추천 시스템 콜드스타트 문제, AWS Trainium과 vLLM으로 해결하기
인공지능 기반 추천 시스템을 도입한 많은 기업들이 공통적으로 부딪히는 숙제가 있습니다. 바로 '콜드스타트(cold-start) 문제'입니다. 신규 사용자 또는 신규 콘텐츠에 대한 정보가 없어 개인화된 추천이 어려운 상황을 뜻합니다. 이 문제는 사용자 이탈, 클릭률 저하, 전환율 감소로 이어져 비즈니스 성과에 직결됩니다.
기존에는 협업 필터링이나 아이템 인기순 추천 같은 기초적인 대응이 일반적이었지만, 최근에는 대규모 언어 모델(LLM)을 활용해 문제 해결이 가능해졌습니다. 본 포스팅에서는 AWS Trainium, Neuron SDK, 그리고 vLLM을 활용해 콜드스타트 상황에서도 높은 품질의 추천 결과를 얻는 자동화된 배포 가이드를 소개합니다.
콜드스타트 추천 시스템의 새로운 접근 방법
기존 사용자 행동 데이터가 없는 상황에서도 LLM의 제로샷 추론 능력을 이용해 관심사 프로파일을 생성하고, 이를 바탕으로 유사 아이템을 추천할 수 있습니다. 이를 위해 vLLM을 활용해 구조화된 프롬프트로부터 사용자 관심사를 확장하고, 이 확장된 관심 주제를 벡터로 인코딩한 후 FAISS를 이용해 관련 콘텐츠를 유사도 기준으로 추천합니다.
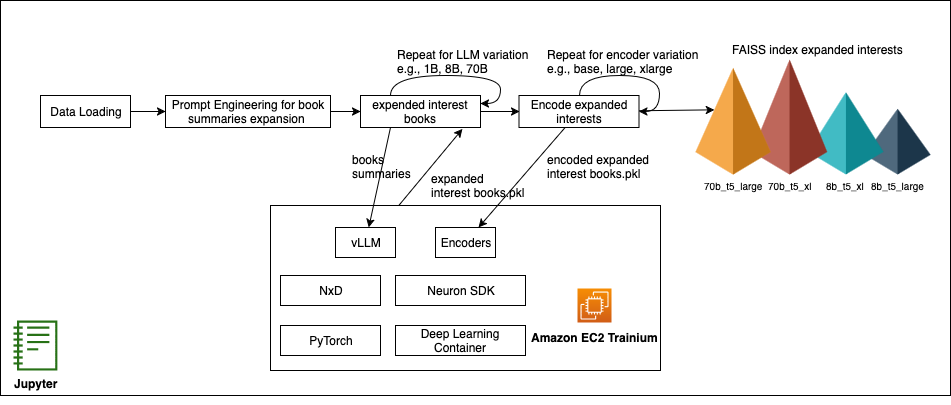
이 과정은 Jupyter Notebook 상에서 실행되며, 데이터 로딩부터 추천 결과 시각화까지 자동화된 워크플로우를 구성합니다. 모델 서빙은 AWS Inferentia 또는 Trainium 기반 인프라에서 동작하며 컨테이너 배포는 AWS EKS를 통해 이루어집니다. 이를 통해 스케일 아웃, 자동 확장, 비용 최적화를 동시에 달성할 수 있습니다.
관심사 확장: 구조화된 프롬프트 기반 vLLM 활용
아마존 도서 리뷰 데이터셋을 기반으로 초기 피드백이 적은 신규 사용자에 대해 관심사 확장을 수행합니다. 예를 들어, 한 명의 사용자가 공상과학 소설 한 권만 리뷰한 경우, vLLM은 "우주 정치, 사이버펑크 디스토피아, 은하계 탐험" 과 같은 키워드를 생성해 관련 추천 지표로 활용합니다.
아래는 실제 사용된 프롬프트 예시 형식입니다:
"The user has shown interest in: {user_review_category}.\nSuggest 3–5 related book topics they might enjoy.\nRespond with a JSON list of topic keywords."
이렇게 생성된 토픽 리스트는 LLM 출력을 정형 데이터 형식으로 제한해 일관된 통제하에 추천 정확도를 높일 수 있습니다. 다양한 LLM—예: Llama 1B, 3B, 8B, 70B 등—과의 조합을 테스트해 가장 적합한 모델을 식별할 수 있습니다.
