아마존 노바 모델 벤치마킹: MT-Bench 및 Arena-Hard-Auto를 활용한 성능 평가 가이드
도입
생성형 AI의 핵심 기술인 대규모 언어 모델(LLM)은 대화형 AI, 복합 추론, 코드 생성 등 다양한 분야에서 핵심 역할을 수행하고 있습니다. 하지만 LLM의 성능을 측정하고 비교하는 데 있어 기존의 평가 지표인 퍼플렉서티(Perplexity)나 BLEU 점수는 실제 사용자 경험을 충분히 반영하지 못한다는 한계가 있습니다. 이를 극복하기 위해 최근에는 인간 중심의 평가 방식을 자동화한 ‘LLM-as-a-judge’ 프레임워크가 주목받고 있으며, 이는 보다 현실적인 배포 가이드와 성능 비교를 가능하게 합니다.
이 글에서는 Amazon Bedrock에서 제공하는 아마존 노바(Amazon Nova) 모델을 대상으로 MT-Bench와 Arena-Hard-Auto 평가 프레임워크를 적용한 결과를 자세히 다루고, 어떻게 활용할 수 있는지를 비교 분석합니다. 각 모델의 자동화 기반 성능 점수부터 지연 시간, 토큰 효율성, 비용 최적화까지 실질적인 도입을 위한 기준을 제시하며, 특히 기업 환경에서의 모델 선택 자동화 및 배포 활용에 실질적인 통찰을 제공합니다.
본문
- 아마존 노바 모델 및 Bedrock 개요
아마존 노바 시리즈는 Amazon Bedrock을 통해 배포되는 차세대 LLM 제품군입니다. Nova Micro, Lite, Pro, Premier까지 총 4종으로 구성되어 있으며, 각각 경량화된 엣지용부터 프론티어급 복잡 생성 작업까지 대응합니다. 특히 최고 성능을 자랑하는 Nova Premier는 모델 디스틸레이션을 통해 다른 Nova 모델에 지식을 전달할 수 있어, 도메인 맞춤형 고속 모델 생산에도 활용도가 높습니다.
- 평가 도구: MT-Bench 및 Arena-Hard-Auto 소개
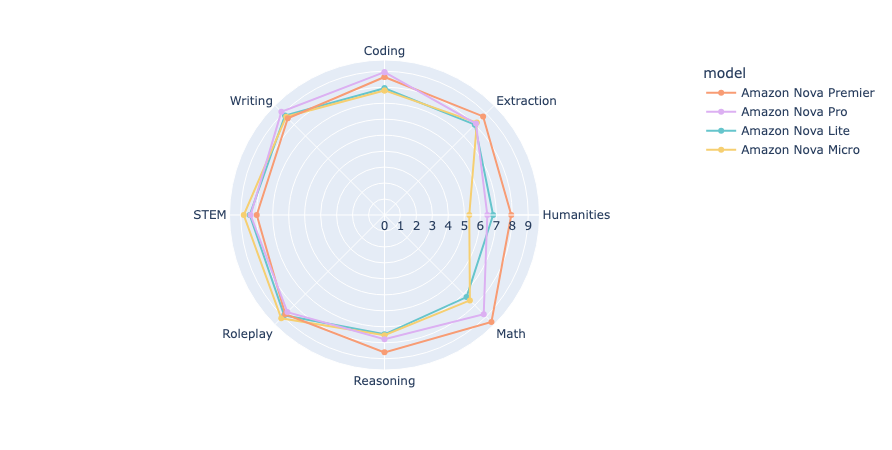
MT-Bench는 8개 주요 분야(Writing, Roleplay, Reasoning 등)의 다중 턴 질문을 기반으로 평가하는 방법으로, 싱글 응답 채점과 모델 간 비교(Pairwise 비교)를 지원합니다. 실제 질문은 사용자 요구에 맞게 커스터마이징할 수도 있어 유연성이 뛰어난 자동화 평가 프레임워크입니다.
Arena-Hard-Auto는 ChatBot Arena 데이터셋에서 추출한 고난이도 500개 질문을 기준으로 모델들을 LLM으로 직접 비교하는 방식입니다. Bradley-Terry 통계 모델을 통해 모델 간 성능 점수를 산출하며, 짧은 시간에 상대 평가 기반 순위를 도출하는 데 유용합니다.
