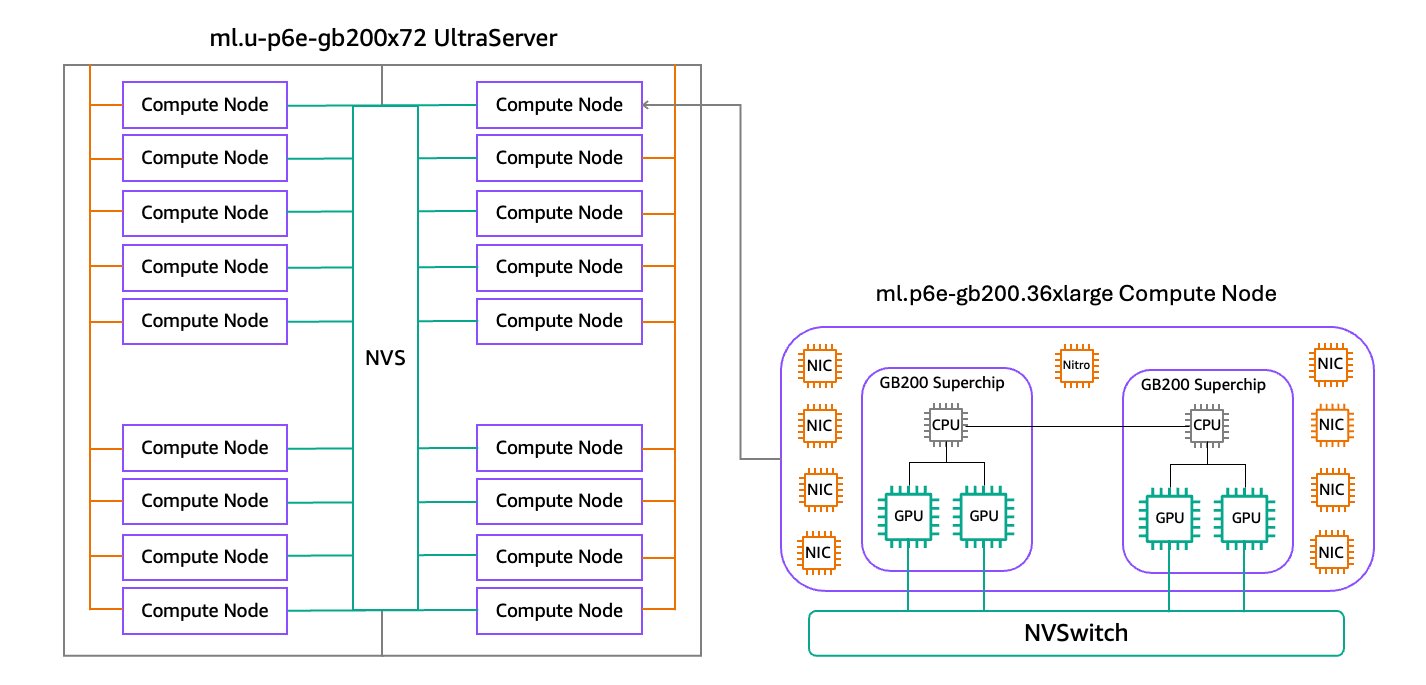
- 기술 사양의 하이라이트
- GPU 연산 성능: 단일 시스템에 72개의 NVIDIA Blackwell GPU가 배치되어 360 PFLOPs의 밀집 FP8 연산 처리 가능
- 고대역폭 메모리: 13.4TB의 HBM3e 메모리를 통해 각 노드 간 메모리 병목 없이 초고속 데이터 이동 가능
- 초고속 네트워킹: 130TBps의 NVLink Bandwidth 및 EFA v4를 통한 28.8Tbps의 전송속도 제공
- 스토리지 최적화: 405TB의 로컬 NVMe SSD와 FSx for Lustre를 통한 GDS 기반 데이터 고속 접근 지원
-
최적화된 학습 구조 및 자동화
Amazon EC2에서 노드 간 위치 정보(Topology)를 활용하여 분산 학습 시 효율적인 데이터 배치를 자동화합니다. Kubernetes 혹은 Slurm 오케스트레이션과 연동되며, SageMaker HyperPod가 노드 라벨, 네트워크 계층, 가용 영역 등을 기반으로 지능형 스케줄링을 가능하게 합니다. -
UltraServer 사용 사례
- 초거대 LLM 및 MoE 모델 훈련: 수조 파라미터 모델을 높은 병렬성과 빠른 커뮤니케이션을 통해 학습
- 실시간 생성형 AI 추론: NVIDIA Dynamo와의 조합으로 기존 대비 최대 30배 빠른 응답성 확보