인코딩 및 유사 콘텐츠 검색: T5 인코더와 FAISS 활용
사용자 관심사와 아이템(도서) 내용을 동일한 공간에 임베딩한 뒤 FAISS를 통해 가장 유사한 콘텐츠를 검색합니다. 인코더로는 Google T5 base, large, XL을 활용하고, 각 집합은 임베딩 벡터화 후 정규화되어 고속 검색 인덱스로 구축됩니다.
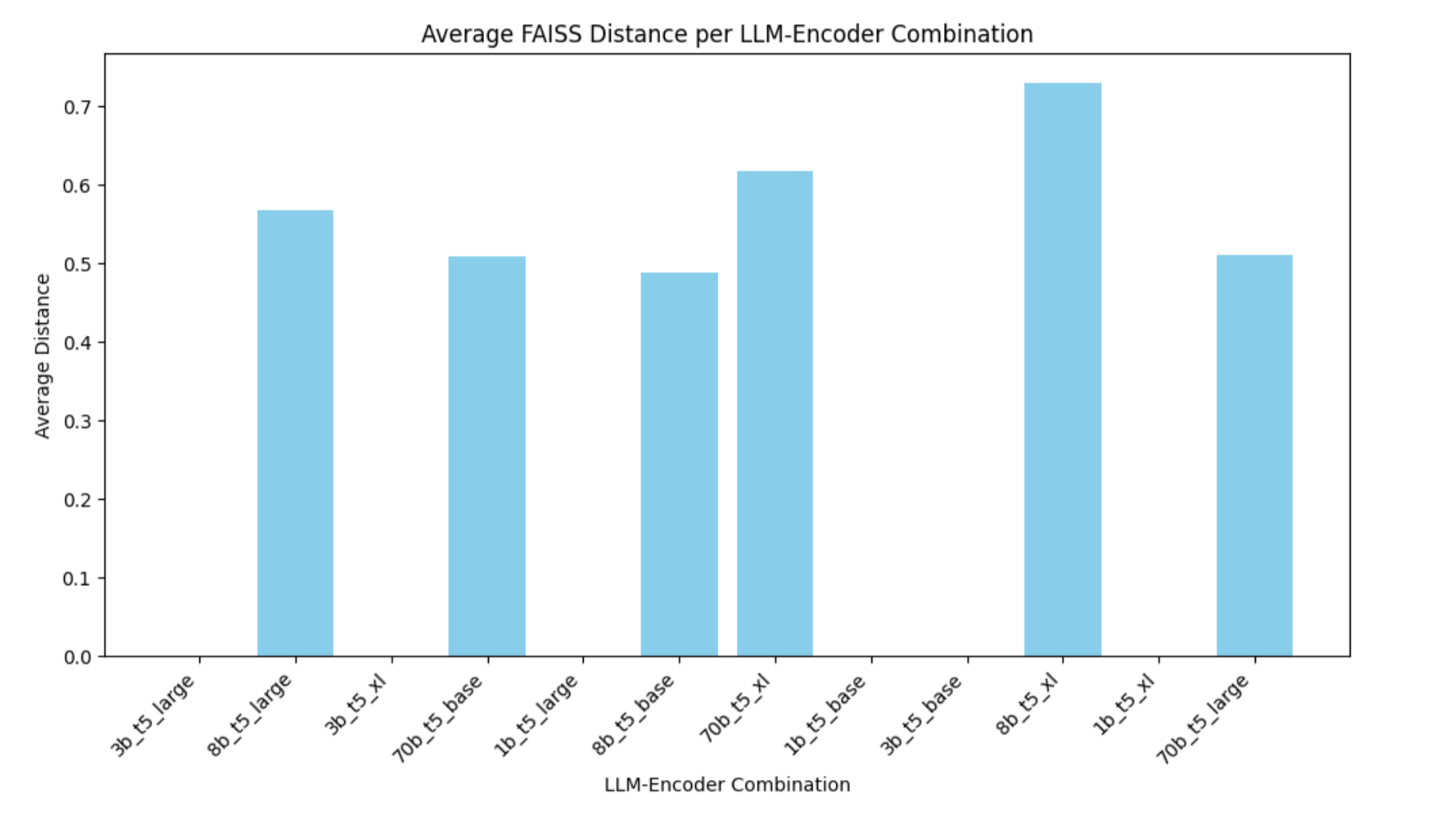
실험 결과, Llama 8B와 T5-large 조합이 가장 높은 토픽 다양성과 추천 품질을 제공하며, 70B 모델은 리소스 비용을 고려할 때 효율 면에서 제한적 이점을 가집니다.