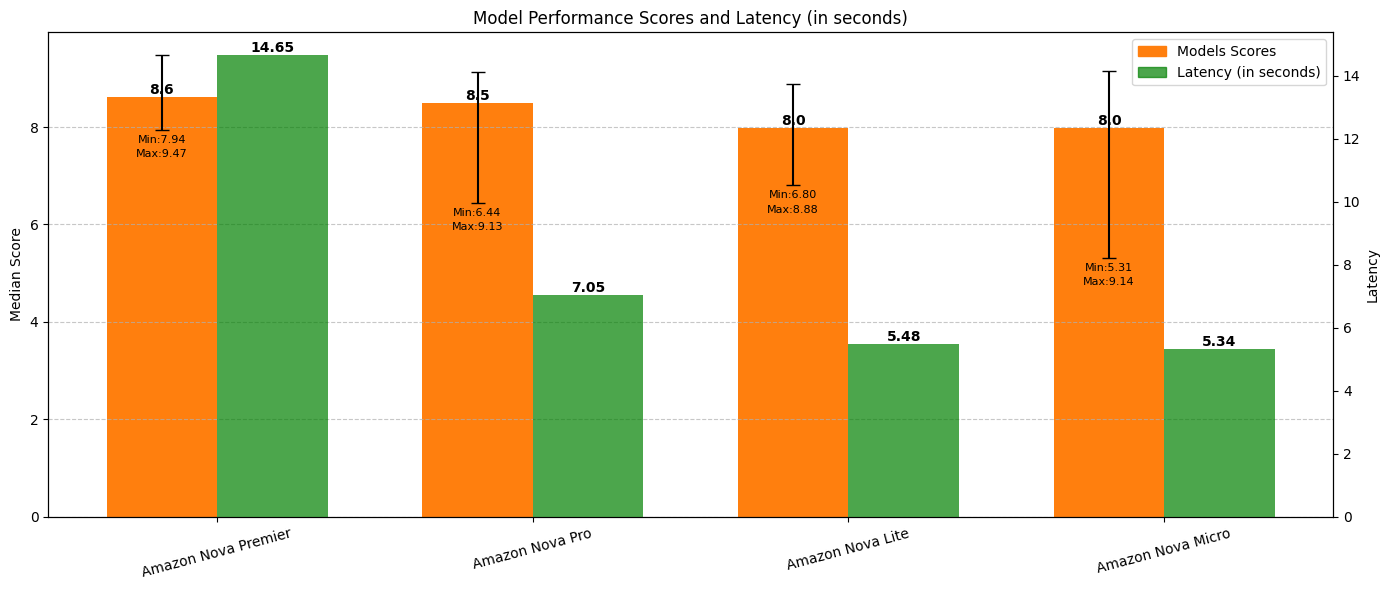
- MT-Bench로 본 아마존 노바 평가 결과
MT-Bench 싱글 응답 채점 기준, Nova Premier가 평균 점수 8.6으로 가장 뛰어난 성능을 보였습니다. Nova Pro(8.5), Lite(8.0), Micro(8.0) 순으로 뒤를 이었고, Premier 모델은 특히 최소/최대 점수 편차가 1.5로 낮아 안정적인 성능을 입증했습니다. 지연 시간 측면에서는 Nova Micro와 Lite가 평균 6초 이하의 빠른 반응속도를 보여 엣지 배포에 최적화된 선택입니다.
또한 Premier 모델은 응답 생성 시 최대 190개 토큰 적게 사용해 토큰 효율성에서도 앞섰으며, 이는 결과적으로 비용 절감과도 직결됩니다.
- Arena-Hard-Auto 결과 및 경쟁 모델 비교
Arena-Hard-Auto 기준 평가에서는 Nova Premier 점수가 8.368.72로 가장 높았고, Pro(7.728.12), Lite(6.516.98), Micro(5.686.14) 순입니다. 특히 DeepSeek-R1 모델(7.99~8.30)과 비교해도 Premier가 확실한 우위를 점했으며, 신뢰구간 분석에서도 통계적으로 우수함을 보였습니다.