- 다중 팀 분산 작업 환경: 하나의 UltraServer 인프라에서 수많은 프로젝트를 동시에 실행 가능하여 자원 활용률과 비용 효율성 극대화
- 유연한 배포 가이드
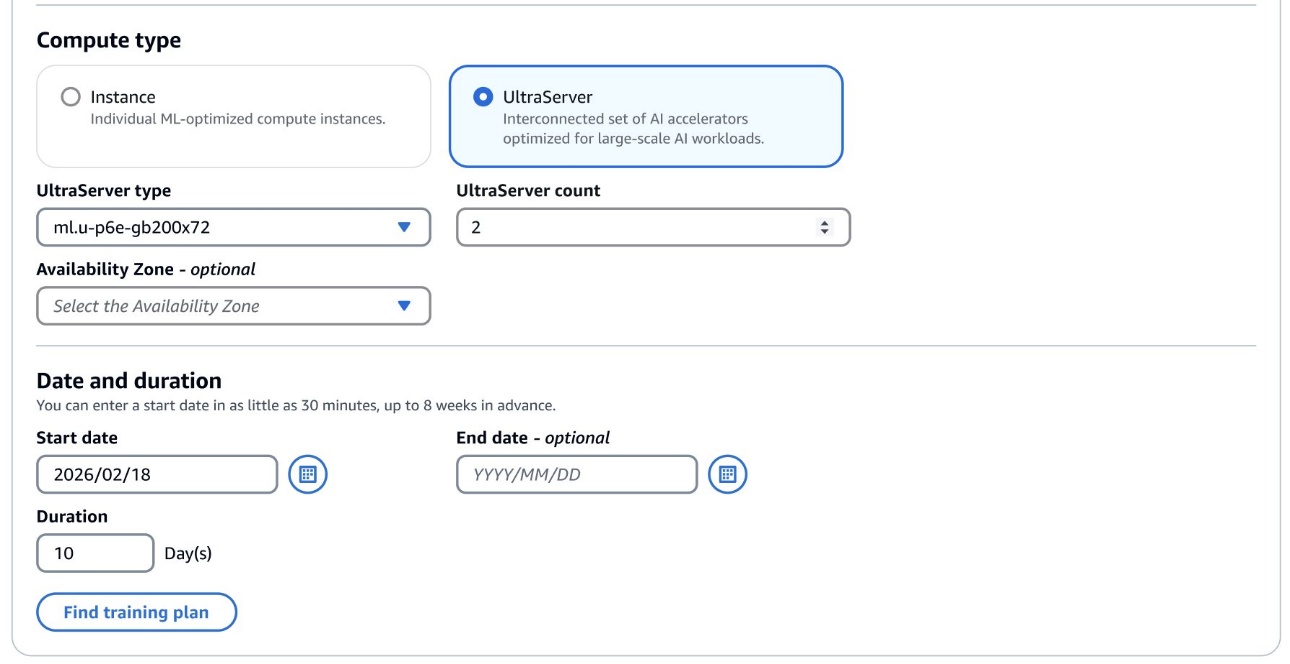
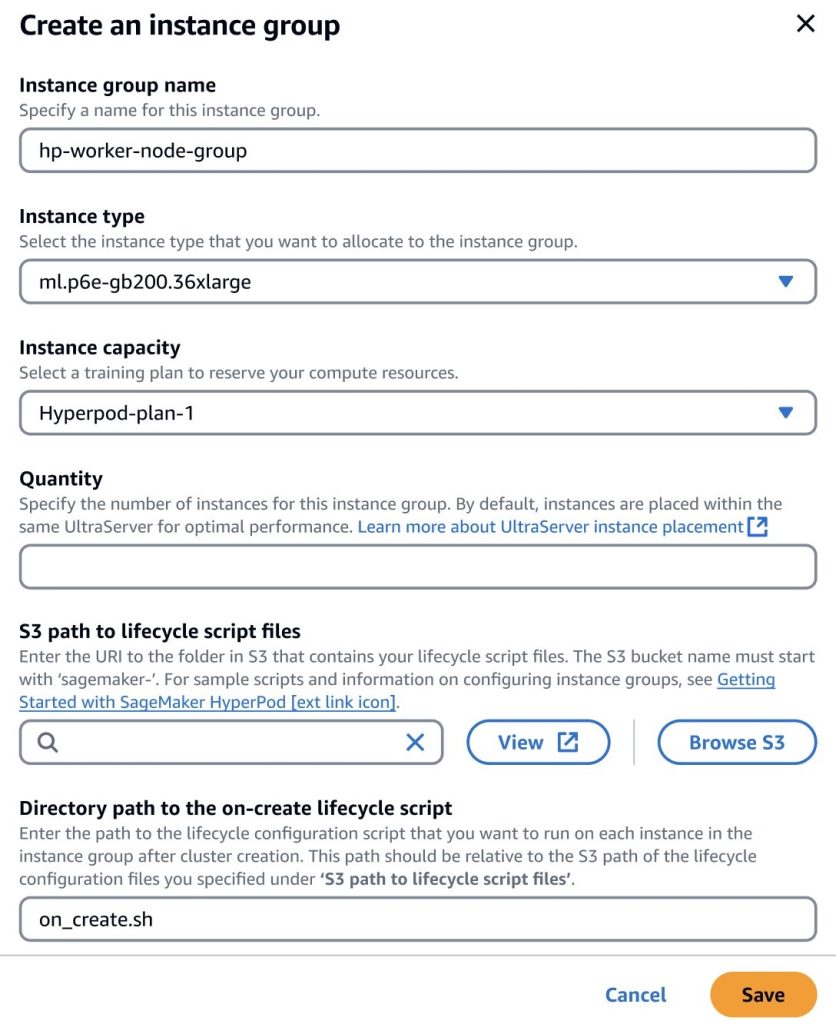
SageMaker HyperPod는 ml.p6e-gb200.36xlarge 인스턴스를 기반으로 구성되며, 학습 플랜 선택을 통해 UltraServer 용량을 사전 예약 가능하고, 장애에 대비해 여유 노드를 구성할 수 있습니다.
예시로 ml.u-p6e-gb200x36의 경우 9개 노드, ml.u-p6e-gb200x72는 18개의 노드로 구성됩니다.
결론
P6e-GB200 UltraServer와 SageMaker HyperPod의 결합은 AI 모델 개발의 모든 단계에서 속도, 확장성, 안정성을 혁신적으로 끌어올립니다. 자동화된 배포 플랫폼, 초고속 연산 및 데이터 이동 환경, 뛰어난 리소스 활용은 AI 산업 전반에서 고성능 학습 워크로드를 소화할 수 있는 새로운 표준이 됩니다. 지금이 바로 수조 파라미터 규모의 AI 활용 환경으로의 도입을 가속화할 장면입니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