추천 시스템 향상 평가 및 비교: 일관성과 다양성의 균형
추천 시스템이 제공하는 결과가 얼마나 '다양하면서도 일관성 있게' 반응하는지 확인하기 위해, 모델 조합 간 추천 결과의 중복도(Overlap)를 측정합니다. 다음과 같은 히트맵을 통해 모델-인코더 조합별로 기존 추천과의 겹침 정도를 시각화하였으며, 이는 새로운 콘텐츠와의 노출을 조절하는 데 유용합니다.
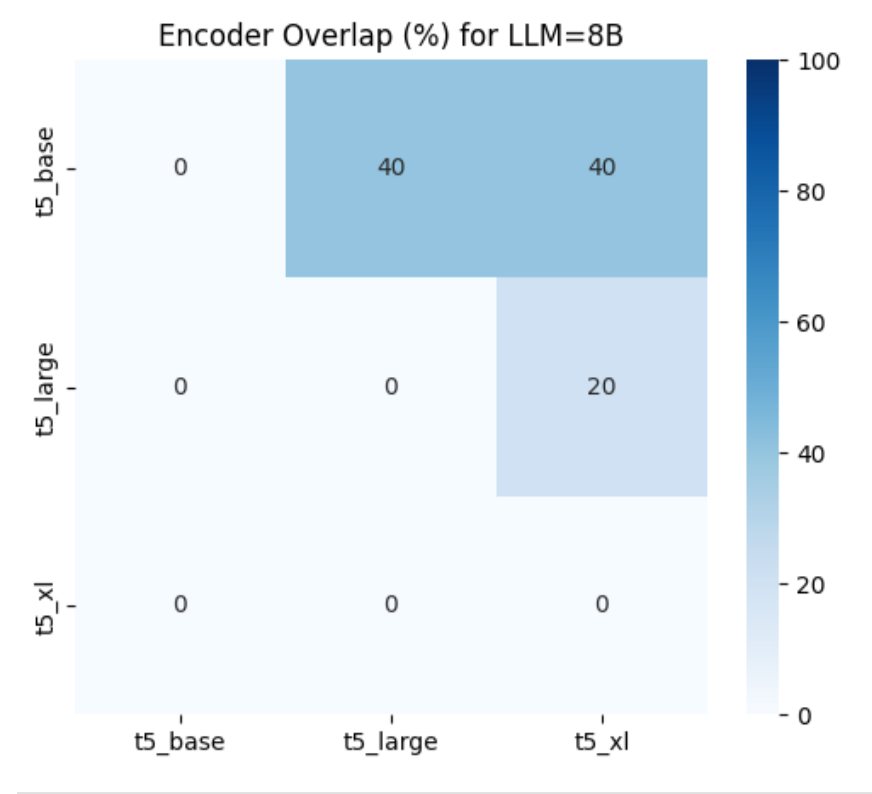
예를 들어, Llama 8B 모델에서 t5-base와 t5-large는 약 40%의 추천 결과가 겹치며, t5-large와 t5-xl 사이에는 더 많은 다양성이 존재합니다.
배포 최적화: Tensor Parallel Size 조정
성능을 높이면서 비용을 줄이기 위해 Neuron에서 제공하는 병렬 처리 크기 설정인 tensor_parallel_size 를 조정합니다. 여러 실험 결과 TP=16일 때 가장 높은 효율성을 제공함을 확인했습니다. 이후 병렬도 증가에 따른 성능 향상은 제한적인 반면, 비용은 가파르게 상승하는 구조입니다.