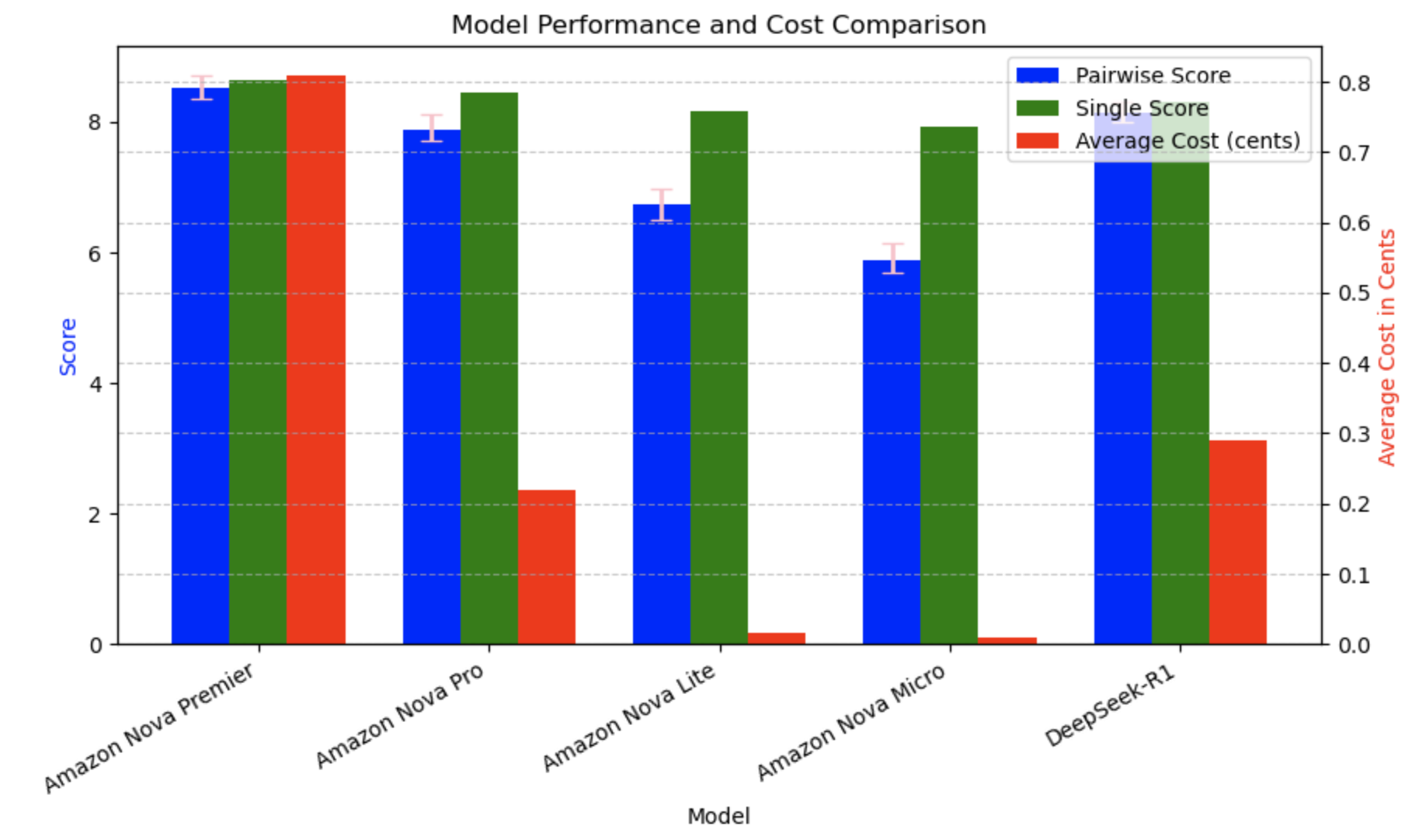
- 비용 대비 성능 분석
모델별 1,000개 입력 토큰당 비용과 평균 토큰 사용량을 기반으로 분석한 결과, Nova Micro가 Nova Premier 대비 89배 저렴하면서도 69%의 성능을 달성했고, Nova Lite는 52배 저렴하면서도 79%의 성능으로 매우 높은 비용 효율성을 보였습니다. 이처럼 Lite/Micro 모델은 생성형 AI 자동화 적용 시 운영비 절감이 중요한 환경에서 강력한 대안이 됩니다.
결론
MT-Bench와 Arena-Hard-Auto는 LLM 성능을 평가하기 위한 강력한 자동화 프레임워크이며, 단순 벤치마크 수치를 넘어 사용자 중심 평가 관점에서 모델을 분석할 수 있습니다. Amazon Nova 모델은 다양한 성능-비용 구간을 제공하며, 기업의 요구에 따라 최적의 모델 배치를 구현하는 데 유용합니다.
특히 Nova Premier는 고성능이 필수인 복합 reasoning, instruction-following, 데이터 추출 등 복잡 작업에 적합하며, Lite/Micro는 엣지 배포나 빠른 응답이 필요한 서비스에 매우 이상적입니다. 자동화된 성능 평가와 구체적인 비교를 기반으로, 사용자는 보다 신뢰성 있는 모델을 선택하고 생성형 AI 프로젝트를 성공적으로 추진할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