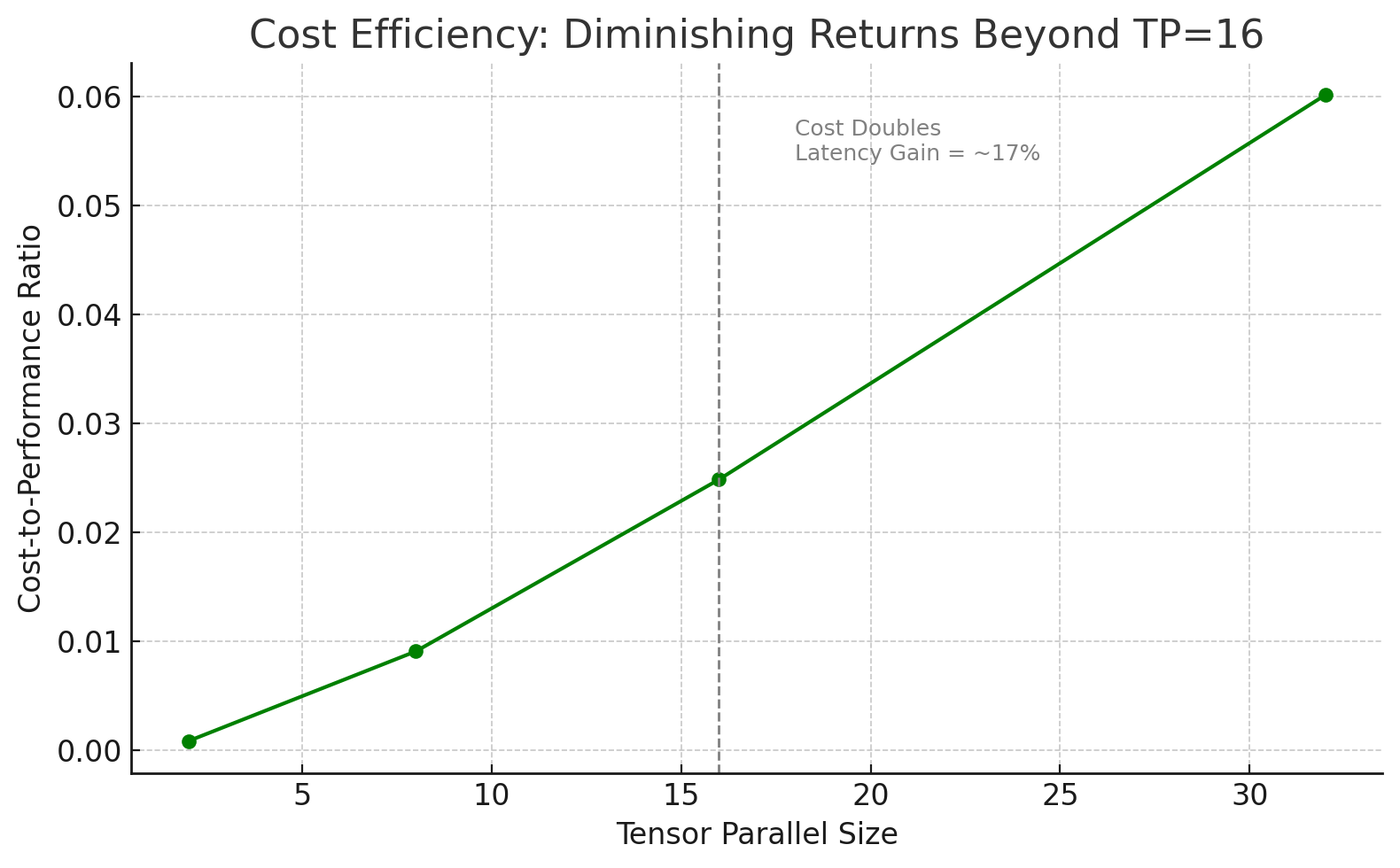
고성능을 추구하면서도 인프라 비용을 절감하고자 한다면 TP=16으로 조정하는 것을 권장합니다.
결론 및 향후 활용 가이드
이번 블로그에서는 콜드스타트 문제 해결을 위해 AWS Trainium 기반의 고성능 인프라, Neuron SDK, vLLM의 제로샷 추론과 추천 알고리즘 자동화 흐름을 소개했습니다. 단순히 모델 크기를 키우는 것이 능사가 아닌, 추천 품질, 응답 시간, 인프라 비용을 동시에 고려하는 실제 배포 전략 수립이 중요함을 입증합니다.
추천 시스템 성능을 향상시키고 싶다면 LLM과 인코더 조합의 효과적 비교를 통해 가장 효율적인 구성을 찾는 것이 좋습니다. 특히 Llama 8B와 T5-Large 조합은 퍼포먼스 측면에서 균형잡힌 선택지입니다.
아이템 메타정보가 적거나 신규 고객이 많은 서비스 환경에서는 본 방식이 가장 적합한 콜드스타트 대응 전략이 될 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
